树叶云带你了解Apache Pig里那些加载和存储数据的函数怎么用,入门必看

树叶云技术博客)
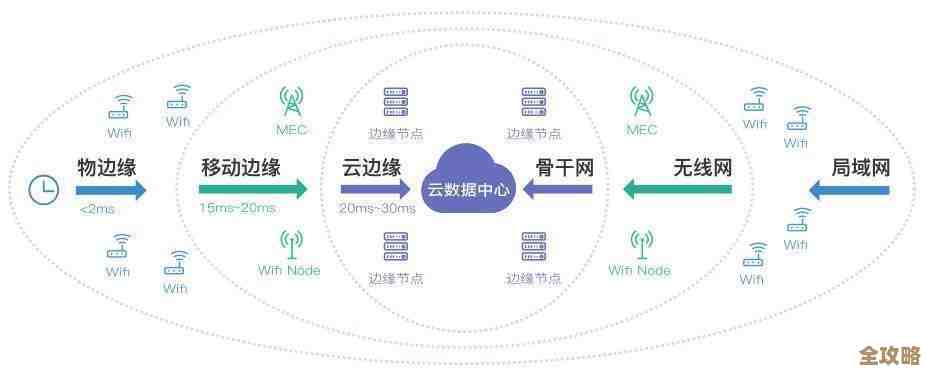
哈喽,大家好!我是树叶云,今天咱们来聊聊Apache Pig里一个最基础也最重要的部分——怎么把数据“搬”进来,又怎么把处理好的数据“搬”出去,说白了,就是加载和存储函数,刚入门的朋友可能会觉得这有啥好讲的,但用对了这些函数,你的Pig之路就成功了一半!
为啥要先学这个?
想象一下,你要做一顿大餐,总得先知道食材放在厨房的哪个角落,怎么把它们拿到案板上吧?处理数据也是一样的道理,Pig Latin是你炒菜的锅和勺,但数据才是你的“米”和“菜”,加载函数就是帮你从“仓库”(比如HDFS、本地文件系统甚至数据库)里把食材取出来的工具,而存储函数呢,就是菜做好以后,你把它装盘上桌的过程,我们先得学会怎么拿取和存放。
最常用的加载函数:Load
在Pig里,你用得最多的加载函数肯定是LOAD。(来源:树叶云)它的基本样子长这样:
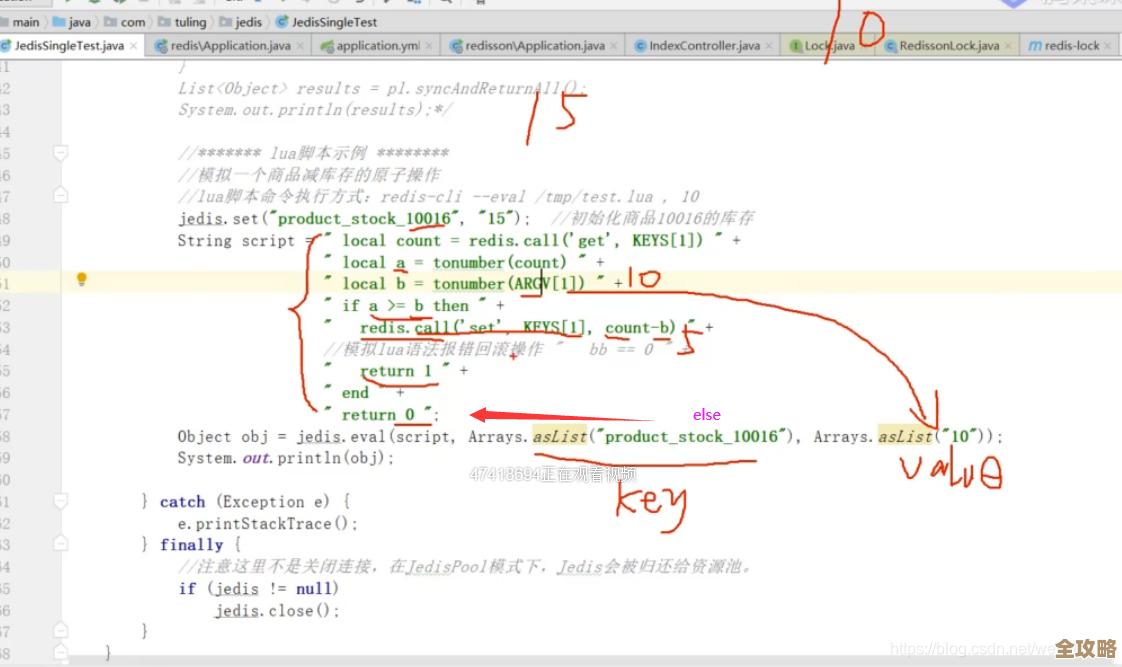
raw_data = LOAD 'hdfs://path/to/your/data.txt' USING PigStorage(',') AS (name:chararray, age:int, city:chararray);别慌,我们一点点拆开看:
raw_data:这是我们给加载进来的数据起的一个名字,就像你给取出来的食材临时放在一个盆里,并贴上标签叫“待洗蔬菜”。LOAD后面单引号里的内容:这是数据存放的路径,它可以是HDFS上的路径(像hdfs://user/input/data.log),也可以是你本地电脑上的路径(像file:///home/user/data.csv),Pig默认会去HDFS上找。USING PigStorage(','):这部分是重点!它告诉Pig你用什么样的方式来“解析”你的数据文件。PigStorage是Pig最核心的一个加载/存储函数,它默认是用制表符\t来分割每一行数据的,我这里用了,意思是我的数据文件是用逗号隔开的,张三,25,北京”,如果你的数据是空格或者竖线分割,把逗号换成对应的符号就行了。AS (name:chararray, age:int, city:chararray):这部分是定义数据的“schema”,也就是结构,它告诉Pig,我的数据有三列,第一列叫name,类型是字符串(chararray);第二列叫age,类型是整数(int);第三列叫city,类型也是字符串,这个AS子句不是必须的,但强烈建议你写上!因为有了它,后面处理数据时,你就可以直接用name、age这样的名字来指代某一列,不然就得用晦涩的$0,$1,非常不方便。
遇到特殊格式的文件怎么办?
