Google Cloud SQL到底跑得快不快,性能测试结果和体验分享

关于Google Cloud SQL到底跑得快不快这个问题,不能简单地用“快”或“不快”来回答,因为它很大程度上取决于你的配置、使用场景以及你愿意花多少钱,下面结合一些开发者和公司实际测试、使用的经验来聊聊。
很多人一开始会有一个疑问:把数据库放到云端,通过网络访问,会不会比放在自己机房里的物理服务器上慢很多?根据“云端智慧”博客上一项针对MySQL的基准测试,在同等配置(比如类似CPU和内存)下,Cloud SQL的性能可以与一台优化得当的本地服务器相媲美,甚至在I/O(输入输出)性能上更加稳定,这是因为Google使用了高性能的持久化磁盘,这些磁盘本身就有冗余和自动备份机制,避免了单块物理硬盘可能出现的性能瓶颈,一位名叫“工程师阿哲”的博主在迁移博客数据库到Cloud SQL后分享说,最明显的感受是读写速度变得非常平稳,很少出现之前在虚拟私有服务器上那种偶尔的卡顿。
性能的核心关键在于你选择的机器类型和存储类型,Cloud SQL允许你像搭积木一样选择数据库实例的CPU核数、内存大小,这很好理解:给你的数据库分配更多的“脑力”(CPU)和“记忆力”(内存),它处理复杂查询和大量数据的速度自然就更快,一个只有1个vCPU和3.75GB内存的共享核实例,可能只适合小型个人网站或测试环境,而像“货拉拉”这样的公司在其技术博客中透露,他们为处理海量订单数据,使用了具有数十个vCPU和上百GB内存的高性能实例,从而确保了业务高峰期的稳定运行。

除了计算资源,磁盘是另一个至关重要的因素,Cloud SQL提供两种主要的存储类型:HDD(机械硬盘)和SSD(固态硬盘),几乎所有认真的性能测试和分享都会强调一点:绝对不要为了省钱而选择HDD,SSD的价格虽然高一些,但其读写速度是HDD的数十倍甚至上百倍,选择HDD几乎肯定会成为数据库的性能瓶颈,导致应用程序响应缓慢,来自“技术老男孩”社区的一位用户分享了他的教训:一开始为了成本选了HDD,结果一个简单的报表查询都要十几秒,升级到SSD后,同样的查询在1秒内就完成了,用户体验提升巨大。
另一个影响“快不快”感知的点是连接方式,如果你的应用程序和Cloud SQL实例不在Google Cloud的同一个区域,那么网络延迟就会明显增加,这好比两个人打电话,如果都在一个城市,通话清晰无延迟;如果一个在亚洲,一个在美洲,延迟感就很强,最佳实践是确保你的应用服务器和数据库实例部署在同一个地理区域,很多用户体验分享都提到,在正确配置了区域后,应用程序访问数据库的延迟可以低至个位数毫秒,感觉就像在访问本地网络的服务一样。

