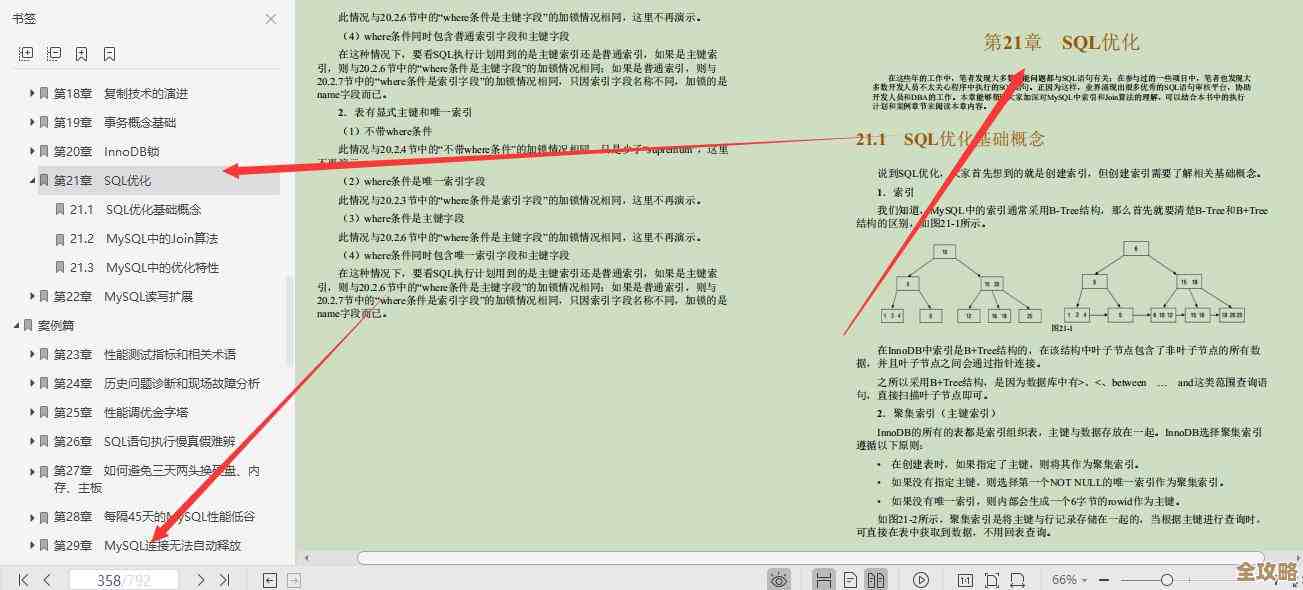
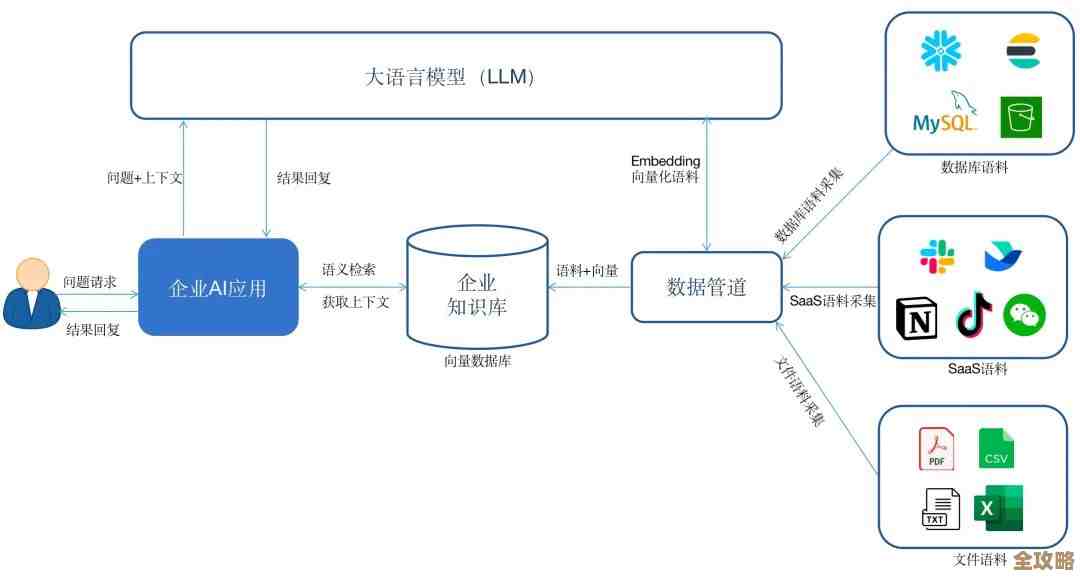
Redis里那个LFU算法,感觉给缓存优化开了新路子,挺有意思的想法

