OceanBase执行计划形状怎么看,树叶云带你一步步分析理解

想知道你的OceanBase数据库查询为什么慢吗?执行计划就是它的“体检报告”,但这份报告看起来密密麻麻的,全是专业术语,让人头疼,别担心,我们可以用一个非常形象的方法来理解它——把它想象成一棵树,这就是“树叶云”带你分析执行计划的核心方法:把执行计划看成一颗倒着生长的树。
第一步:找到那棵“树”的根
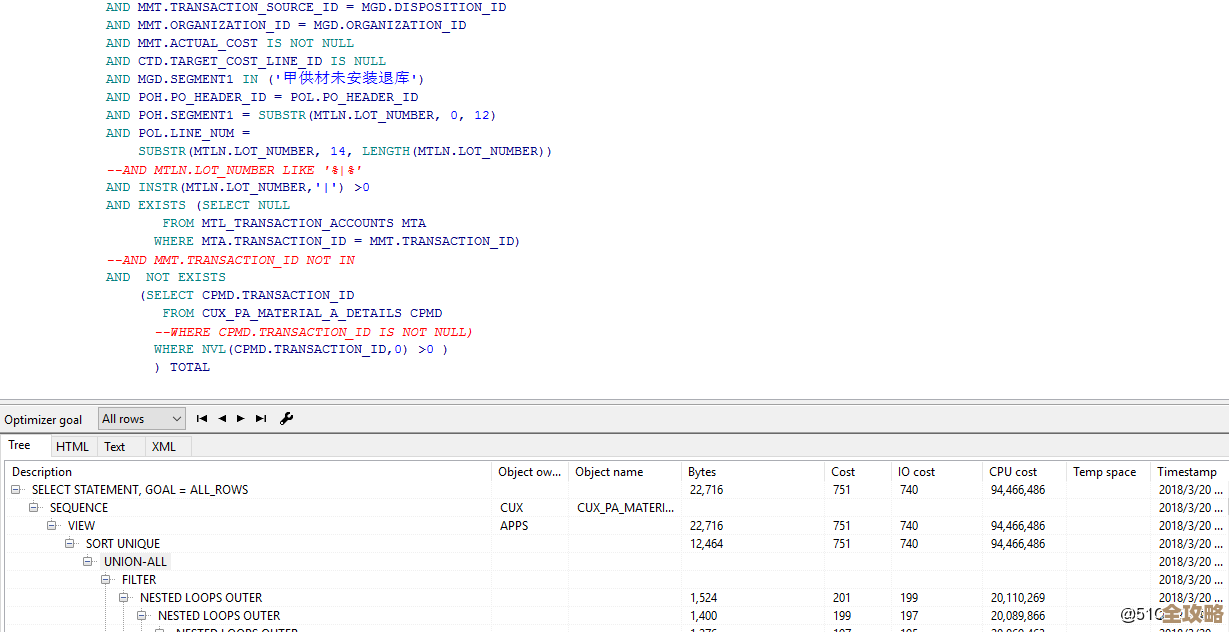
当你拿到一份OceanBase的执行计划时(比如通过 EXPLAIN 命令得到的文本结果),第一件事不是从第一行开始看,而是要先找到这棵树的“树根”,树根在哪里?在整份计划的最右边,或者说是缩进最少的那一行。
为什么是树根?因为数据库执行一个查询,它最终的目标是产出结果集,这个最终产出结果的操作,就是根操作,它通常是整个查询的顶层操作,OUTPUT 或一个合并结果的算子,你可以理解为,这棵树是从树叶开始收集“数据养分”,然后逐级传递,最终汇聚到树根,结出“结果”这个果实,我们的分析路径是从树叶到树根,也就是从执行计划的最后几行往上看。
第二步:识别主要的“树枝”和“树叶”

