面说怎么用Redis缓存提升系统性能,缓存那块儿的事儿要抓紧优化才行

根据常见的系统架构优化实践和Redis官方文档的核心思想整理)
你提到“缓存那块儿的事儿要抓紧优化才行”,这说明你们已经意识到了系统可能存在性能瓶颈,而缓存确实是解决这个问题的利器,下面就直接说怎么用Redis来办这个事。
搞清楚为什么要用缓存?
想象一下,你家厨房的调料架,每次炒菜,你都需要盐,如果盐放在最顶层的柜子里,每次用都要搬凳子爬上去拿,是不是很麻烦?但如果你把常用的盐、酱油就放在灶台边伸手可及的地方,做饭速度就快多了。

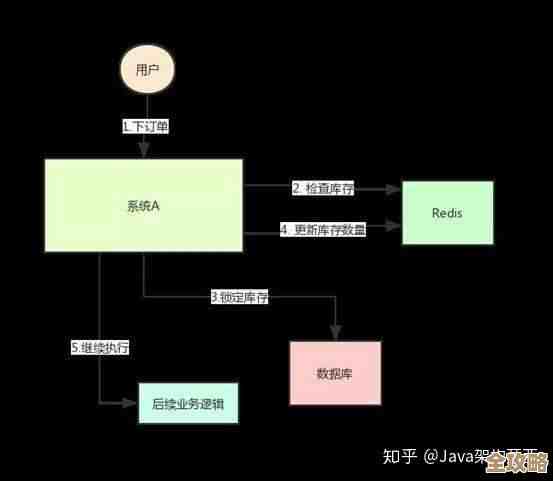
数据库(比如MySQL)就像是那个顶层的柜子,数据存得很稳妥,但每次取东西(执行查询)相对慢一点,Redis就是这个灶台边的调料架,它把最常用、最需要快速拿取的数据放在内存里,内存的读写速度比硬盘快几个数量级,所以一旦数据从Redis里读,系统响应速度就会有质的飞跃,核心就两点:降低数据库的压力和加快数据访问速度。
Redis具体能缓存什么?怎么选?
不是所有数据都适合放缓存,你得挑那些“读多写少”的热点数据。

- 用户信息:用户登录后,其基本信息(用户名、头像等)会被频繁读取,但不会老是修改,可以在用户登录时,把他的信息缓存起来,设置一个合理的过期时间(比如30分钟),下次再需要时,先查Redis,没有再查数据库,并重新塞回Redis。
- 商品详情页:尤其是热门商品,成千上万人浏览,页面内容在短时间内变化不大,可以把整个页面渲染好的HTML片段(这叫页面缓存),或者组成页面的核心数据对象缓存起来,这样请求过来直接返回,连复杂的业务逻辑和数据库查询都省了。
- 排行榜/计数器:Redis自带的数据结构(如ZSET有序集合)非常适合做实时排行榜,比如商品销量榜、游戏积分榜,更新和查询效率极高,同样,用INCR命令做文章阅读量、点赞数的计数,比频繁更新数据库要轻量得多。
- 会话(Session):在集群部署中,把用户的登录会话信息存在Redis里,可以实现多台服务器共享登录状态,避免粘滞会话的麻烦。
用的时候,必须注意的几个坑(关键优化点)
光把数据塞进去不行,用不好反而会出大问题,你提到的“抓紧优化”,很可能就是要解决这些问题。
-
缓存穿透

- 是什么:有人故意请求数据库中根本不存在的数据,比如请求一个不存在的商品ID,这时缓存里没有(叫缓存未命中),就会去查数据库,数据库也没有,每次请求都直接打到数据库上,缓存形同虚设,数据库可能被压垮。
- 怎么办:
- 缓存空对象:即使数据库查不到,也在Redis里存一个空值(比如
key: "product:9999", value: null),并设置一个较短的过期时间(比如5分钟),这样后续同样的请求在过期前就会命中这个空值,保护数据库。 - 布隆过滤器:在查询缓存前,先用布隆过滤器这个数据结构判断一下这个key是否存在,如果布隆过滤器说“不存在”,那肯定不存在,直接返回,就不用查缓存和数据库了,这是一种更高效的方式。
- 缓存空对象:即使数据库查不到,也在Redis里存一个空值(比如
-
缓存击穿
- 是什么:某个热点key(比如一个秒杀商品)在缓存中过期了,就在这时,有大量并发请求同时这个key,所有请求发现缓存没了,齐刷刷地去查数据库,瞬间给数据库带来巨大压力。
- 怎么办:
- 永不过期:对极少数核心热点key,可以设置成永不过期,通过后台任务定期更新它。
- 互斥锁:当第一个请求发现缓存失效时,它先去获取一个分布式锁(Redis自己就可以用SETNX命令实现),然后才去数据库加载数据,其他并发请求看到锁被占有了,就等待片刻,然后重新从缓存尝试读取,这样就只有第一个请求会去查库。
-
缓存雪崩
- 是什么:比击穿更严重,缓存中大量的key在同一时间点或时间段内过期失效,导致所有请求都涌向数据库,数据库压力激增甚至宕机。
- 怎么办:
- 设置随机过期时间:不要让大量key的过期时间都一样,比如基础过期时间设为30分钟,然后在此基础上加上一个随机的1-5分钟,这样key的失效时间就分散开了,避免集体失效。
- 构建缓存高可用:使用Redis集群(如Redis Cluster),这样即使一台Redis机器挂了,其他的还能提供服务。
- 服务降级和熔断:在系统层面,如果发现数据库压力过大,可以对非核心业务进行降级(直接返回默认值或友好提示),或者熔断(暂时停止服务),保住核心业务和数据库。
-
数据一致性
- 是什么:当你更新了数据库里的数据后,缓存里的数据还是旧的,用户看到的就是过时信息。
- 怎么办:这是一个权衡问题,没有完美方案。
- 先更新数据库,再删除缓存:这是比较常用的策略,更新DB后,让缓存失效,下次读取时自然会把新数据加载进来,虽然不是绝对强一致(在删除缓存的极短时间内可能读到旧数据),但简单有效,能满足绝大多数业务场景。
- 更复杂的策略还有“先删缓存再更新数据库”、或者通过订阅数据库的binlog来异步更新缓存等,但复杂度更高,根据业务对一致性的要求来选择。
一些实用的操作建议
- Key的设计:要有可读性,用冒号分隔,比如
user:123:profile,一看就知道是ID为123的用户资料。 - 内存管理:Redis是内存数据库,要监控内存使用情况,配置好淘汰策略(比如LRU,最近最少使用),当内存满时自动淘汰不常用的key。
- 监控:一定要上监控!监控Redis的CPU、内存、连接数、命中率(hit rate)等指标,缓存命中率是一个非常重要的指标,它告诉你缓存有多有效,如果命中率很低,说明缓存策略可能有问题。
用Redis优化性能,思路很简单——“把慢活儿变快活儿”,但真正要做好,关键在于细节处理,也就是如何应对上面提到的那些坑,根据你们系统的具体业务场景,分析出哪些是热点数据,然后制定合适的缓存策略(存什么、存多久、怎么更新),并做好防穿透、击穿、雪崩的方案,把这些“缓存那块儿的事儿”理顺了,系统性能自然就上去了。
本文由凤伟才于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/78538.html