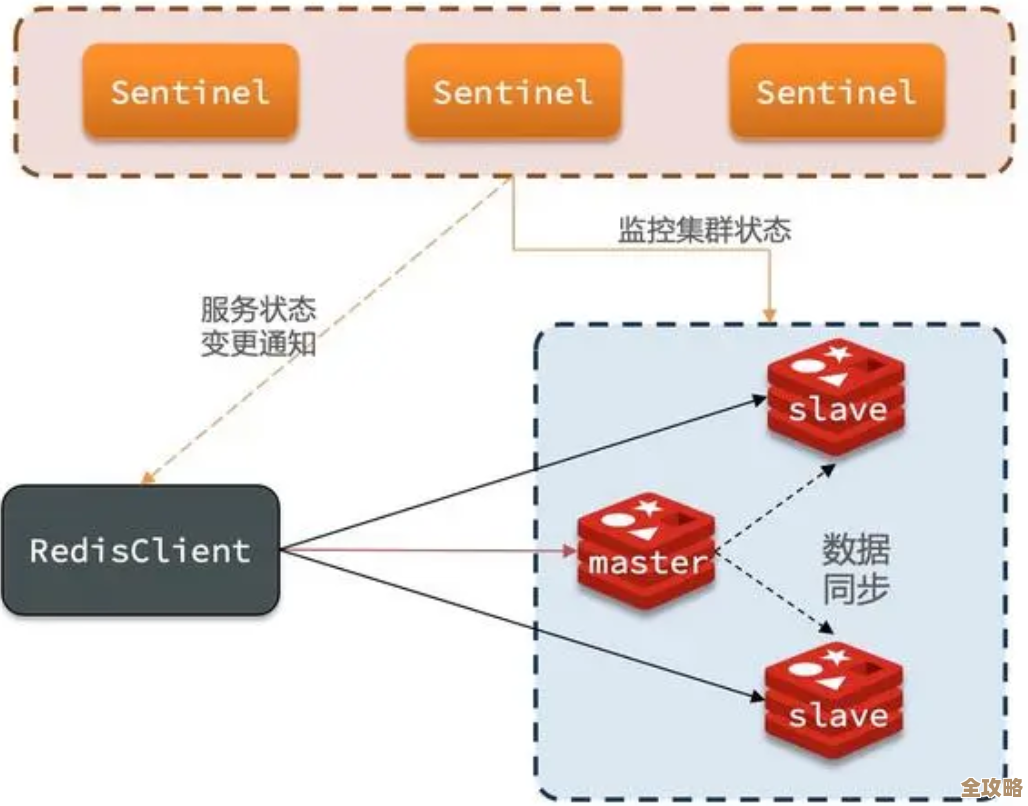
Redis里跳跃链表那点儿简单又巧妙的设计,真是让人忍不住想多说几句

说到Redis里的跳跃链表,这玩意儿的设计确实有点意思,它不像红黑树那样,规则一大堆,看着就头大,跳跃链表用一种“简单粗暴”又充满智慧的方式,解决了有序链表查找太慢的问题,你看完可能会觉得,“哎,这办法我怎么没想到?”
想象一下,你有一个普普通通的有序链表,就像一列排好队的火车车厢,一个接一个,你想找中间某个车厢,只能从头开始,一节一节往后找,效率很低,是O(N)的时间复杂度,Redis里的有序集合(zset)要是用这种链表,数据量一大,速度就慢得没法用了。
那怎么办呢?跳跃链表的想法很接地气:我们给这列火车加几层“快车道”或者叫“索引”不就行了?就像你在一栋很高的楼里,既有每层停的慢速电梯,也有只停靠中间某几层的快速电梯,如果你想从1楼到10楼,直接坐快梯到8楼,再走两层,肯定比慢梯一层层停快多了。
具体到跳跃链表里(这个设计主要是William Pugh提出的,来源:William Pugh的论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》),一个节点不只是有指向下一个节点的指针,它可能有好几层指针,最底层(L0)就是那个原始的有序链表,包含了所有的节点,然后往上有一层(L1),这一层可能只包含一部分节点,作为L0的“快车道”,再往上(L2),节点更少,是更快的“快车道”,以此类推。

一个新节点进来,它应该有多少层呢?这里就是Redis实现里一个非常巧妙又简单的地方了:用概率来决定(来源:Redis源码中的zslRandomLevel函数),它不像有些数据结构需要复杂的平衡操作,Redis让每个新节点至少有1层(也就是肯定在最低层链表里),它就像抛硬币一样,随机决定这个节点能不能往上“晋升”一层,假设硬币正面是成功,概率是50%(Redis里实际用的是1/4的概率,但原理一样),如果正面,它就获得第2层;然后再抛一次,如果又是正面,就获得第3层……一直抛到出现反面为止。
这个方法太妙了,它避免了像平衡树那样严格的、耗时的旋转操作,插入新节点非常快,只需要调整相邻的指针就行了,这种随机性恰恰保证了整个跳跃链表在概率上是平衡的,不会出现一边倒的极端情况,高层节点就像高速公路的入口,虽然少,但分布大致均匀,能有效地把搜索范围快速缩小。

查找的过程也就很直观了:从最高层的链表头开始,沿着“快车道”往前冲,如果下一个节点的值比目标值小,就继续在这一层往前走,如果下一个节点的值比目标值大了,说明冲过头了,那就“下高速”,降到下一层慢一点的车道继续找,这样一层一层下降,直到最底层找到目标节点,这个过程平均时间复杂度是O(log N),效率很高。
删除操作也类似,先找到这个节点在所有层中的位置,然后把指向它的指针直接“掰”到指向它后面的节点就行了,不需要移动数据。
Redis选择跳跃链表来实现有序集合,不是没有道理的(来源:Redis官方文档对数据结构的说明),它达到了和平衡树相近的查询效率,但实现起来简单得多,代码更易读、易调试,对于内存数据库来说,简单往往意味着更少出错的可能和更高的稳定性,因为它的层次结构,进行范围查找(比如zrange命令)也特别方便,直接在底层链表上遍历就行,比在平衡树上做中序遍历要直观和高效。
Redis里的跳跃链表,用一个“加索引”的朴素想法,加上“抛硬币”的随机策略,四两拨千斤地解决了有序链表的性能瓶颈,这种在简单中蕴含的巧妙,这种用概率换来效率和实现简便性的权衡,确实让人忍不住想为设计者点个赞,多聊上几句,它告诉我们,有时候最优美的解决方案,并不总是最复杂的那一个。
本文由歧云亭于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/79646.html