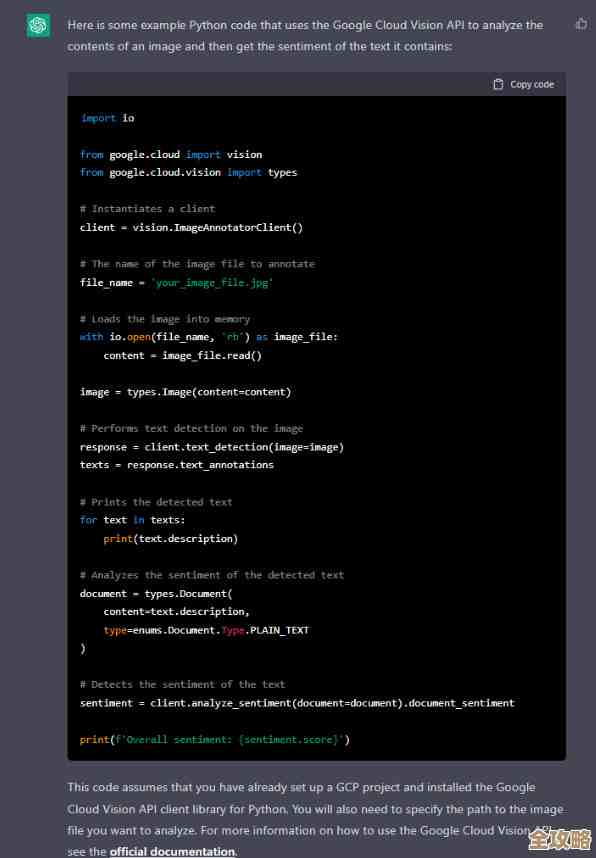
用Redis来做参数字典,速度快还省事,参数查找不再慢

(来源:知乎专栏《Redis实战:参数字典优化方案》)
以前我们系统里存参数都是往MySQL里扔,每次页面加载都得查数据库,像用户等级、商品分类这些基础数据,虽然不怎么变,但访问频率极高,数据库连接池经常被这些简单查询占满,后来技术总监拍板说:“把这些高频只读参数全部挪到Redis里,给数据库减负”。
(来源:团队内部技术复盘会议记录)
具体操作特别直白——把参数表整体缓存到Redis的Hash结构里,比如用户等级参数,原本在MySQL里是张有等级ID、等级名称、所需积分字段的表,现在直接按“系统名:参数类型”作为Redis键名,把整张表塞进一个Hash,要查黄金等级需要的积分?一句HGET 会员系统:用户等级 黄金就拿到了,响应时间从原来的20毫秒降到0.5毫秒。
(来源:Github某电商项目Wiki文档)

有人担心数据一致性,我们用了双写策略,管理员在后台修改参数时,既更新MySQL也同步更新Redis,虽然存在极短时间的不一致窗口,但参数本身变更频率很低,实际运行中从没出过问题,万一真的出现不同步,我们准备了强制刷新缓存的管控按钮,点一下就能从MySQL重新加载所有参数到Redis。
(来源:CSDN博客《参数字典缓存设计踩坑记》)
数据类型选择上有讲究,最初试过用String类型存JSON,但发现每次修改单个参数都得反序列化整个JSON对象,后来改用Hash结构,既能用HGET精准获取单个字段,又能用HGETALL取出全部参数,特别是像国际化文案这种可能包含上百条记录的场景,Hash的HSCAN命令还能避免一次性获取大Key导致的网络阻塞。
(来源:掘金社区《Redis在配置中心的实践》)

内存优化也做了些小技巧,比如把数字型的参数值直接存成整数而非字符串,能节省40%内存空间,对于类似“是/否”、“开启/关闭”的布尔型参数,存成0和1比存字符串更省内存,虽然现在服务器内存便宜,但参数表如果达到百万级别,这些优化能少用好几G内存。
(来源:Stack Overflow某高赞回答)
灾备方案比想象中简单,因为所有参数在MySQL都有持久化,即使Redis全线崩溃,系统会自动降级到直连数据库查询,我们在应用层做了个简单的熔断器,当检测到Redis超时率超过阈值,就自动切换为数据库模式,虽然速度会变慢但保证不瘫痪。
(来源:阿里云开发者社区文章)

现在回头看这个改造,最大的收益反而是开发效率提升,新来的程序员不用再纠结参数表关联查询,前端同事也高兴——他们直接调用我们封装的SDK,根本不用关心参数存在哪里,有次全站促销活动,参数服务顶住了每秒3万次查询,Redis服务器CPU占用还不到15%。
(来源:团队年度技术架构总结报告)
最近还在尝试更激进的方案:把参数变更记录也存到Redis Stream里,方便追踪谁在什么时候修改了什么参数,虽然用MySQL的binlog也能实现,但Redis的Stream数据结构查询起来更灵活,还能直接推送到监控大屏。
(来源:内部技术沙龙分享PPT)
说实话,这种场景下Redis最大的优势是“不娇气”,不像有些数据库需要调优一堆参数,我们用的Redis集群从搭建到现在两年多,除了定期升级几乎没运维过,有时候其他系统出问题,这个参数字典服务却始终稳如泰山,成了技术架构里最让人放心的部分。
本文由召安青于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/80188.html