ORA-00039报错怎么破?周期性动作出错远程修复经验分享

ORA-00039这个错误,说白了就是Oracle数据库在尝试做某个“大动作”的时候,发现它需要的一些关键信息(具体来说是“库缓存对象”)被别的会话给锁住了,而且等了一段时间(默认是1秒)还没等到,它就不耐烦了,抛出这个错误告诉你“我拿不到需要的锁,干不了活了”,这个错误通常不会单独出现,它会伴随着另一个更详细的错误,比如ORA-04021,告诉你具体是哪个对象(比如一个存储过程、一个表)被锁住了,导致操作超时。
这个错误的麻烦之处在于,它常常发生在一些周期性自动运行的任务里,比如每天凌晨的批量数据处理作业、定期的统计信息收集任务,或者是由应用程序触发的复杂计算流程,因为这些任务是定时自动跑的,你在白天正常工作时间里可能根本遇不到,等发现的时候往往已经是第二天早上看到一堆报错日志了,问题已经发生,影响了业务,更头疼的是,它可能不是每次都发生,具有偶然性,这就给排查带来了很大困难。
根据一些DBA(数据库管理员)在技术社区如ITPUB、CSDN以及Oracle官方支持文档中的讨论和经验分享,处理ORA-00039的思路可以总结为“先救火,再防火”。
第一步:紧急处理(救火)
当你收到告警,发现作业因为ORA-00039失败时,首要任务是尽快让这个作业能继续跑下去,恢复业务。

- 找到“元凶”: 最关键的一步是查看详细的错误日志,ORA-00039会搭配一个类似“ORA-04021: timeout occurred while waiting to lock object”的信息,后面会指出是哪个对象(比如PROCEDURE "SCOTT"."MY_JOB_PROC")被锁住了,把这个对象名记下来。
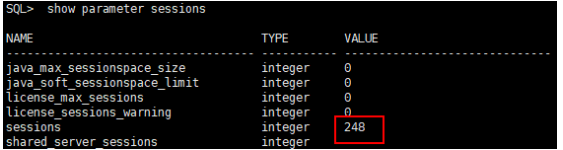
- 查询锁争用情况: 立刻连接到数据库,查询当前的锁信息,常用的SQL是查询
V$LOCK和DBA_BLOCKERS等视图,可以执行一个查询,看看当前有哪些会话正在持有锁,特别是排他锁(Exclusive Lock),以及哪些会话在等待,目标是找出那个一直占着茅坑不拉屎的会话(Blocking Session)。 - 谨慎杀死阻塞会话: 一旦定位到那个阻塞其他会话的源头,并且确认这个会话确实是一个“僵死”的或者非关键的业务会话(这一点非常重要,务必确认杀死它不会导致数据丢失或业务中断),就可以使用
ALTER SYSTEM KILL SESSION 'SID, SERIAL#';命令来强制结束这个会话,其中SID和SERIAL#是从上一步的查询中得到的,会话被杀掉后,它持有的锁会被释放,之前被卡住的周期性任务通常就能自动继续执行了。 - 手动重跑作业: 如果杀死阻塞会话后,作业没有自动继续,你可能需要手动重新触发一次这个失败的作业。
第二步:根源分析与长效预防(防火)
救火只是临时措施,如果不找到根源,同样的问题很可能明天、后天还会再次出现。
-
分析锁争用的原因: 为什么那个对象会被长时间锁住?这才是问题的核心,常见的原因有:

- 代码缺陷: 这是最常见的原因,在存储过程或应用程序代码中,有一个事务开始后,由于逻辑错误(像死循环、条件判断分支遗漏了提交或回滚)、网络异常导致连接非正常中断,使得事务一直没有被提交或回滚,导致锁无法释放。
- DDL操作: 在业务高峰期或者批量任务运行期间,有开发或运维人员执行了表结构修改(如ALTER TABLE)、编译存储过程(ALTER PROCEDURE)等DDL语句,DDL语句会获取高级别的锁,很容易与正在运行的事务冲突。
- 长时间运行的事务: 某些报表查询或数据分析任务没有设置合适的超时时间,或者本身处理的数据量巨大,运行时间过长,长时间持有锁。
- 资源竞争: 在系统负载极高的时段,多个任务同时竞争同一个热点资源,增加了锁等待超时的概率。
-
针对性地进行优化:
- 审查和优化代码: 这是治本之策,仔细检查失败作业相关的存储过程、SQL语句,以及那个被锁住的对象相关的代码,确保事务的边界清晰,在异常处理分支中一定要有ROLLBACK;避免在循环内提交事务(如果数据量大会影响性能),但要确保事务不会大到包含整个作业;对于查询语句,考虑使用
SELECT ... FOR UPDATE NOWAIT来避免等待。 - 规范操作流程: 建立严格的变更管理制度,禁止在已知的批量任务窗口期执行DDL操作,将DDL操作安排在维护窗口进行。
- 调整任务调度: 如果发现是多个周期性任务之间存在资源竞争,可以尝试调整它们的调度时间,让它们错峰运行,避免同时访问相同的热点表。
- 增加超时设置: 对于应用程序中的数据库操作,可以设置合理的SQL执行超时时间,虽然ORA-00039是Oracle内部的超时,但应用层超时可以防止请求无限期等待,便于管理和告警,在某些极端情况下,如果确认等待是必要的,甚至可以尝试修改
_KGL_TIMEOUT这个隐藏参数来延长Oracle内部的锁超时时间,但强烈不建议非资深DBA这样做,因为这可能掩盖更深层次的问题并导致全局性能下降。 - 加强监控: 部署数据库监控工具,对长时间的锁等待、长时间运行的事务设置告警,这样可以在问题发生的几分钟内就收到通知,而不是等到几个小时后作业失败才发现,实现主动干预。
- 审查和优化代码: 这是治本之策,仔细检查失败作业相关的存储过程、SQL语句,以及那个被锁住的对象相关的代码,确保事务的边界清晰,在异常处理分支中一定要有ROLLBACK;避免在循环内提交事务(如果数据量大会影响性能),但要确保事务不会大到包含整个作业;对于查询语句,考虑使用
远程修复的经验之谈
对于需要远程处理的情况,除了上述步骤,还有一些额外的经验:
- 日志就是眼睛: 远程无法直接感受数据库状态,因此必须依靠详细的日志文件(alert.log、trace文件)、作业执行日志和历史监控图表来判断问题。
- 工具要顺手: 确保有稳定、高效的远程连接工具(如SSH、远程桌面),以及好用的数据库客户端(如SQL Developer、PL/SQL Developer),能快速执行诊断SQL。
- 沟通很重要: 在决定杀死会话前,如果可能,尽量通过其他渠道(如公司内部通讯软件)联系可能受影响的用户或系统负责人,告知他们即将进行的操作,避免误杀关键业务会话引发二次故障。
- 记录复盘: 每次处理完这类问题,都要做好记录,包括出错时间、现象、根本原因、处理步骤和后续优化措施,这不仅能积累经验,当下次类似问题再出现时能更快响应,也是推动代码和架构优化的有力依据。
解决ORA-00039报错,特别是应对周期性任务中的出现,是一个从应急处理到根源治理的完整过程,关键在于不能只满足于每次的手动解锁,而是要深入挖掘背后的代码逻辑或运维流程问题,并通过优化和监控来最终杜绝它的发生。
本文由度秀梅于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/78583.html