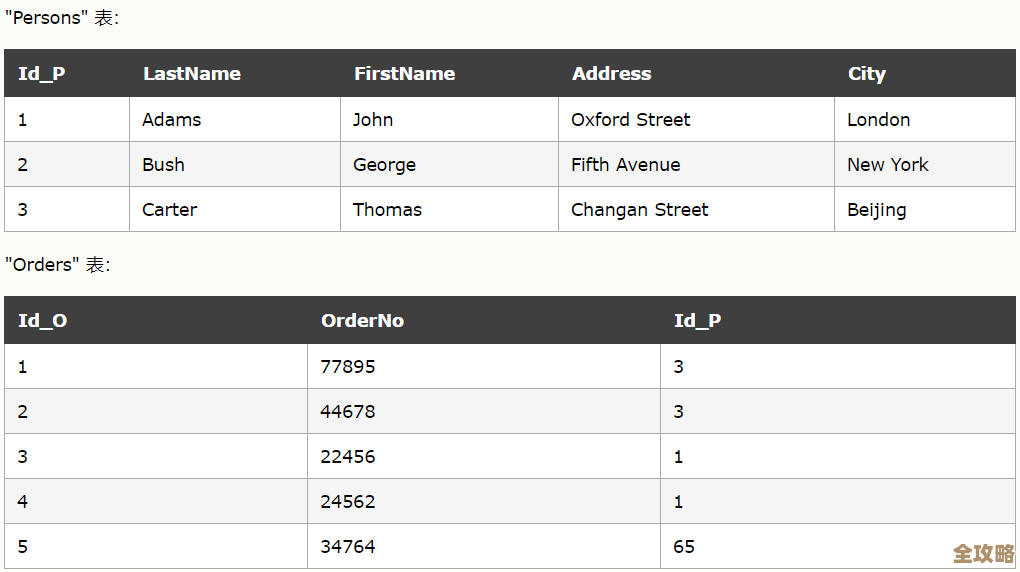
C语言怎么快速搞定Oracle里一堆数据批量导入,省事又高效的办法分享

说到把一大堆数据从别的地方倒腾到Oracle数据库里,用C语言来做,听起来好像有点老派,但关键时刻确实顶用,特别是当你面对那些用现成工具搞不定的特殊情况,或者需要在程序里深度定制这个导入过程的时候,想又快又省事,核心就一句话:尽量减少跟数据库“打招呼”的次数。 每次执行SQL语句,数据库那边都得忙活一阵子(解析啊、优化啊什么的),次数一多,时间就全耗在这上面了,我们的目标是把好多好多次“打招呼”,变成一次或者很少几次“批量打招呼”。
最核心、最推荐的省事高效办法,就是玩转Oracle提供的批量处理功能,这可不是让你用C语言写个循环,一条一条地INSERT,那速度能急死人,有下面几个实操性很强的招数:
第一招:用OCI的数组接口,实现批量插入(Array Interface)
这是Oracle官方推荐的狠招,也是性能提升最明显的,OCI是Oracle自家的一套用C语言操作数据库的底层接口,虽然学起来比那些封装好的库要麻烦点,但为了速度,值得。
- 怎么搞: 简单说,就是你不再一次准备一条
INSERT语句,而是准备一条带“占位符”的语句,比如INSERT INTO 你的表名 (列1, 列2) VALUES (:1, :2),关键来了,你不是把一个数据值绑定到:1和:2上,而是在C语言里定义两个数组,分别对应列1和列2要插入的所有数据,通过OCI的函数,把这一整个数组一次性绑定到那个占位符上,执行语句的时候,告诉OCI:“我这次要一次性处理数组里所有的数据(比如1000条)”,数据库那边收到的是一个“数据包”,它集中处理这一大批数据,效率自然飙升。 - 为啥快: 网络通信次数暴降,数据库内部的事务处理开销也大幅减少(你可以设置每隔多少条数据提交一次事务,而不是每条都提交),根据Oracle官方文档和一些技术社区的分享(比如Oracle官方文档中的“OCI Programmer's Guide”里关于批量操作的章节,或者一些技术博客像“Oracle Base”上关于批量数据加载的文章),相比单条插入,性能提升几十倍甚至上百倍都是可能的。
- 小提示: 你需要去官网下载Oracle的OCI开发包,并在C代码里链接对应的库,数组的大小(一次处理多少条)可以调优,太大了可能占内存,太小了效果不明显,一般从100到1000条开始试都行。
第二招:如果非要用ProC,也请用它的批量功能(ProC WITH HOST ARRAYS)
ProC是Oracle的另一种C语言扩展,它允许你把SQL语句直接写在C代码里,然后用个预处理器处理一下,再编译,如果你本来就用的ProC,那也别傻傻地单条插入了。
- 怎么搞: 思路和OCI数组接口很像,在ProC里,你可以声明宿主变量为数组,比如
char 列1数组[1000][50]; int 列2数组[1000];,然后在嵌入的SQL语句中,使用FOR子句来指定循环次数(也就是数组大小),像这样:EXEC SQL FOR :循环次数 INSERT INTO 你的表名 (列1, 列2) VALUES (:列1数组, :列2数组);,这样,ProC预处理器会帮你生成批量操作的代码。 - 为啥快: 原理同上了,还是批量处理的优势,这在ProC的官方手册“ProC/C++ Programmer's Guide”里有详细说明,算是对Pro*C用户比较友好的一种批量方式。
