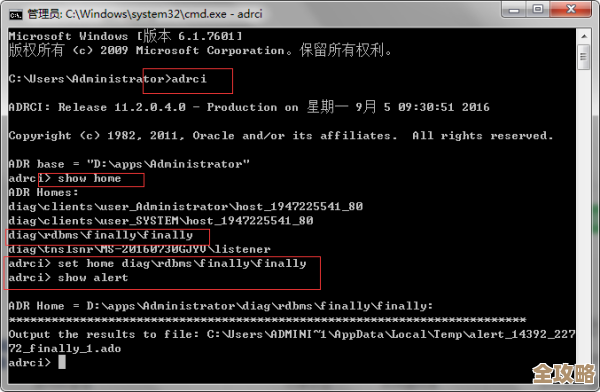
Redis里放表格数据怎么搞,存储和操作那些事儿讲讲

关于在Redis里存放表格数据,首先要明白一个核心思想:Redis不是像MySQL那样的关系型数据库,它没有“表”、“行”、“列”这些现成的概念。 你不能直接创建一个表然后往里插数据,我们的做法是,利用Redis灵活的数据结构,来“模拟”出表格的形态,并实现类似的操作。
这听起来可能有点绕,但其实很简单,下面我就讲讲几种常见的“搞法”。
第一种搞法:用哈希(Hash)来存一行数据。
这是最直观、最常用的一种方法,你可以把表格的每一行数据看作一个对象,比如你有一个用户表,有ID、姓名、年龄三个字段,那么在Redis里,你可以为每一行数据创建一个Hash结构。
- 存储: 使用
HSET命令。- 比如存用户张三:
HSET user:1 id 1 name 张三 age 30 - 这里的
user:1就是整个这一行数据的Key,冒号后面的1可以理解为数据库里的主键ID。id、name、age就是字段名。
- 比如存用户张三:
- 查询:
- 获取整个一行:
HGETALL user:1,它会返回所有字段和值。 - 只获取某个字段:
HGET user:1 name,这样就只得到“张三”。
- 获取整个一行:
- 更新: 也是用
HSET,指定要更新的字段就行。HSET user:1 age 31,就把年龄改成了31。 - 优点: 非常自然,读写单个字段效率很高,因为Redis的Hash结构就是为存储对象设计的。
- 缺点: 如果你需要按年龄查找所有30岁的用户,Hash本身做不到,因为Redis的Key是
user:1,它无法根据内部值(比如age=30)来反查Key,这就需要用到第二种搞法。
第二种搞法:用集合(Set)或有序集合(Sorted Set)来建立索引。
为了解决上面“按条件查询”的问题,我们需要引入“索引”的概念,就像书后面的目录一样。
- 存储:
- 继续用Hash存每一行的详细数据。
- 我们专门创建一个Set来存放所有30岁用户的ID,命令是
SADD users:age:30 1,假设李四(ID为2)也是30岁,那就再执行SADD users:age:30 2。 - 这样,
users:age:30这个Set集合里,就包含了[1, 2]两个用户ID。
- 查询:
- 当你想找所有30岁的用户时,先通过
SMEMBERS users:age:30拿到所有用户ID。 - 然后根据这些ID,
user:1和user:2,再用HGETALL去逐个取出完整的用户信息。
- 当你想找所有30岁的用户时,先通过
- 更高级的索引: 如果你的查询条件是“年龄在25到35岁之间”,Set就不好用了,这时可以用有序集合(Sorted Set)。
- 创建一个ZSet,比如叫
users:age:score。 - 添加成员时,把用户ID作为成员,年龄作为分数(score):
ZADD users:age:score 30 1(分数30,成员是用户ID“1”)。 - 查询时,用范围查询:
ZRANGEBYSCORE users:age:score 25 35,就能直接拿到所有ID在25到35之间的用户ID列表。
- 创建一个ZSet,比如叫
- 优点: 实现了复杂的查询条件,查询速度很快。
- 缺点: 增加了存储空间,并且写数据时要多一步操作来维护索引,需要保证数据一致性。
第三种搞法:整个表塞进一个结构里(不推荐,但小数据量可行)。
对于一些数据量极小、而且你总是需要一次性读取整个表的场景,有个“懒人”方法。
- 存储: 把整个表格数据序列化成JSON字符串,然后直接用String结构存到一个Key里。
SET user_table '[{"id":1, "name":"张三"}, {"id":2, "name":"李四"}]' - 操作:
- 读取:
GET user_table,然后把拿到的字符串在你的程序里解析成数组或列表对象。 - 修改:非常麻烦!你必须先GET整个字符串,在程序里解析、修改、再序列化成字符串,最后SET回去,这个过程不是原子性的,并发操作会出问题。
- 读取:
- 优点: 简单粗暴,一次取全部。
- 缺点: 性能极差,无法局部更新,并发危险,数据量稍大就不可行,除非是配置信息之类几乎不变的数据,否则慎用。
总结一下操作那些事儿:
- 增删改查(CRUD): 核心是靠Hash处理单行,靠Set/ZSet处理查询。
- 事务和原子性: 如果你需要同时更新Hash和对应的索引,为了保证数据一致(比如更新年龄的同时,要把用户ID从旧的年龄索引Set移到新的年龄索引Set),可以使用Redis的
MULTI/EXEC命令开启一个事务,确保几个命令一起成功或失败。 - 关于联表查询: Redis本身基本不具备联表查询的能力,这种复杂逻辑必须在你的应用程序里完成,比如先从一个表查出一些ID,再根据这些ID去另一个表里查数据,然后在程序内存里进行关联计算。
最后给你几点实在的建议(来自实践经验总结):
- 别把Redis当数据库用: 绝大多数情况下,Redis应该作为缓存使用,用来加速热点数据的访问,原始、完整的数据还是应该存在MySQL、PostgreSQL这样的关系型数据库或者其它NoSQL数据库中,Redis里的数据可以看作是源数据的一个“快照”或“视图”。
- 想清楚你要怎么查数据: 在设计Redis数据结构前,先问自己:“我后面会按哪些条件来查询这些数据?” 根据查询需求来反推需要建立哪些Key和索引,这就是所谓的“查询导向设计”。
- 处理好数据同步: 如果你的源数据库(比如MySQL)里的数据变了,Redis里的数据要及时更新或失效删除,否则就会读到脏数据,常见的策略有设置过期时间、或在更新数据库后主动更新/删除Redis缓存。
希望这些大实话能帮你搞清楚在Redis里处理表格数据的门道,工具是死的,人是活的,选择最适合你业务场景的那一种“搞法”就行。

本文由芮以莲于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75870.html