Redis里怎么快速遍历那些已经存在的数据,避免重复和遗漏的技巧分享

关于在Redis里快速且不重不漏地遍历所有数据,最核心也是最常用的方法就是使用SCAN命令族,这个方法主要是为了解决直接使用KEYS命令会带来的严重问题。
为什么不能用KEYS命令?
根据Redis官方文档(antirez/Redis)中的说明,KEYS *这个命令虽然简单直观,能一次性返回所有匹配的键,但它有一个致命的缺点:它会阻塞Redis服务器,Redis是单线程处理命令的,当你的数据库中有数百万甚至更多键时,执行KEYS *会让服务器花很长时间来遍历整个键空间,期间无法处理任何其他读写请求,这会导致服务暂时不可用,对生产环境来说是灾难性的,在任何正式场景下,都严禁使用KEYS命令来遍历数据。
SCAN命令的原理和优势
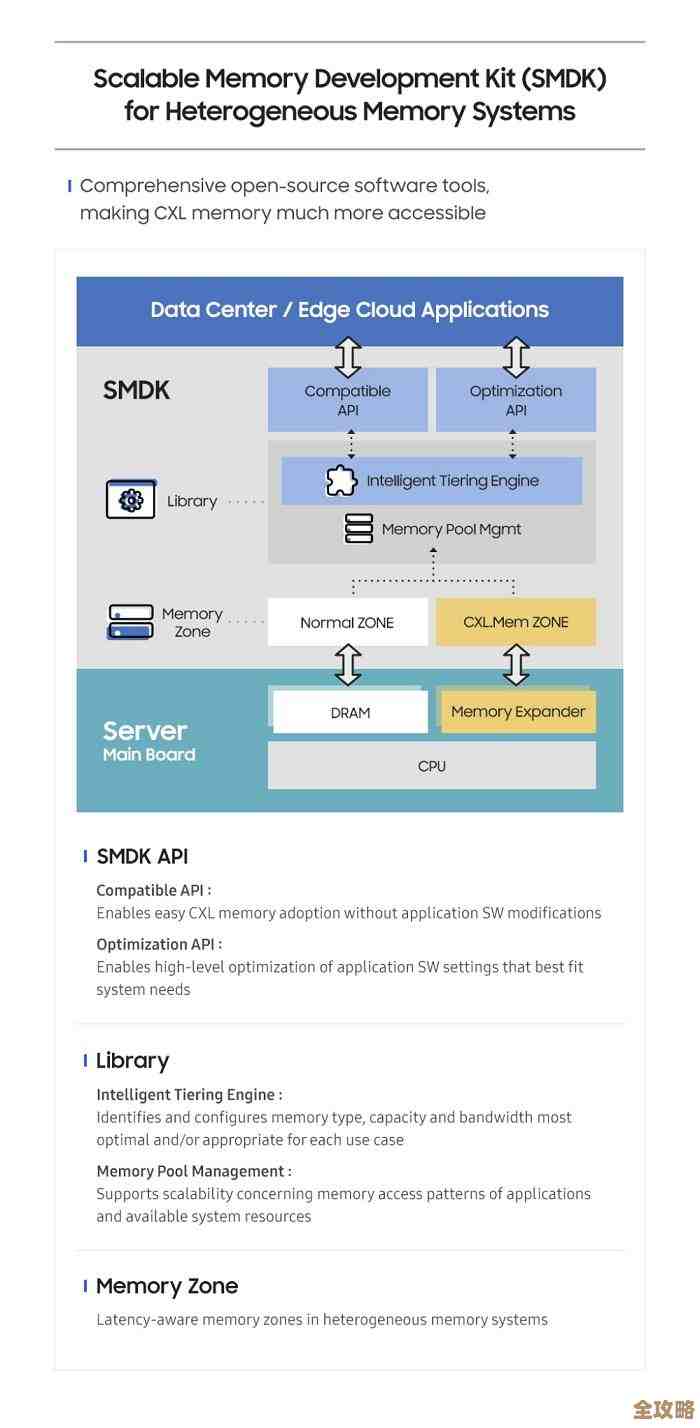
SCAN命令是Redis为了解决全量遍历问题而设计的迭代式命令,它的核心思想是“分批次”遍历,每次只返回一小部分键和一个新的游标(cursor),客户端拿到这个游标后,在下次调用时将其传入,SCAN命令会从游标指示的位置继续往后遍历,这样就把一次性的、耗时的全量遍历,拆分成多个快速的、非阻塞的小操作。
它的优势非常明显:
- 非阻塞:每次
SCAN执行的时间复杂度是O(1),对服务器性能影响极小,不会导致服务卡顿。 - 可中断:遍历过程可以随时停止,下次可以从上次的游标继续,不需要从头再来。
- 适用大规模数据:无论数据量多大,都可以通过多次迭代平稳地完成遍历。
如何使用SCAN命令
基本的使用方法是循环调用SCAN命令,第一次调用时,将游标设置为0,Redis会返回两个结果:一个是下一次迭代需要用的新游标,另一个是本次扫描到的键列表,你用返回的新游标作为下一次SCAN的输入参数,当Redis返回的游标再次为0时,就意味着整个遍历完成了。
这里有一个重要的点需要注意:SCAN命令在整个遍历过程中,可能会返回重复的键,也可能会有少量的键被遗漏,这是为了实现非阻塞而做的权衡,Redis的文档(Redis.io commands/scan)明确指出了这一点,它不保证完整的、恰好一次的遍历,但保证每个元素最终至少会被返回一次,这意味着你的客户端程序需要有处理重复数据的能力(比如将遍历到的键放入一个Set中去重),但通常不会遗漏。
