JuiceFS怎么帮携程解决海量冷数据存储和访问的那些事儿

主要参考自 JuiceFS 官方博客文章《JuiceFS 帮助携程打造降本增效的冷数据存储平台》)
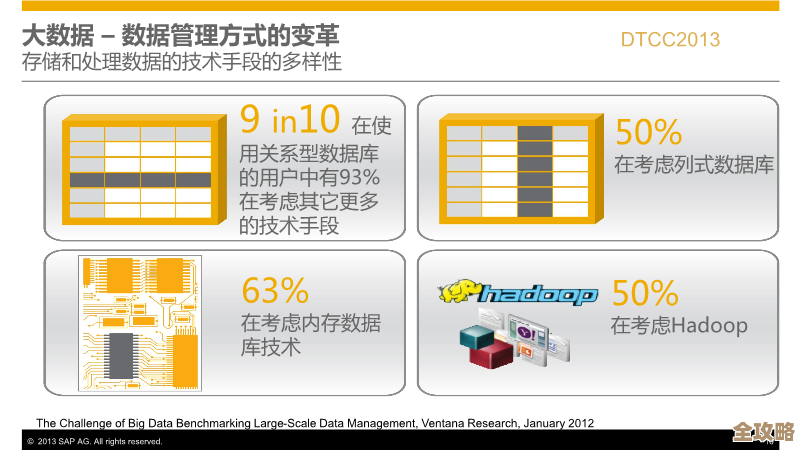
携程作为国内领先的在线旅游服务平台,每天都会产生海量的数据,这些数据中,有很大一部分是访问频率很低但又被规定必须长期保存的“冷数据”,比如用户的日志、订单历史、业务操作记录等,在过去,携程和很多大公司一样,使用传统的存储方案,比如昂贵的商业存储阵列或者直接使用HDFS(一种分布式文件系统)来存这些数据,但随着数据量像滚雪球一样越滚越大,成本问题变得越来越突出,用高性能的存储设备去存那些几乎不被访问的数据,就像是花钱买了个大别墅却只用来堆放杂物,非常不划算。
携程的工程师们开始寻找更经济的解决方案,他们的核心想法是,能不能用一种“分层存储”的策略?就是把经常要用的“热数据”放在性能好的、但比较贵的存储上,而把那些“冷数据”迁移到价格非常便宜的存储介质上,比如对象存储(例如阿里云OSS、AWS S3等),对象存储每TB的月度成本可能只有传统存储的十分之一甚至更低,对于海量冷数据来说,能省下巨额费用。
这个想法在实际操作中遇到了几个大麻烦,第一个麻烦是,携程内部有大量的业务系统、数据分析工具和自研的程序,它们都已经习惯了像访问本地文件一样(我们称之为“POSIX接口”)去访问HDFS里的数据,如果直接把数据搬到对象存储,这些应用程序几乎全部要重写,因为对象存储的访问方式(通常是HTTP接口)和文件系统完全不同,这个改造的工作量是天文数字,几乎不可能完成。
第二个麻烦是数据管理的复杂性,冷数据并不是永远“冷”的,偶尔也会有需要查询或分析的时候,为了排查一个几个月前出现的用户投诉,可能需要调取当时的日志,如果数据简单地堆在对象存储里,查找、读取会非常慢,而且很难管理,携程需要的是一个既能利用对象存储的低成本,又能让应用程序无感知、像以前一样方便地访问数据的解决方案。
正是在这样的背景下,携程的技术团队找到了JuiceFS,JuiceFS是一个开源的分布式文件系统,它恰好完美地解决了携程面临的这两个核心痛点。
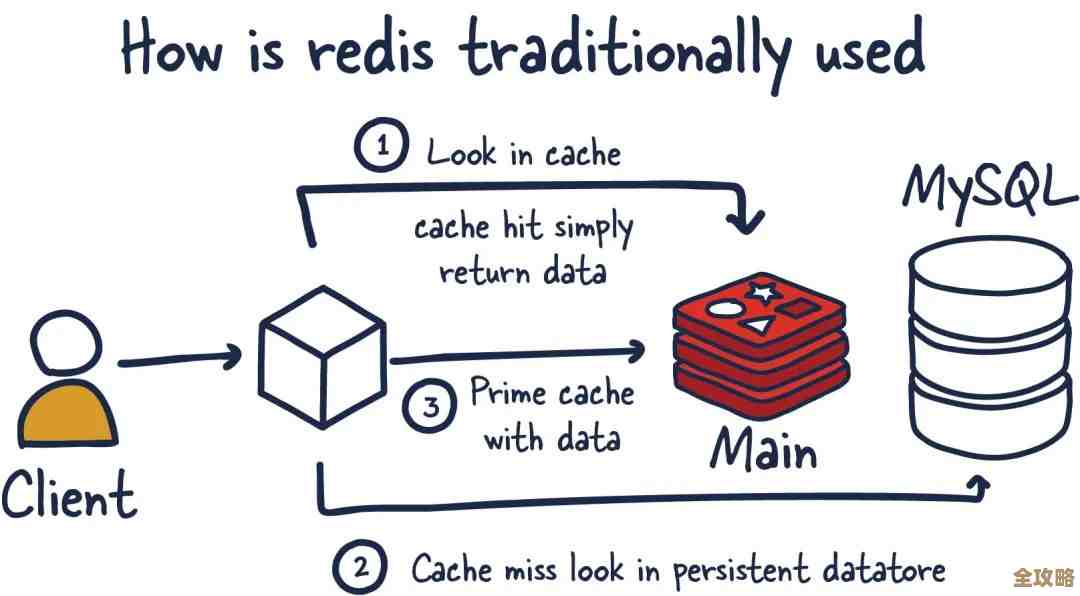