说到Redis里的LFU算法,确实像给缓存优化开了个新路子,想法挺有意思的,咱们得先明白缓存是干嘛的,它就像是电脑或者服务器里的一个“临时小仓库”,把一些经常要用到的数据放在这里,下次需要的时候就不用费劲地去大仓库(比如硬盘上的数据库)里翻了,直接从这个小仓库拿,速度飞快,但这个小仓库容量有限,不可能啥都往里塞,所以就得有个规矩,决定当仓库满了之后,哪些东西可以留下来,哪些东西得被请出去给新来的腾地方,这个规矩就是缓存淘汰策略。
Redis本身提供了好几种策略,比如最常用的LRU,也就是“最近最少使用”,这个LRU的想法很直观:它觉得,最近被用过的数据,大概率很快又会被用到;反过来,很久都没碰过的数据,估计以后也用得少,所以当空间不足时,它就把那个最长时间没被访问的数据淘汰掉,这听起来很合理,对吧?就像我们整理书桌,最近常看的书放在手边,好久没翻的书可能就先收进箱子里。
LRU有个小问题,它有点“短视”,它只关心数据“最近一次”是什么时候被访问的,而不关心它“被访问了多少次”,这就可能出情况,举个例子:想象一下你的缓存空间只能放3条数据,一开始,数据A被频繁访问了100次,然后数据B访问了1次,数据C也访问了1次,这时候,来了一个全新的、但可能只会被访问一次的数据D,按照LRU的逻辑,它会去看谁“最不被宠幸,假设在B和C被访问之后,A再也没有被访问过(因为它已经完成了它的热门使命),那么A反而成了“最近最少使用”的,会被淘汰掉!这显然不太划算,A明明是个大热门,只是暂时休息了一下,结果就被无情地抛弃了,反而那两个只来过一次的B和C可能留了下来,这种情况叫做“缓存污染”,一个过去的热点数据轻易地被新来的、可能只是偶然出现的数据挤掉了。

这时候,Redis里的LFU算法就登场了,它的想法确实有点新意,LFU的全称是“最不经常使用”,它不看重数据“有多久没来”,而是看重数据“来的频率高不高”,它的核心思想是:访问次数越多的数据,说明它越受欢迎,将来再次被访问的可能性也越大,所以应该优先保留。
那Redis是怎么实现LFU的呢?它并不是简单粗暴地给每个数据挂一个计数器,访问一次就加一,如果真那么做,又会遇到新问题:比如某个数据在开始时被疯狂访问,计数器变得非常大,之后即使它已经过气没人用了,但因为它的“历史积分”太高,也会一直霸占着缓存空间,新的热点数据进不来,这就像是个过气的明星凭着以前的知名度一直占着资源。

Redis的开发者们想了个巧妙的办法来解决这个问题,他们给LFU加了一个“衰减”机制,或者说让计数器能“慢慢忘记”过去,Redis使用的是一种概率性的计数器,它并不是每次访问都一定会加一,而是有一定几率增加,这个几率还会随着时间动态调整,更重要的是,Redis会定期地(或者在某些操作触发时)对计数器进行衰减,比如让所有计数器都减少一点,或者按比例缩小,这样,如果一个数据持续被访问,它的计数器就能维持在一个较高的水平;但如果一个数据过气了,没人访问了,它的计数器就会随着时间推移慢慢降下来,从而给新热点让位,这就好比不仅看一个明星的总票房,还会看他的“近期热度”,如果很久没有新作品、没曝光度,他的影响力自然就会下降。
这种设计巧妙地平衡了“历史频率”和“近期热度”,既避免了LRU那种因为偶尔一次访问就保住一个无用数据的情况(LFU更看重长期表现),也防止了早期热点数据永远赖着不走的问题(通过计数器衰减),它使得缓存能够更智能地识别出真正持久的热点,而不是短暂的波动。
说Redis的LFU算法给缓存优化开了新路子,一点也不为过,它没有停留在“最近使用”这个简单的维度上,而是引入了“访问频率”和“时间衰减”这两个更复杂的因素,让缓存淘汰策略变得更加精细和智能,这对于那些访问模式比较稳定、有明显热点数据的应用场景来说(比如新闻网站的热门文章、电商网站的热销商品),效果会比传统的LRU更好,能显著提高缓存的命中率,让这个小仓库发挥出更大的价值,它体现了一种思路的转变:从关注“什么时候来的”到关注“来了多少次”以及“最近还来不来”,这种思想的深化确实很有意思。 基于对Redis官方文档及相关技术社区如Redis Labs博客、Stack Overflow上关于LFU实现的讨论等资料的理解和整合。)
本文由钊智敏于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/79128.html