找到了树根,接下来我们来看树的形状,一棵典型的执行计划树可能有很多分支,但通常可以归结为几种主要的“树枝”:
-
扫描枝干(Access Path):这是树的“树叶”部分,直接负责从表中读取数据,常见的“树叶”有:
- TABLE SCAN:好比是直接把整本书从头到尾翻一遍找内容,这是最基础的扫描方式,如果没索引,就会用这个。
- TABLE GET:好比是通过书的目录精确翻到某一页,这是当你用了主键或唯一索引进行等值查询时的高效操作。
- INDEX SCAN:好比是先看一本书的索引部分,找到关键词所在的页码,然后再去对应页找,这是使用了非主键索引的情况。
根据“树叶云”的提示,你要特别关注这些扫描操作后面括号里的信息,
table:table_name告诉你扫的是哪张表,index:index_name告诉你用了哪个索引,这是优化的关键。 -
连接枝干(Join Branch):如果你的查询涉及多张表关联,那么执行计划树就会有多个分支,然后通过一个“连接”操作把它们合并起来,这个连接点就是一个大的“树枝分叉处”,常见的连接方式有:

- NESTED-LOOP JOIN (NLJ):像一个双循环,从左边分支(外表)取一行数据,然后到右边分支(内表)里一行行去匹配,适合一边数据量特别小的情况。
- HASH JOIN (HJ):先把右边分支(内表)的数据变成一个内存中的“哈希表”(像一种快速查找的字典),然后从左分支(外表)取数据,到这个“哈希表”里快速查找匹配项,当两边数据量都比较大时,这个通常更高效。
- MERGE JOIN (MJ):要求两边分支的数据都已经按照关联键排好序了,然后像拉链一样,两边按顺序合并,如果数据本来就有序,这个效率很高。
你要看明白是哪两个分支(哪两张表)在进行连接,以及用的是哪种连接算法,这能帮你判断连接效率。
第三步:查看关键的“健康指标”
光看树形还不够,我们还得看看每个树枝和树叶的“健康状况”,也就是各种估算指标,在OceanBase的执行计划中,这些指标通常在每个操作算子的后面,用类似 cost=100, cardinality=50 的形式表示,你需要重点关注两个:
- 代价(Cost):这是OceanBase优化器根据统计信息估算出的这个操作需要消耗的CPU、IO等资源的总和。一个基本原则是:Cost值越大的操作,消耗资源越多,执行时间可能越长。 你要留意整棵树中,哪个分支或哪个节点的Cost异常高,那里往往就是性能瓶颈。
- 基数(Cardinality):这是优化器估算的经过这个操作后,会输出多少行数据,这个估算的准确性至关重要,如果优化器估算出某个步骤会返回100行,但实际上返回了100万行,那么它为此步骤选择的算法(比如用NLJ)可能就是灾难性的错误,会导致后续所有步骤都变慢,如果你发现实际执行很慢,但计划看起来没问题,很可能是基数估算不准,需要更新表的统计信息。
第四步:综合起来,诊断问题

我们把树形和指标结合起来看,举个例子:
假设你的查询很慢,你看执行计划,发现树形是一个 NESTED-LOOP JOIN,它的左分支Cost很小,右分支是一个 TABLE SCAN 且Cost巨大,这说明什么问题?
这说明优化器选择了一个策略:先从一个小的结果集(左分支)开始,然后对于这个结果集中的每一行,都不得不去对右边那张大表做一次全表扫描,这就是性能杀手!理想的优化应该是避免对大数据表进行多次扫描,这时你可能需要思考:是不是右表缺少一个合适的索引?或者能不能用 HASH JOIN 来代替?
再比如,你发现一个本该很快的 INDEX SCAN 操作,估算的Cardinality是10,但Cost却奇高无比,这可能意味着索引的选择性不好(比如在“性别”这种字段建索引),或者索引本身出现了问题。
树叶云”教给我们的看计划心法:
- 倒着看:从执行计划文本的底部(树根)往上看,理解数据流动的最终方向。
- 认形状:分清哪些是扫描树叶(TABLE SCAN/GET),哪些是连接枝干(NLJ/HJ/MJ),理清表的关联关系。
- 查指标:紧盯每个操作的Cost和Cardinality,找到成本最高的瓶颈点和估算严重失真的地方。
- 联实际:将计划中的问题(如全表扫描、连接算法不佳)与你实际的表数据量、索引情况联系起来,找到优化方向,比如增加索引、改写查询语句或更新统计信息。
通过这种“把执行计划当成树”的形象化方法,即使你对OceanBase内部原理不深究,也能对查询性能有一个直观的判断,并找到大致的优化思路,多看多练,你就会越来越熟练。
本文由革姣丽于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/78119.html