JuiceFS的工作原理可以简单理解为是一个“聪明的中间层”,它自己并不直接持久化存储文件数据,而是把数据切片后,自动存储到用户指定的低成本对象存储中(携程选择了阿里云OSS),JuiceFS会在自己的元数据服务(携程选择了Redis集群)里,非常精细地记录每个文件的详细信息,比如文件名、大小、权限以及文件块具体存储在对象存储的哪个位置。
这样做的好处立刻就显现出来了,对于携程的应用程序来说,它们完全感觉不到底层存储已经从天价的存储设备换成了便宜的对象存储,应用程序还是通过标准的文件接口(比如open, read, write)来访问数据,JuiceFS这个中间层会默默地在背后处理所有复杂的事情:当需要读文件时,它根据元数据服务找到文件块的位置,然后从对象存储取回数据;当写入新数据时,它负责将数据切片、加密(如果需要)并上传到对象存储,这样一来,携程所有的现有程序无需做任何修改就能继续运行,实现了“无缝迁移”,这是JuiceFS带来的第一个巨大价值。
第二个巨大价值是性能的提升,你可能会觉得,底层换成了慢速的对象存储,速度肯定会变差,但对于冷数据访问场景,JuiceFS通过两个关键技术反而优化了体验,一是“缓存”,JuiceFS支持在计算节点本地或者高速云盘上设置缓存层,一旦某个数据被访问过,就会被缓存起来,下次再访问时速度就极快,非常适合那种偶尔需要回溯分析冷数据的场景,二是“元数据高性能”,因为文件的元信息(比如列出目录下的文件清单、查看文件属性)是存储在Redis这样的高性能数据库里的,所以像ls这类操作的速度非常快,远远超过了直接与对象存储交互的速度,管理海量文件时体验非常好。
JuiceFS本身是分布式架构,可以轻松扩展,满足携程业务不断增长的数据量需求,它也提供了完善的数据安全、监控等功能,符合企业级应用的要求。
根据携程公开的分享,通过采用基于JuiceFS的冷数据存储平台,他们成功地将冷数据的存储成本降低了超过70%,这是一个非常可观的数字,由于JuiceFS的透明性,业务部门的开发人员没有增加额外的学习负担,数据平台的运维团队也借助JuiceFS简化了管理流程,可以说,JuiceFS帮助携程在保证业务连续性和便捷性的前提下,优雅地解决了海量冷数据存储的成本和访问难题,真正做到了降本增效。

本文由盘雅霜于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/78092.html