Redis突然崩溃了,完全没头绪到底咋回事,真是让人抓狂

(一篇关于Redis崩溃排查的吐槽式记录,来自某程序员深夜加班日志)
哎,真是怕什么来什么,今天晚上十点多,正打算收拾东西回家,手机就开始嗡嗡嗡地狂响,报警短信一条接一条,心里咯噔一下:完了,肯定是线上服务出问题了,赶紧打开电脑连VPN,一看监控大盘,好几个核心服务的响应时间直线飙升,都快成心电图了!再一查,源头直指那台扛着大部分缓存流量的Redis主节点——它挂了,彻底不响应了。

当时第一反应就是“不可能啊”!这台机器配置挺高的,内存使用率平时也就百分之六七十,CPU更是闲得很,怎么毫无征兆就崩了呢?真是完全没头绪,一下子血压就上来了,赶紧手忙脚乱地重启Redis进程,还好重启之后服务暂时恢复了,但这事儿不搞清楚,今晚谁都别想睡踏实了。
首先想到的是不是内存爆了?虽然监控看着没事,但万一呢,赶紧去翻Redis的日志文件,好家伙,这一看还真发现了点东西,在崩溃前几分钟,日志里密密麻麻全是这种警告:“Can‘t save in background: fork: Cannot allocate memory”(后台保存失败:fork操作无法分配内存),这行字我见过,但以前没当回事,觉得只是瞬间抖动,查了一下资料才明白,这问题比想象中麻烦。(这个错误信息是Redis日志里的常见报错)

简单说,就是Redis为了做持久化(就是把内存里的数据写到硬盘上备份),需要创建一个子进程,创建子进程的这个“fork”操作,在Linux系统下,理论上需要分配和父进程(也就是Redis主进程)一样多的内存,哪怕这个内存只是“看起来”需要,实际可能不会用那么多(这叫做写时复制),但操作系统得先把这个“名额”给你留着,我们的Redis实例占了快30个G的内存,这意味着fork的时候,系统要瞬间准备出另外30个G的虚拟内存空间,问题就出在这里:虽然我们的机器物理内存还够,但“虚拟内存”的空间可能不足了!
这又引出了一个关键设置:Overcommit Memory(内存过量使用),这算是Linux内核的一个策略,它决定是否允许程序申请比实际物理内存加上交换空间(swap)还要大的内存,我们的服务器设置是vm.overcommit_memory=0,这是默认值,在这个模式下,内核会做一个比较保守的检查,它可能会觉得“哎呀,你Redis已经用了30G,现在fork又要30G,万一你们父子俩以后都把内存改个遍,那不就需要60G了?我物理内存加swap都没60G,风险太大,不批!”fork失败,Redis的持久化操作就卡住了,进而可能引发各种连锁反应,最终导致服务不可用。
那怎么解决呢?通常有三种选择:把overcommit_memory改成1(内核变成“老好人”,来者不拒,但有一定风险),或者改成2(设置一个合理的超额比例),但更治本的办法是扩大交换空间(swap),给系统多一点缓冲的余地,我们当时为了快速恢复,先临时加大了swap分区,然后观察后续的fork操作,果然再没报那个错了,长远来看,可能还需要优化Redis的内存使用,比如检查有没有大Key、减少不必要的缓存数据,或者考虑搭建集群把单实例的内存降下来。
除了内存问题,我还顺带排查了其他几个“嫌疑犯”,是不是有“慢查询”把整个Redis服务器拖死了?用slowlog get命令看了一下,确实有几个查询命令耗时比较长,但看起来不像是压死骆驼的最后一根稻草,还有就是怀疑是不是碰上了Redis的“持久化阻塞”,如果同时开启了RDB(快照)和AOF(日志),在特定条件下它们可能会一起工作,导致磁盘I/O压力巨大,让Redis暂时无法响应请求,检查了一下配置,我们的AOF是每秒刷盘,RDB是定时任务,时间点对不上,这个可能性暂时排除。
这一通折腾下来,天都快亮了,最大的教训就是:不能光盯着物理内存使用率那一个数字,像fork内存分配这种“隐藏关卡”,平时风平浪静时屁事没有,一到关键时刻就能让你栽个大跟头,还有,监控一定要做细致,不能只监控服务是否存活,像fork错误、持久化状态、慢查询数量这些指标,都得纳入监控报警体系里,不然等出了问题再查日志,就太被动了,Redis这东西,用起来是爽,但真要发起脾气来,也真是让人抓狂到想撞墙,今晚算是又交了一笔学费。

本文由凤伟才于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/76036.html
相关文章
-

一直在排查Redis连接主机的问题,就是连不上主机,真是头大
-
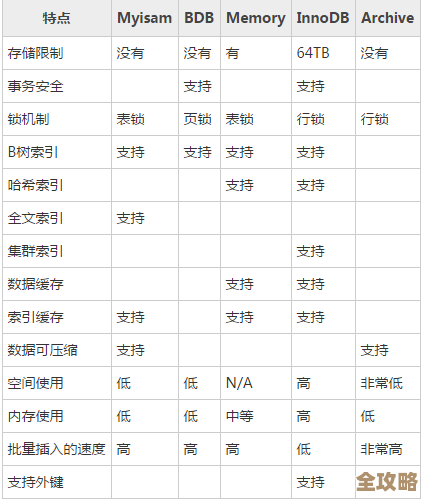
MySQL里各种索引到底是啥,怎么用才算合适,有点乱想跟你聊聊
-

信创云来了,易捷行云EasyStack这次又搞了个全栈新东西,感觉挺厉害的
-

现在特别火的那些云原生技术,哪些真心值得咱们多留意和学学呢
-

ORA-25176报错搞不定?主键存储规格问题远程帮你修复解决
-
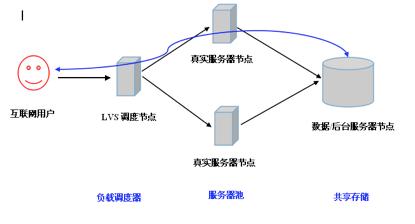
Redis 用来做用户登录管理其实挺简单又高效的,怎么用 Redis 快速搞定登录验证和状态维护
-
用Redis难免遇坑,别说我没提醒你,这些坑真不少也挺折腾
-
MySQL报错MY-013471,ER_GRP_RPL_RECOVERY_STRAT_CHOICE故障远程修复思路分享