Redis连接为什么老是慢?背后原因其实没那么简单,聊聊那些你可能忽略的细节

(引用来源:阿里云数据库团队博客、Redis官方文档、多位资深运维工程师的经验分享)
Redis连接老是慢,这个问题困扰过很多人,大家的第一反应往往是“Redis本身是不是出问题了?”,但实际情况是,绝大多数时候,问题并不在Redis服务器内部,而是出在连接的通路上,以及我们使用连接的方式上,这些细节很容易被忽略,今天我们就来仔细聊聊。
最容易被忽略的“元凶”其实是网络,Redis的性能瓶颈,十有八九首先出现在网络上。(引用来源:Redis官方文档性能章节)你想啊,Redis的内存操作速度是纳秒级别的,而一次网络往返的时间,哪怕是在同一个机房的内网,也可能达到零点几毫秒,这零点几毫秒,对于Redis内部操作来说,已经是非常漫长的时间了,如果你的应用服务器和Redis服务器不在同一个机房,甚至跨了城市,那网络延迟会飙升到几十毫秒,这时候无论你怎么优化Redis配置,整体的响应速度也快不起来,排查连接慢的第一步,永远是用 ping 命令或者类似的工具,测量一下网络的基础延迟是多少,如果基础延迟就很高,那后续的优化都是空中楼阁。

连接池的配置是个大学问,配置不当会直接导致连接缓慢甚至超时。(引用来源:多位工程师的实践总结)很多人对连接池的参数不敏感,用着默认配置,这就埋下了隐患,最大连接数”,如果设置得太小,在高并发场景下,应用线程会因为抢不到空闲连接而陷入等待,这个等待时间就会被算作“连接慢”,反过来,“最小空闲连接数”如果设置得太低,当突发流量来时,应用需要频繁地创建新连接,而建立一条新的TCP连接需要经过“三次握手”,这个过程是有开销的,在连接数瞬间暴涨时,大量时间会耗费在创建连接上,而不是执行命令上,还有“连接最大存活时间”,Redis服务器为了安全和管理,可能会关闭长时间空闲的连接,如果连接池里的连接已经失效了,但池子还不知道,应用拿到了这个“僵尸连接”去操作,就会抛出连接异常,然后重试,这个过程用户感知到的就是卡了一下。
第三个常被忽略的点是Redis自身的配置和状态。(引用来源:阿里云数据库团队博客)Redis是单线程模型的,它虽然快,但它一次只能处理一个命令,如果你的某个操作特别耗时,比如用 keys * 这种命令去匹配大量键,或者一次性获取一个非常大的value,那么这个操作就会阻塞住整个Redis服务器,期间所有其他的连接和请求都得等着,这时候你从应用侧看,就是所有的Redis操作都变慢了,如果Redis实例的内存快用满了,触发了内存淘汰策略,或者操作系统开始进行Swap(内存交换),把Redis的热点数据从内存挤到了硬盘上,那性能就会呈现断崖式下跌,因为硬盘的速度和内存完全不在一个量级。

