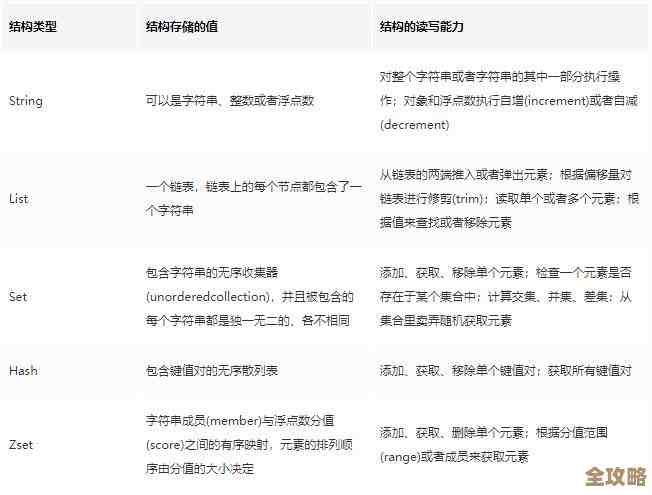
Redis集群节点崩了怎么办,快速处理思路和实操分享

前几天我们这边一个Redis集群的一个节点真就突然挂掉了,当时业务那边立马就报警了,说有些数据查不到,说实话,心里当时也是咯噔一下,但好在之前有过预案,处理起来还算有条理,我把这次快速处理的思路和实际操作过程分享一下,你看了以后万一遇到类似情况,也能有个参考,这次经历主要参考了我们公司内部运维手册和之前一位资深同事的处理记录。
第一步:别慌,先确认问题现象
看到报警,第一件事不是立马去重启,那是最忌讳的,我先登录到监控系统,比如Grafana这种看板,看看集群的整体状态,果然,有一个节点的指标,像连接数、内存使用量、QPS这些,全都掉到零了,变成一条直线了,而其他节点都是正常的波浪线,这就初步判断是单个节点的问题,不是整个集群崩盘,这算是不幸中的万幸。
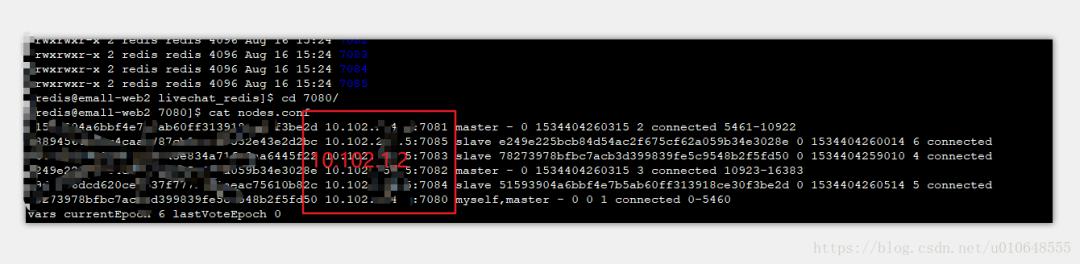
光看监控还不够,得从集群内部确认,我马上用redis-cli工具随便连接上一个还活着的集群节点,执行了一个命令:redis-cli -c -h [健康节点IP] -p [端口] cluster nodes,这个命令能列出集群里所有节点的状态,一眼就看到,那个出问题的节点,它的状态标记为了fail,也就是失败状态,而其他节点都是connected已连接,这样就从内外两方面确认了,确实是某个节点宕机了。
第二步:判断节点角色,评估影响范围
Redis集群里节点分两种,一种是主节点,负责存数据和处理读写请求;一种是从节点,主要是给主节点做备份,挂掉的角色不同,影响天差地别。
我继续看刚才那个cluster nodes命令的输出结果,在输出信息里,找到那个fail的节点,看它前面是master还是slave,这次运气比较好,挂掉的是一个从节点,这意味着,数据读写的主节点还在正常工作,所以业务上只是可能会影响到一些读请求(如果刚好有读请求被分配到这台从节点的话),但主要的写操作和大部分读操作不受影响,业务报警说部分数据查不到,很可能就是那些本该由这个从节点服务的读请求失败了。
如果挂的是主节点,那就严重多了,不过集群有个自动故障转移的机制:如果主节点挂了,它的一个从节点会自动升级成新的主节点,接管工作,这时候就要赶紧去看有没有成功触发故障转移,检查方法还是用cluster nodes命令,看原来挂掉的主节点下面的那个从节点,角色有没有从slave变成master,如果自动转移成功了,那影响也只是短暂的一小会儿中断;如果自动转移没成功,那就需要手动干预了,那情况就更紧急一些。
第三步:尝试恢复节点
确认了是从节点宕机,影响相对较小,我心里就踏实了不少,接下来就是尝试把这个宕掉的节点恢复起来。
