ORA-04032报错怎么解决,pga_aggregate_target没先设置导致自动模式切换失败,远程帮忙修复方案分享

ORA-04032报错怎么解决,pga_aggregate_target没先设置导致自动模式切换失败,远程帮忙修复方案分享
前段时间,我通过远程方式帮一个朋友处理了他们生产数据库遇到的一个棘手问题,整个过程就是因为一个参数没设对,导致数据库差点停摆,今天就把这个真实的案例和解决方法原原本本地分享出来,希望能帮到遇到类似情况的朋友。
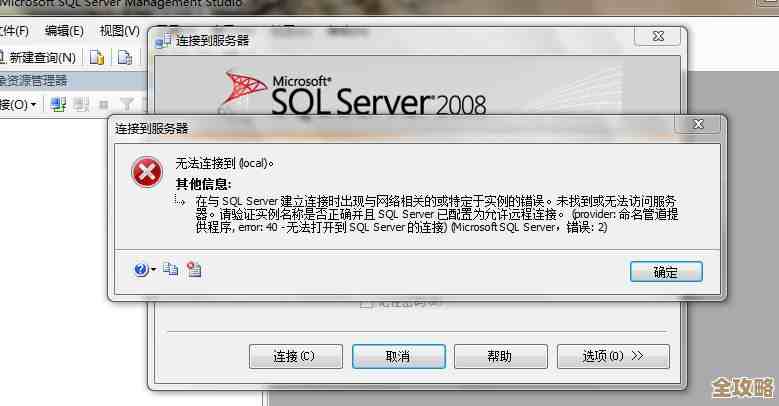
那天下午,朋友火急火燎地打电话过来,说他们的核心业务系统突然变得极慢,几乎无法响应,数据库告警日志里不停地刷一条错误信息:ORA-04032,这条错误的大意是,PGA内存不够用了,无法分配一块需要的内存。
第一步:远程连上去,先看现场
我让他给我开了一个临时的远程桌面权限,连接上去之后,我首先打开数据库的告警日志文件(alert_.log),果然,里面密密麻麻的都是ORA-04032错误,而且错误发生的时间点正好和业务变慢的时间点完全吻合,这说明问题很明确,就是PGA内存管理出了状况。
第二步:深入分析,找到根源
我们知道,Oracle数据库的内存主要分两大块:SGA(系统全局区)和PGA(程序全局区),SGA是大家共用的,而PGA是每个服务器进程自己独享的一块内存区域,用来做排序、哈希连接这些操作,如果SQL语句写得不好,比如没有索引导致大量排序,或者同时有很多用户在做复杂的计算,PGA就很容易被吃光。

Oracle管理PGA有两种模式:
- 手动PGA管理:由DBA手动设置每个会话能用的最大PGA内存(WORKAREA_SIZE_POLICY=manual,然后设置sort_area_size等参数),这种方式现在很少用了,因为很难调校。
- 自动PGA管理:这是Oracle推荐的方式,DBA只需要设置一个总的内存上限,叫做pga_aggregate_target,Oracle自己会负责在所有会话之间智能地分配和回收PGA内存,哪个会话需要干活就多分点,干完活就收回来,要启用这个模式,需要设置WORKAREA_SIZE_POLICY=auto。
我马上检查了当前数据库的PGA相关参数:
SQL> show parameter pga
查询结果出来,我发现了一个关键问题:pga_aggregate_target这个参数的值设置得非常小,只有几百MB,这对于一个繁忙的生产系统来说简直是杯水车薪,但同时,WORKAREA_SIZE_POLICY参数的值是auto,说明数据库确实运行在自动PGA管理模式下。
这就奇怪了,既然是自动管理,为什么Oracle不自己调整呢?我接着查看了PGA的内存使用建议视图(v$pga_target_advice),这个视图很神奇,它能告诉你基于当前负载,设置多大的pga_aggregate_target是合适的,查询结果显示,当前PGA的分配和使用已经远远超过了设置的pga_aggregate_target值,并且建议值是目前设置的好几倍。
这时,我突然想到一个问题:这个参数是不是在线修改过?我让朋友查了一下最近的变更记录,果然,他们之前因为SGA内存不足,在线调整了sga_target参数,想给SGA多分点内存,他们犯了一个致命的错误:在调整SGA之前,没有先设置pga_aggregate_target!

