想知道怎么快点搭好Redis集群,安装配置那些事儿一步步教你搞定

想知道怎么快点搭好Redis集群,安装配置那些事儿一步步教你搞定 主要参考了Redis官方文档以及一些常见的技术社区实践分享,比如Stack Overflow、CSDN博客等)
好,咱们直接开干,别怕,这事儿听起来高大上,其实一步步来,没那么复杂,目标就是用最快的速度,让你手上有一个能跑起来的Redis集群。
第一步:把Redis软件装到机器上
你得有Redis软件,最省事的办法就是用系统的包管理工具,如果你用的是CentOS或者RedHat系统,打开终端,输入:
sudo yum install epel-release # 先装个扩展软件源
sudo yum install redis # 再装Redis如果你用的是Ubuntu或者Debian,命令是这样的:
sudo apt update # 先更新一下软件列表
sudo apt install redis-server # 然后安装Redis服务器你也可以去Redis官网下载最新版本的源码,自己编译安装,那样更灵活,但步骤会多一点,直接用包管理器安装最快最省心,安装完成后,可以先试试能不能启动单机的Redis服务:sudo systemctl start redis,用redis-cli ping命令,如果它回复你PONG,那就说明单机版Redis没问题了,基础打好了。
第二步:搞清楚Redis集群是啥,要几台机器
简单理解,Redis集群就是把一堆Redis实例组合在一起,共同对外提供服务,这样做主要有两个好处:一是数据分片,把海量数据分散存储,容量更大;二是高可用,某个实例挂了,其他的还能继续工作。
一个正经的、能容错的最小Redis集群,至少需要3个主节点(Master) 和3个从节点(Slave),为啥要这么多?主要是为了投票选举,如果某个主节点挂了,它的从节点要能顶上去,这个选举过程需要大多数节点同意,3个主节点的情况下,挂掉1个,剩下2个还能形成多数派做决定。
为了方便演示,我们可以在一台机器上用不同的端口号来模拟6个Redis实例,但在真实环境里,你最好把这6个实例部署到3台或者6台不同的物理机或虚拟机上,这样才能真正起到高可用的效果,这里我们先按单机模拟的方式来,这样你理解起来最快。
第三步:准备集群的配置文件
既然在一台机器上模拟,我们就创建6个配置文件,对应6个不同的端口,比如7001到7006。
- 先找个地方建个文件夹,比如叫
redis-cluster:mkdir redis-cluster cd redis-cluster - 然后创建6个配置文件,我们以7001端口的为例,创建文件
redis-7001.conf,把下面这些内容放进去:port 7001 # 监听端口,每个实例要改 cluster-enabled yes # 开启集群模式,这是关键! cluster-config-file nodes-7001.conf # 集群自己的配置文件(自动生成) cluster-node-timeout 15000 # 节点超时时间 appendonly yes # 开启数据持久化 daemonize yes # 以后台守护进程方式运行 pidfile /var/run/redis_7001.pid # 进程ID文件 logfile "/path/to/your/redis-cluster/7001.log" # 日志文件路径,你自己要改一下注意:
logfile那个路径,你要换成你自己刚才创建的redis-cluster文件夹的真实路径。 - 把
redis-7001.conf复制5份,分别叫redis-7002.conf、redis-7003.conf……一直到redis-7006.conf,然后用文本编辑器把里面所有的7001都替换成对应的端口号(7002、7003...),这一步有点枯燥,但必须做对。
第四步:启动所有的Redis实例