我先登录到那台出问题的服务器上,用ps aux | grep redis命令看了一下,发现Redis进程确实已经不在了,然后赶紧看系统日志,比如/var/log/messages或者Redis自己的日志文件,用tail -f或者tail -100这样的命令看看宕机前最后报了啥错误,这次看到的错误信息是内存不足,导致Redis被系统强制杀掉了,看来是这台机器上跑的其他某个程序突然吃了太多内存,把Redis给挤爆了。
找到原因就好办了,我先清理了一下那台服务器的内存,把那个捣乱的其他进程处理了一下,然后直接使用原来的启动命令,把Redis服务重新启动了起来:redis-server /path/to/redis.conf。
第四步:检查节点状态并重新加入集群
节点进程启动后,先别急,我再用redis-cli直接连上这个刚重启的节点,执行info replication命令,看看它的复制状态,发现它启动后,处于一个孤零零的状态,还没有自动重新加回集群。
这是因为集群已经把它标记为fail了,需要手动把它加回去,我再次连接上集群中一个健康的主节点,执行集群重配命令:redis-cli -c -h [健康主节点IP] -p [端口] cluster meet [宕机节点IP] [宕机节点端口],这个命令是告诉集群:“嘿,这个节点又活了,你重新认识一下它。”
执行完cluster meet之后,我再执行cluster nodes查看,发现这个节点的状态从fail变成了connected,但角色还是master,这不对,它原本应该是个从节点,所以还需要一步,告诉它去复制谁,于是我又在这个新恢复的节点上,执行了cluster replicate [它原来主节点的ID]命令,这个节点ID在之前cluster nodes的输出里能查到。
执行完后,再查cluster nodes,好了,这个节点的角色终于变回了slave,并且开始从它的主节点全量同步数据了,这时候看监控,这个节点的网络流量和同步指标也开始有了变化。
第五步:验证和观察
等数据同步的进度追平之后(可以通过info replication命令看落后多少数据),我让业务同学配合,专门做了几次之前报错的那个查询操作,确认已经恢复正常了,在监控上看一段时间,确保这个重新加入的节点各项指标稳定,没有再次出现异常。
最后总结一下快速处理思路:
- 冷静确认:靠监控和集群命令,确定是不是真节点挂了,挂的是哪个节点。
- 判断角色:分清是主节点还是从节点,这决定了问题的严重性和处理优先级。
- 查看日志:登录故障服务器,看日志找根源,别盲目操作。
- 恢复服务:根据日志原因解决问题,重启Redis进程。
- 重新入群:通过
cluster meet和cluster replicate命令,让节点重新回归集群并开始同步数据。 - 业务验证:同步完成后,让业务验证功能,并持续观察一阵子。
整个过程核心就是:先诊断,后操作;先保业务,再修节点,特别是遇到主节点宕机时,优先确保故障转移是否成功,保证业务能继续运行,然后再去处理坏掉的那个节点,希望这个实际的例子对你有帮助。

本文由度秀梅于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/80558.html