SCAN命令的变体
Redis为不同的数据类型提供了对应的SCAN命令,让你能更精确地遍历:
SSCAN:用于遍历Set类型中的所有元素。HSCAN:用于遍历Hash类型中的所有字段和值。ZSCAN:用于遍历Sorted Set类型中的所有成员和分值。
当你知道要遍历的目标是一个特定的集合、哈希或有序集合时,使用这些特定命令效率更高,因为它们直接操作目标数据结构,而不是先通过键再获取值。
提升遍历效率的其他技巧
除了正确使用SCAN命令族,还有一些辅助技巧可以帮助你更快地完成工作或减少对服务的影响:
-
指定匹配模式:和
KEYS命令一样,SCAN也支持使用通配符模式来匹配键名,你可以在命令中加上MATCH <pattern>参数,例如SCAN 0 MATCH user:*,这样就只遍历以user:开头的键,这可以大大减少需要扫描和返回的数据量。 -
控制返回数量:你可以使用
COUNT参数来提示Redis每次迭代大致返回多少个元素,默认的COUNT值是10,但在实际使用中,尤其是在数据量大的情况下,适当调大这个值(比如1000)可以减少网络往返次数,提高整体遍历效率,但要注意,COUNT只是一个提示,Redis返回的数量可能比COUNT多也可能少。 -
选择合适的时间:对于数据量极其庞大的情况,即使
SCAN是非阻塞的,整个遍历过程也会消耗一定的服务器CPU和网络带宽,如果业务允许,尽量将全量遍历操作安排在业务低峰期(比如深夜)进行,避免对线上正常业务造成潜在影响。 -
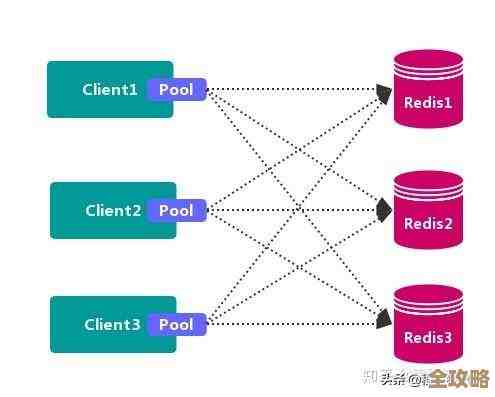
利用数据分片(如果适用):如果你的Redis使用了集群模式,数据是分布在不同节点上的,在这种情况下,你需要在每个主节点上分别执行
SCAN遍历,然后将结果汇总,一些Redis客户端库提供了相应的集群支持来简化这个操作。
在Redis中快速、安全、不重不漏地遍历数据的黄金法则就是:坚决不用KEYS,始终使用SCAN命令族进行迭代式遍历,并在客户端处理好可能出现的重复键。 结合MATCH和COUNT参数,你就能高效地完成大部分全量数据遍历的需求,这个方法经过了大规模的实践检验,是Redis官方推荐的标准做法。

本文由盘雅霜于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/79918.html