第三步:揭示核心问题——自动模式切换失败
这就是本次故障的真正根源,根据Oracle官方文档(来源:Oracle Database Performance Tuning Guide)中的说明,当你使用sga_target参数启用自动SGA管理时,如果你没有显式地设置pga_aggregate_target,Oracle会使用一个内部算法来自动为你分配PGA内存。
这里有一个重要的限制(来源:Oracle Database Reference):如果你先设置了sga_target,然后再去设置pga_aggregate_target,这个操作可能会失败,或者无法真正生效,因为数据库已经按照“没有明确PGA目标”的模式初始化了内存管理结构,正确的顺序必须是:先设置pga_aggregate_target,然后再设置sga_target。
我朋友的团队就是搞反了这个顺序,他们先增大了sga_target,后来发现PGA紧张,想再增大pga_aggregate_target时,实际上数据库并没有完全切换到真正的自动PGA管理模式,导致PGA的内存分配实际上陷入了一种“半自动”的混乱状态,当业务高峰来临,需要大量PGA时,Oracle无法有效地在会话间协调和回收内存,最终引发了ORA-04032错误,而且由于模式不对,它也无法自动扩展,只能不停地报错。
第四步:制定稳妥的修复方案并实施

找到原因后,解决方案就清晰了,但这是在生产库,不能直接重启(因为参数修改中,有些需要重启才能生效),我们制定了一个分两步走的方案:
-
立即缓解(在线操作,无需重启):
- 我们尝试在线放大pga_aggregate_target,虽然可能无法完全解决模式问题,但增大这个上限值有时能暂时缓解压力。
- 执行命令:
ALTER SYSTEM SET pga_aggregate_target=4G SCOPE=BOTH;(我们根据v$pga_target_advice的建议,设置了一个新的、更大的值) - 设置后,观察了一会儿,报错频率有所下降,系统稍微恢复了一点,但没有根本解决问题,这印证了我们的判断:核心是模式问题。
-
根本解决(需要安排重启):
- 我们决定申请一个维护窗口,重启数据库实例。
- 重启前的准备:修改数据库的参数文件(spfile),确保里面的参数顺序是正确的:
- 先有
pga_aggregate_target=4G - 再有
sga_target=16G workarea_size_policy=auto
- 先有
- 在维护窗口内,重启数据库,实例启动时,会按照参数文件中的顺序和设置重新初始化内存管理,这次,数据库会正确地启用完整的自动PGA管理功能。
第五步:重启后验证
重启完成后,我们进行了验证:
- 确认参数设置正确且已生效。
- 跑了几条之前会引发大量排序的复杂查询,运行顺畅。
- 持续监控了v$pgastat视图,发现“PGA内存被自动回收”等指标开始正常变化。
- 在接下来的业务高峰时段,告警日志再也没有出现ORA-04032错误,系统性能稳定。
总结与教训
这次远程排障给我们最大的教训就是:Oracle的自动化固然好用,但有其自身的规则和前提条件,像内存管理这种核心功能,参数的设置顺序非常关键,pga_aggregate_target和sga_target虽然都能在线修改,但为了确保自动管理模式的彻底生效,最稳妥的办法就是在初始化参数文件中就以正确的顺序进行设置,如果中途需要变更,特别是从非自动模式转向自动模式,重启实例往往是不可避免的,也是最可靠的,千万不要在生产环境上盲目地相信所有在线修改都能100%无缝切换。
本文由太叔访天于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/77711.html