红色活力带你玩转Redis项目那些实用又容易忽略的小技巧

(来源:红色活力公众号文章《带你玩转Redis项目那些实用又容易忽略的小技巧》)
Redis大家肯定都用过,但有些小技巧就像藏在角落里的宝贝,知道了能让你事半功倍,今天就来聊聊那些容易被忽略,但超级实用的Redis技巧。
Key命名不是随便叫的:用“:”来构建命名空间
很多人给Key起名很随意,比如存用户数据就叫user123,存订单就叫order456,这样看起来没问题,但当Key多了以后,管理和查找就成了噩梦。
小技巧来了:使用冒号来模拟文件夹路径,把user123的名字改成user:123:profile,把order456改成order:456:info,这样做有几个天大的好处:
- 一目了然:一看
user:123:profile就知道这是用户123的个人资料,user:123:orders则是他的订单列表,结构清晰,像文件系统一样。 - 方便批量操作:如果想删除用户123的所有相关数据,你可以用通配符
user:123:*来匹配并删除,非常方便,如果你用的是user123_profile这种用下划线连接的命名方式,就很难做到精准的批量操作。 - 工具支持好:像Redis Desktop Manager这样的可视化工具,会把冒号识别为文件夹分隔符,让你的Key在界面上以树形结构展示,管理起来特别舒服。
下次设置Key时,多打两个冒号,长远来看能省下不少麻烦。
让Key学会自动“过期”,解放你的双手
我们经常需要缓存一些数据,比如短信验证码、用户登录会话等,这些数据有个特点:只在短时间内有效,如果你忘了手动删除它们,这些“垃圾”Key就会一直占着内存。
这时候,Redis的EXPIRE命令就是你的救星,它可以让任何一个Key拥有一个“生存时间”,时间一到,Redis会自动把它删除。
实用场景:
- 短信验证码:设置存活时间为5分钟,
SET code:13800138000 123456 EX 300,5分钟后,这个验证码自动失效并被清理,安全又省心。 - 用户登录Token:设置一个较长的存活时间,比如7天,用户每次活跃时,可以用
EXPIRE命令重置这个时间(俗称“续期”),实现“活跃用户保持登录,不活跃用户自动退出”的效果。 - 热点数据缓存:缓存一些数据库查询结果,设置10分钟过期,这样既能减轻数据库压力,又能保证数据不会太旧。
养成给临时数据设置过期时间的习惯,是写出健壮、高效应用的基础。

管道(Pipeline):不是队列,但比队列还快
Redis很快,但每次操作都有网络往返的开销,如果你要执行一万次SET命令,就意味着一万次网络延迟,这个累加起来就很可观了。
Pipeline(管道)技术就是为了解决这个问题,它的原理很简单:把多个命令打包,一次性发送给Redis服务器,服务器处理完所有命令后,再把结果一次性返回给你,这样就大大减少了网络往返的次数。
举个例子:你要给10000个用户填充缓存数据。
- 不用管道:网络通信10000次,慢!
- 使用管道:可能只需要10次或更少的网络通信(分批打包),速度提升非常明显,有时能达到10倍甚至百倍。
注意:Pipeline不是原子性的,它只是批量发送命令,如果你需要保证一批命令的原子性(要么都成功,要么都失败),应该使用事务(MULTI/EXEC),但大多数批量操作的场景,追求的是速度而非强原子性,所以Pipeline用得更普遍。
小心“KEYS”命令,它会让你“社死”

当你想查找符合某个模式的Key时,很自然会想到KEYS *或者KEYS user:*。在生产环境(线上正在运行的系统)中,绝对不要使用这个命令!
为什么呢?因为KEYS命令会一次性遍历数据库中的所有Key,然后返回所有匹配的结果,如果你的Redis里存了几百万甚至上千万个Key,这个命令会阻塞Redis服务器,导致在这段时间内(可能是几百毫秒甚至几秒)所有其他命令都无法执行,服务就像“卡死”了一样,对用户来说就是系统崩溃。
那该怎么办?用SCAN命令替代。
SCAN命令采用迭代器的方式,每次只返回一小部分数据,不会阻塞服务器,虽然它可能无法一次性拿到所有结果,需要你循环调用,但这是安全的,不会影响线上服务。生产环境,SCAN是朋友,KEYS是敌人。
不只是缓存,Redis是“瑞士军刀”
很多人把Redis只当作一个简单的缓存来用,这实在是大材小用了,Redis丰富的数据结构让它能解决很多特定场景的问题。
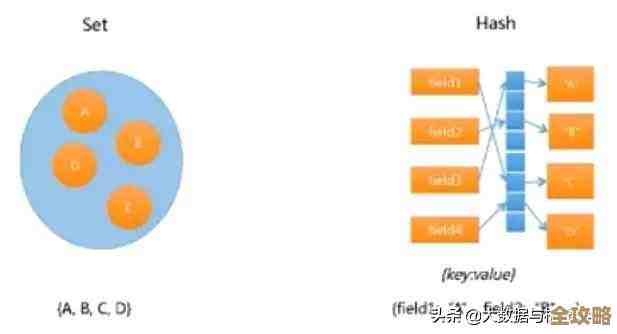
- 用Set实现标签系统:给用户打标签,可以用
SADD user:123:tags tag1 tag2 tech-lover,可以轻松实现求共同标签(SINTER)、推荐可能认识的人(基于共同标签)等功能。 - 用ZSet实现排行榜:游戏积分榜、热搜榜,用ZSet再合适不过了。
ZADD leaderboard 1000 "玩家A",然后ZREVRANGE leaderboard 0 9就能取出前十名,高效又简单。 - 用HyperLogLog做基数统计:如果你需要统计一个大型网站的UV(独立访客数),用Set会非常耗内存,HyperLogLog是一种概率数据结构,它只需要12KB的内存,就能统计最多2^64个不重复元素,虽然有一定误差(约0.81%),但在这个场景下完全可接受,命令
PFADD和PFCOUNT用起来非常简单。
这些只是Redis强大功能的冰山一角,多去了解它的数据结构,你会发现它更像一个多功能的工具箱,而不仅仅是个缓存。
用好Redis的关键在于细节:规范的命名、善用过期时间、管道提升性能、避开KEYS陷阱,并深度挖掘其数据结构的潜力,希望这些小技巧能让你的Redis用得更溜!
本文由太叔访天于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/76144.html