第三招:终极武器——生成外部表用的文件,然后让Oracle直接读(External Tables + C程序)
这招可能是最“狡猾”也最省数据库资源的,你不是用C语言处理数据吗?好,咱不直接跟数据库的INSERT较劲了。
- 怎么搞: 用C程序把你手里的那堆数据,按照一个固定的格式(比如用逗号隔开的CSV,或者用竖线隔开)写到一个或多个文本文件里,这个过程就是纯粹的C语言文件读写,速度飞快,在Oracle数据库那边,你创建一个“外部表”,这个外部表的结构和你那个文本文件的结构一模一样,你通过建表语句告诉Oracle:“这个表的数据不在我数据库里,就在服务器上某个位置的文本文件里,格式是啥样的”,创建好后,你就可以像查询普通数据库表一样用SQL来查询这个文本文件里的数据了!
- 接下来怎么导入: 既然数据已经能通过外部表被Oracle认得了,最后一步就简单了,你只需要在Oracle内部执行一条SQL:
INSERT INTO 你最终的目标表 SELECT * FROM 你创建的那个外部表,这样,数据就从文件被快速地挪到了真正的数据库表中,你甚至可以在SELECT的时候做一些数据清洗和转换。 - 为啥又快又省事: 这个方法把最耗时的“插入”动作,转化成了数据库高效的批量加载操作(Oracle内部会用类似
SQL*Loader直接路径加载的技术),你的C程序只负责生成格式规整的文件,压力小了很多,这个方法在很多数据库优化案例和DBA的经验分享中(比如AskTOM网站上有不少关于外部表性能的讨论)都被视为处理海量初始数据加载的利器,不过要注意,这个文本文件需要放在Oracle数据库服务器能直接访问到的路径下。
一些通用的省事小技巧:
不管你用上面哪一招,下面几点都能帮你更顺溜:
- 关掉自动提交: 在开始批量导入前,一定要确保数据库连接是手动提交事务的模式,然后每插入一定数量(比如一万条)再手动提交一次,避免每插一条就提交一次,那会慢得让你怀疑人生。
- 调整一下数据库参数: 如果数据量真的巨大,可以临时增大数据库的
PROCESSES、SESSIONS以及回滚段的大小,防止导入过程中报错,这个可能需要DBA帮忙。 - 预处理数据: 在C程序里,尽量先把数据弄干净,比如去掉多余的空格、处理好编码问题,确保数据格式和数据库表结构严格匹配,减少导入时出错的概率。
- 错误处理要跟上: 批量操作万一出错,可能就是一大批数据,你的C代码里要做好异常捕获,记录下出错的位置和原因,方便后续排查和补录。
用C语言快速搞定Oracle批量导入,首选OCI的数组接口,性能最好;如果环境限制用Pro*C,记得启用它的宿主数组功能;如果对流程控制要求不那么死板,生成文件配合Oracle外部表往往是更轻松、对数据库压力更小的选择,核心思想就是“化零为整”,避免蚂蚁搬家式的操作,希望这些实实在在的招数能帮你省下不少时间。

本文由盈壮于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75573.html