搞定Redis分布式存储那些事儿,聊聊几个靠谱的框架和方案

说到Redis分布式存储,这确实是个挺重要的话题,单机的Redis再快,内存和可靠性也有限,一旦数据量大了或者要求更高了,就得考虑怎么把多台Redis组合起来用,这就是分布式存储要解决的事儿,今天咱们就抛开那些难懂的理论,直接聊聊几种主流和靠谱的框架、方案,看看它们都是怎么“搞定”这个问题的。
最经典也最基础的办法:客户端分片。
这个方案说白了,就是把“数据该放在哪个Redis实例”这个判断逻辑,直接写在了你的应用程序代码里,你可以用一致性哈希算法,根据数据的key算出一个值,然后决定它应该跑到哪台Redis服务器上去。
(来源:Redis官方文档以及早期分布式系统设计的常见实践)这种方式的好处是简单直接,没有中间层,性能损耗小,你的应用程序直接和多个Redis实例对话,架构很清晰,但缺点也非常明显,最大的问题就是“麻烦”,你得自己在代码里实现分片逻辑,如果后来要增加或减少Redis实例,也就是扩容或者缩容,会非常棘手,数据迁移得你自己操心,搞不好就会丢数据或者导致服务不可用,如果某个Redis实例挂掉了,客户端分片方案通常不会自动处理故障转移,需要额外的机制来保障,现在除非是特别简单的场景,否则一般不太推荐直接用这种“裸奔”的方式了。
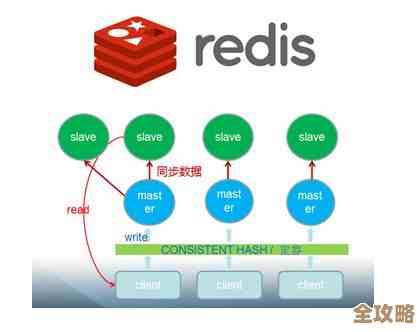
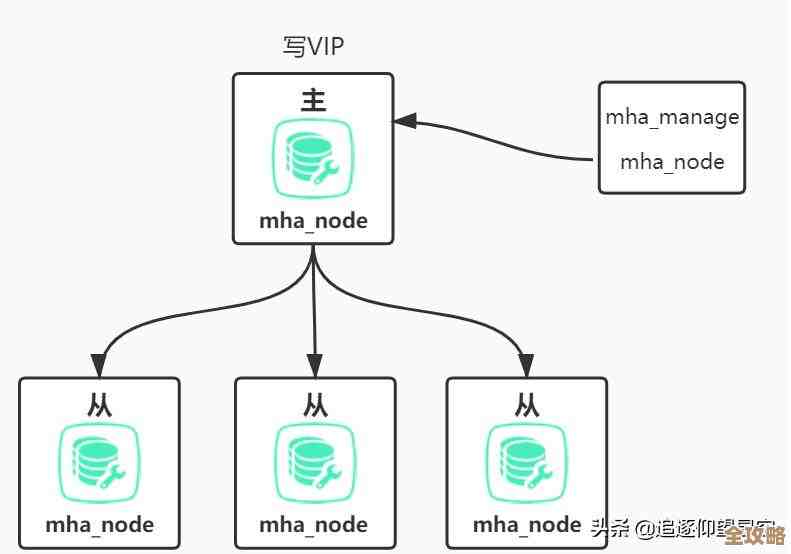
就是目前公认最省心、最主流的方案:使用Redis Cluster。
这是Redis官方自己推出的分布式解决方案。(来源:Redis官方从3.0版本开始提供Redis Cluster)你可以把它想象成Redis自带的一个“集群模式”,它把数据自动分成了16384个槽位(slot),这些槽位会平均分配给集群里的各个主节点,当你存取一个数据时,客户端会先计算key属于哪个槽,然后直接连接到正确的节点上去操作。
Redis Cluster最大的优点就是“官方出品,自带光环”,它帮你解决了分布式存储中最头疼的几个问题:一是自动分片,数据怎么存你不用管了;二是高可用,每个主节点都可以配一个或多个从节点,主节点挂了,从节点会自动顶上来;三是无缝的扩容缩容,官方提供了工具,可以相对平滑地增加或减少节点,并进行数据迁移。

它也不是完美的,它要求客户端必须支持Cluster协议,不是所有语言的Redis客户端都支持得很好,它不支持跨多个key的操作(比如两个key不在同一个节点上,你就不能对它们执行交集操作),这在一定程度上限制了使用方式,对于绝大多数追求稳定和便捷的场景,Redis Cluster是首选。
再来,有一种“中间代理”的方案,代表是Codis。
(来源:豌豆荚开源的Codis项目)这个方案在客户端和Redis服务器集群之间,加了一个代理层(proxy),你的应用程序不再直接连接Redis实例,而是统一连接这个代理,由代理来负责接收请求,根据分片规则把请求转发给后面对应的Redis实例。
这种做法有点像我们平时用Nginx做负载均衡,好处是它对客户端特别“友好”,客户端完全不用关心后端有多少个Redis实例,就像在使用一个单机的Redis一样,兼容性非常好,运维和管理也相对集中,可以在代理层做很多事情。

但缺点也很直接,就是多了一层网络转发,性能上肯定会有一点损耗,这个代理层本身可能会成为单点瓶颈,虽然可以通过部署多个代理实例来避免,但也增加了部署的复杂性,随着Redis Cluster的成熟和普及,Codis这样的第三方代理方案的热度有所下降,但在一些特定的历史项目或对客户端透明性要求极高的场景下,它依然是一个可靠的选择。
还有一种“云服务商方案”。
如果你用的是阿里云、腾讯云这些大厂的云数据库Redis版,(来源:各大云服务商提供的分布式Redis服务)那他们提供的本身就是一套封装好的分布式存储方案,你根本不需要关心底层是Cluster还是自研的架构,只需要选择规格和容量就行了,扩容缩容往往就是一个按钮的事情,后台自动完成数据迁移和故障转移,这对于追求极致运维效率、不想在基础设施上投入太多精力的团队来说,无疑是最“靠谱”和省心的选择,当然代价就是需要付费,并且受限于云厂商的生态。
怎么选,就看你的具体需求,想自己完全掌控,技术实力强,可以用客户端分片(但现在不主流了),想要官方的、功能全面的,就选Redis Cluster,想要对客户端毫无感知, legacy系统改造方便,可以考虑Codis这类代理方案,如果图省心,愿意花钱买服务,直接上云厂商的Redis服务是最快的路子,这些方案没有绝对的好坏,只有适合不适合你当下的情况,希望这些大白话的讲解,能帮你对搞定Redis分布式存储这事儿有个清晰的认识。
本文由度秀梅于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/78333.html