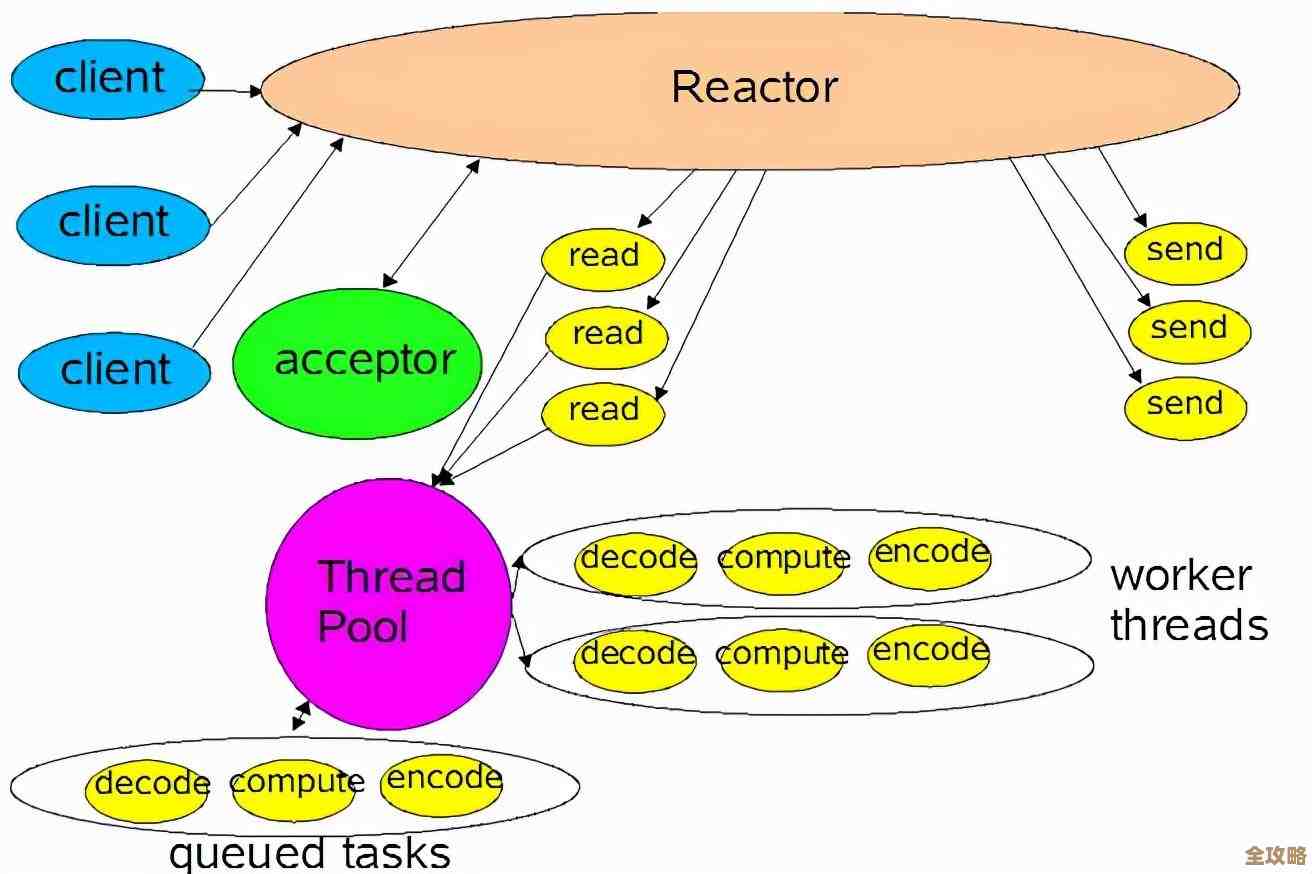
第四,客户端的用法也非常关键。(引用来源:开发者社区常见问题汇总)有些开发者为了省事,会在一个请求里向Redis发送大量的小命令,比如要获取10个用户信息,就循环10次执行 get user:1、get user:2... 这会产生10次网络往返,而更高效的做法是使用 mget 命令,一次网络往返就把10个数据都拿回来,这种频繁的网络往返造成的延迟,累积起来是非常可观的,不合理的序列化方式也会导致问题,如果value被序列化成非常大的字符串,网络传输和Redis读写的时间都会变长。
操作系统层面也有坑。(引用来源:运维工程师故障排查案例)Linux系统默认的TCP连接队列长度(somaxconn)可能偏小,在高并发连接涌入时,队列满了,新的连接就会被拒绝,导致应用连接超时,再比如,服务器的文件描述符数量限制如果太低,当连接数上去后,就无法再建立新的连接了。
当你再遇到Redis连接慢的问题时,别急着去重启Redis,不妨按照这个思路,从外到内、从网络到配置、从服务端到客户端,一层一层地排查这些容易被忽略的细节,很可能问题就迎刃而解了。
本文由芮以莲于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/80463.html