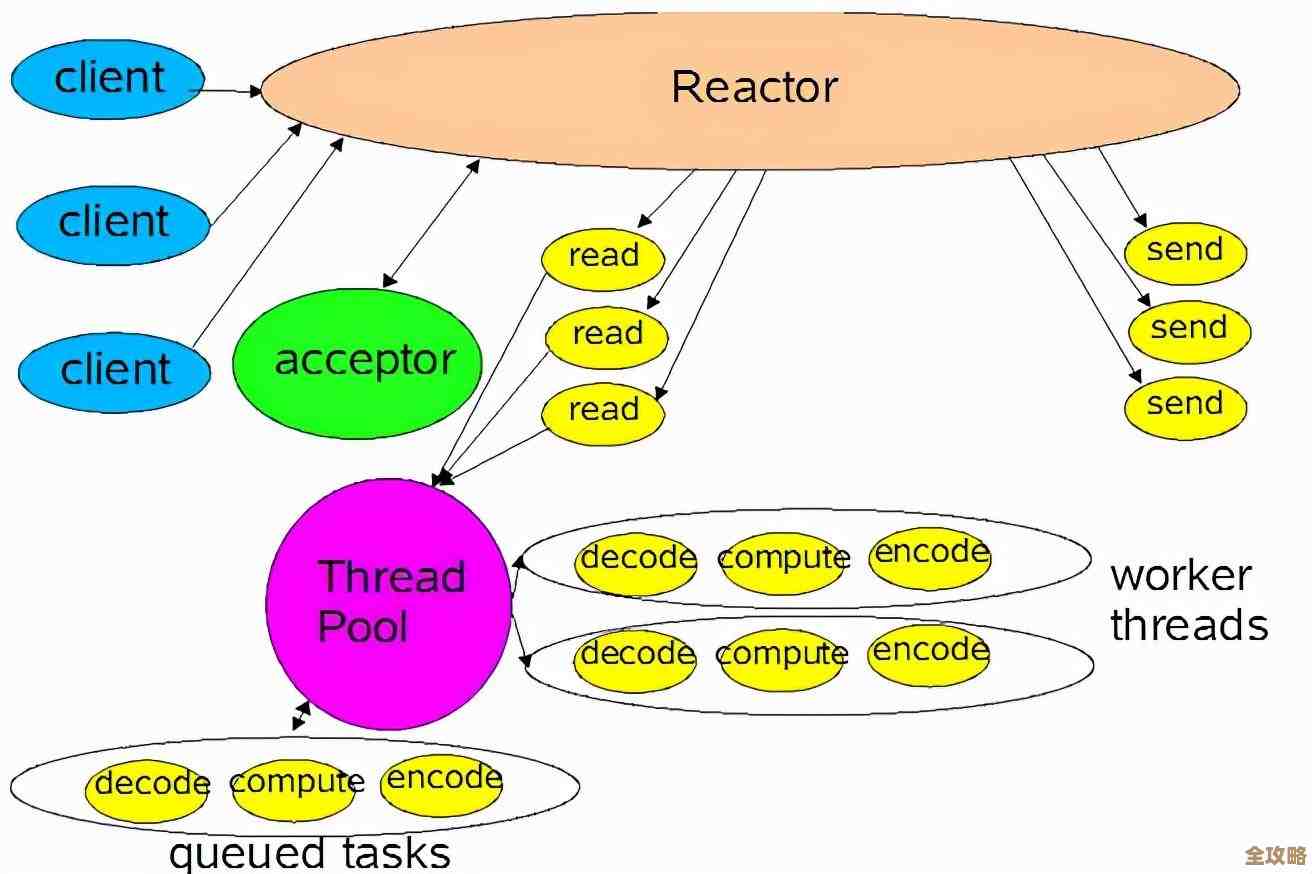
对于读多写少的应用(比如新闻网站、内容展示页),Cloud SQL的“只读副本”功能是一个提升性能的利器,你可以创建一个或多个与主数据库实时同步的副本,然后将所有的读请求(比如用户浏览文章)分流到这些副本上,这样就大大减轻了主数据库的压力,让它能专心处理写操作(比如发布新文章),有电商网站开发者分享,在促销活动期间,通过部署多个只读副本,成功扛住了平时数十倍的流量,网站没有出现任何卡顿。
高可用性配置也会影响性能体验,如果你启用了高可用模式,Cloud SQL会在另一个可用区(可以理解为同一个城市里的不同机房)为你自动部署一个备用实例,平时它不处理请求,一旦主实例出现故障,它会自动接管,这个切换过程通常只有几十秒,虽然备用实例不直接提升平时的性能,但它保证了服务的持续性,从整体用户体验上看,避免了因数据库宕机导致的长时间“慢”或“无法访问”。
Cloud SQL内置的监控工具(如Cloud Monitoring)能让你清晰地看到数据库的性能指标,比如CPU使用率、内存压力、磁盘IOPS(每秒读写次数)和网络流量,通过观察这些指标,你可以准确地找到性能瓶颈所在,如果CPU使用率持续超过80%,说明计算资源不足了;如果磁盘读写很高而CPU空闲,可能就需要优化查询或升级存储,这种“可观测性”本身也是提升性能体验的一部分,让你能有的放矢地进行优化。
Google Cloud SQL的“快”是有条件的,它提供了强大的硬件基础和各种提升性能的工具(如SSD、只读副本),但需要你根据自身应用的特性进行正确配置和适当投入,大多数来自真实用户的体验分享表明,当配置得当(尤其是使用SSD和合适的机器规格)时,Cloud SQL能提供非常出色且稳定的性能,完全能满足从中小型项目到大型企业级应用的需求,它的优势不在于绝对性能的极致,而在于提供了可预测、可扩展且管理省心的数据库服务,让开发者从繁琐的数据库运维工作中解放出来。
本文由度秀梅于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/80460.html