配置文件都准备好之后,就可以逐个启动它们了,在redis-cluster目录下,运行:
redis-server redis-7001.conf
redis-server redis-7002.conf
redis-server redis-7003.conf
redis-server redis-7004.conf
redis-server redis-7005.conf
redis-server redis-7006.conf每运行一条命令,如果没有报错,就说明一个实例启动成功了,你可以用ps aux | grep redis命令看一下,应该能看到6个redis-server进程在运行。
第五步:最关键的一步——组建集群
现在有6个独立的Redis实例在跑了,但它们还是散兵游勇,我们需要把它们拧成一股绳,组成一个集群,从Redis 5.0版本开始,官方给了个超级好用的工具叫redis-cli --cluster create,一条命令就能搞定。
在终端里输入下面这条长长的命令(确保你安装了Redis 5.0或以上版本):
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1解释一下:
--cluster create:告诉redis-cli我们要创建集群。- 后面跟着6个节点的地址和端口。
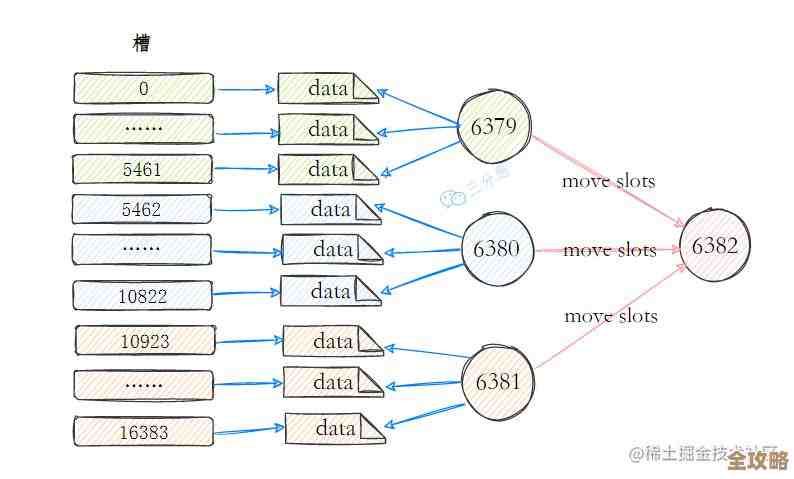
--cluster-replicas 1:这个参数是关键!意思是每个主节点配1个从节点,所以工具会自动从前3个节点(7001,7002,7003)中选出主节点,然后把后3个节点(7004,7005,7006)分别设置为它们的从节点。
命令执行后,redis-cli会给你显示一个它规划好的主从分配方案,你仔细看一下,确认无误后,输入yes并按回车,工具就会开始自动进行节点握手、分配数据槽(slots)、同步数据等一系列操作,等它跑完,你会看到类似[OK] All 16384 slots covered.的提示,这说明集群已经成功搭建好了!16384个数据槽都分配完毕。
第六步:验证一下集群是否正常工作

集群建好了,得试试它灵不灵,我们用redis-cli连接上集群(注意要加-c参数,表示集群模式),然后存个数据试试:
redis-cli -c -p 7001 # 连接任意一个节点都行,比如7001进入命令行后:
0.0.1:7001> set mykey "hello cluster"
-> Redirected to slot [14687] located at 127.0.0.1:7003 # 看,它自动跳转到了7003节点!
OK
127.0.0.1:7003> get mykey
"hello cluster"你看到了吗?你虽然连接的是7001端口,但当你设置mykey时,Redis集群根据计算发现这个key应该存放在7003节点上,于是自动帮你重定向了过去,并且操作成功了,这说明集群的数据分片功能在工作了!
你再随便连个节点,比如7004(它是一个从节点),试试读数据:
redis-cli -c -p 7004
127.0.0.1:7004> get mykey
-> Redirected to slot [14687] located at 127.0.0.1:7003
"hello cluster"看,从节点也能正确读到数据(虽然它也是重定向到主节点7003去读的)。
收尾和一些提醒
到这里,一个最基础的Redis集群就搭好了,是不是比想象中简单?总结一下最快的关键:用包管理装软件 -> 改6个端口不同的配置文件 -> 启动6个实例 -> 用一行redis-cli --cluster create命令自动组建集群。
最后唠叨几句:
- 生产环境:千万别像这样把所有节点放一台机器上,一旦机器挂了,全完蛋,至少分到3台机器上。
- 防火墙:真实部署时,记得确保这些Redis端口在各个服务器之间是能互相访问的。
- 密码:上面为了简单没设密码,生产环境一定要配置密码认证,在配置文件里加
requirepass和masterauth指令。 - 管理:日常维护可以用
redis-cli --cluster check来检查集群状态。
希望这个一步步的指南能帮你快速搞定Redis集群的搭建!多动手试一遍,印象更深刻。
本文由黎家于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/78043.html