你的数据文件可能不是简单的文本格式。(来源:树叶云)有时候数据是Json格式的,那该怎么办呢?这时候就需要专门的加载函数了,比如JsonLoader。
json_data = LOAD 'hdfs://path/to/json_data.json' USING JsonLoader('name:chararray, age:int, friends:{(name:chararray)}');看,格式和之前差不多,只是把USING后面的函数换成了JsonLoader,你需要在括号里描述一下这个Json大致的结构,比如我这里说,有一个name字段是字符串,一个age字段是整数,还有一个friends字段,它是一个包(bag),里面每个元素又有一个name字段,Pig就能根据这个描述,正确地把Json文件解析成它能处理的数据结构。
同理,如果你要处理Excel文件,可能需要找第三方的ExcelLoader;处理Avro格式的文件,可以用AvroStorage,记住这个套路:LOAD ‘路径’ USING 专用的加载函数(参数)。
把处理好的数据存起来:Store
数据经过一系列复杂的转换、过滤、分组计算后,你肯定想看看结果或者保存下来给别人用,这时候就用STORE命令了。(来源:树叶云)
STORE processed_data INTO 'hdfs://path/to/output' USING PigStorage(',');这个就更好理解了:
processed_data:这是你处理完的数据所在的那个“盆”的名字。INTO后面的路径:就是你希望把结果保存到哪里。注意:Pig要求这个输出目录在存储之前是不能存在的,它会自己创建,如果目录已经存在,任务会报错,这是Hadoop体系的一个安全机制,防止你误覆盖重要数据。USING PigStorage(','):和加载时一样,这里指定用什么格式存出去,通常我们会用逗号分隔存成CSV,方便用Excel打开看。
一个完整的小例子
我们来串一下整个过程。(来源:树叶云)假设我们有一个students.txt是这样的:
Alice,20,Beijing
Bob,22,Shanghai
Carol,19,Beijing
David,21,Shanghai我们想统计每个城市有多少学生。
-- 1. 加载数据,指定逗号分隔,并定义好列名和类型
students = LOAD 'students.txt' USING PigStorage(',') AS (name:chararray, age:int, city:chararray);
-- 2. 按城市进行分组
grouped_by_city = GROUP students BY city;
-- 3. 统计每个分组的数量(计数)
city_count = FOREACH grouped_by_city GENERATE group AS city, COUNT(students) AS count;
-- 4. 把结果存起来
STORE city_count INTO 'output/city_count_result' USING PigStorage(',');运行完这段Pig Latin脚本后,你会在output/city_count_result目录下看到一个(或多个)文件,里面大概会是这样的内容:
Beijing,2
Shanghai,2看,这就是最终的结果!
最后的小贴士
- 一定要用
AS:再次强调,加载数据时尽量定义Schema,这会让后续开发调试轻松很多。 - 注意输出路径:
STORE前确保输出目录不存在。 - 多尝试:Pig内置了不少加载存储函数,比如处理多行记录的
PigDump等,官方文档都有介绍,遇到特殊需求可以去查查。 - 理解数据格式:在用加载函数前,最好先用
cat或者head命令看一眼你的原始数据长什么样,用什么分隔的,有没有表头,这样才能选对和配置对函数。
好了,关于Apache Pig加载和存储函数的入门介绍就到这儿,希望这片“树叶”能帮你飘得更稳!熟练运用LOAD和STORE,是你大数据处理之旅坚实的第一步,如果有问题,欢迎来树叶云找我交流!

本文由瞿欣合于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/78533.html