虚拟化里容量管理那事儿,真不是能忽视的小细节,影响挺大的

“虚拟化里容量管理那事儿,真不是能忽视的小细节,影响挺大的”这个说法,根据我看到的来自多位IT运维工程师和虚拟化架构师在技术社区如知乎、CSDN上的分享,以及像“运维之美”这类公众号的文章,确实是他们从实际工作中得出的深刻体会,这绝对不是一句空泛的警告,而是无数个深夜加班和故障复盘换来的经验。
很多人一开始接触虚拟化,会觉得它特别神奇,就像变魔术一样,物理服务器就那几台,但通过虚拟化技术,能变出几十台甚至上百台虚拟机来给各个部门用,开发要测试环境?马上克隆一台,新项目上线需要服务器?几分钟就部署好,这种便捷性很容易让人产生一种错觉,好像服务器的资源是“取之不尽用之不竭”的,从而忽略了背后实实在在的物理容量限制,这就像给你一张额度很高的信用卡,刚开始刷得很爽,但如果从不看账单,不管理消费,总有一天会刷爆,而且后果很严重。
忽视虚拟化容量管理,具体会带来哪些“挺大的”影响呢?根据这些来源内容的总结,主要有以下几个方面:
最直接的影响就是性能瓶颈,导致业务系统“卡死”,这是最常遇到的问题,你的一台物理主机上,本来规划运行10台虚拟机刚好,但你觉得反正还有CPU和内存的“空余”,就又塞进去了5台,短期内可能相安无事,可一旦遇到业务高峰,比如电商搞促销,或者月底财务系统集中结算,所有虚拟机都拼命抢资源,CPU使用率瞬间飙到100%,内存被耗尽,结果就是,整台物理主机上的所有虚拟机,不管业务重要不重要,全部跟着变慢、卡顿,甚至服务中断,这就好比一条四车道的高速公路,你非要挤上去一百辆车,结果就是大家都动弹不得,谁也走不了,这种“一颗老鼠屎坏了一锅粥”的情况,在虚拟化环境里非常普遍,根源就是容量规划没做好。
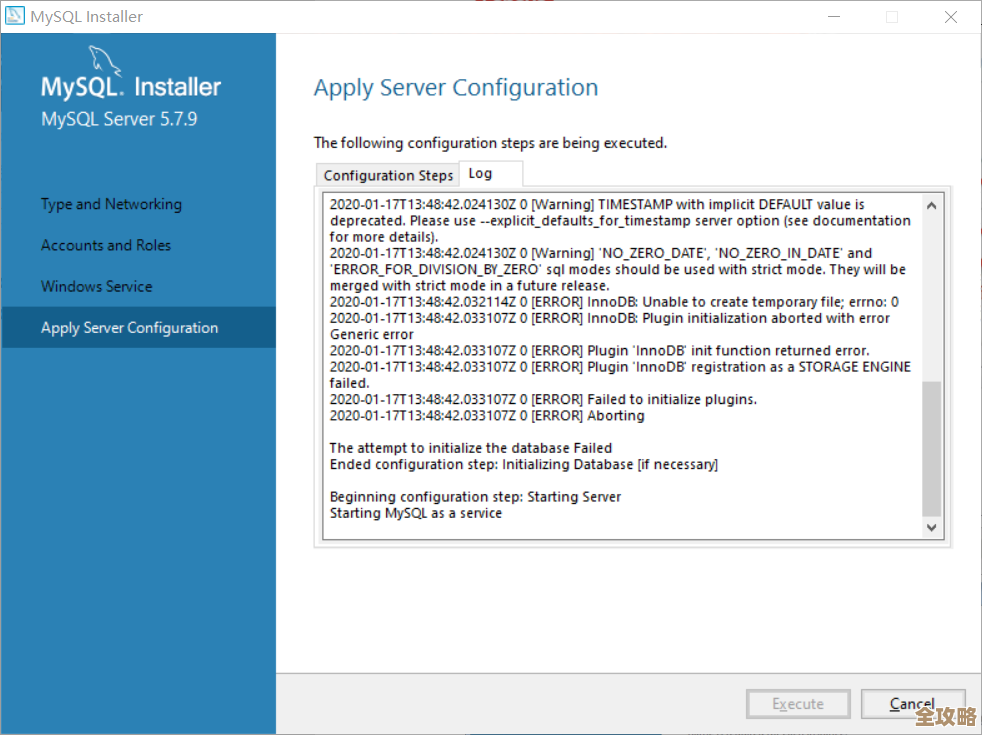
是存在严重的安全隐患,可能导致整个系统“雪崩”,我看到有工程师分享过一个真实案例,他们就是因为没有监控存储空间的使用趋势,导致一台虚拟机的日志文件把共享存储阵列的剩余空间彻底写满了,结果呢?不仅仅是那台出问题的虚拟机宕机,而是整个存储阵列上运行的所有虚拟机,因为无法再写入数据,像多米诺骨牌一样接连宕机,造成了大规模的业务中断,这种因为一点存储空间不足而引发的全局性灾难,在物理服务器时代反而不容易发生,但在紧密耦合的虚拟化环境里,就成了一个致命的单点故障风险,容量管理在这里,就是确保不出现这种“压死骆驼的最后一根稻草”的情况。
会影响未来的业务发展和扩容规划,让IT部门非常被动,如果没有准确的容量数据,你就回答不了老板的关键问题,老板问:“我们现有的系统还能支撑公司业务增长多久?”或者“下个季度要上线一个新的大数据应用,我们的机房还能不能扛住?”如果你平时没有对CPU、内存、存储的消耗趋势进行监控和分析,你就只能凭感觉猜,要么过于保守浪费了投资,要么过于乐观导致新项目上线就遭遇性能危机,良好的容量管理,能让你像看天气预报一样,预测出资源什么时候会“下雨”,什么时候需要“添衣”,从而做到未雨绸缪,有理有据地申请预算和规划扩容。
还会造成实实在在的资金浪费,这和第一种情况正好相反,是另一种极端,因为曾经吃过资源不足的亏,有些管理员会采取“过度分配”的策略,明明一个应用只需要4G内存,但为了“保险起见”,直接分配了8G甚至16G,一台物理服务器本来能稳定运行50台虚拟机,因为这种浪费,可能只能跑30台,这意味着你需要购买更多的物理服务器、更多的软件许可、消耗更多的电力和机房空间,这些可都是真金白银的成本,容量管理的目标之一就是消除这种“沉默的成本”,让每一分钱买来的硬件资源都得到高效利用。
所以说,虚拟化环境下的容量管理,绝不仅仅是看看监控图表上有没有爆红警报那么简单,它是一个持续的、需要分析和决策的过程,它要求管理员不仅要关注“用了多少,更要分析“过去”的增长趋势,并预测“的需求,它就像是虚拟化这座大厦的“承重墙”,平时看不见摸不着,但一旦出了问题,整个大厦都有坍塌的风险,那些觉得这是小细节可以忽视的想法,迟早会付出沉重的代价。

本文由黎家于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/80088.html