MySQL报错MY-010045事件消息堆栈问题,远程帮忙修复故障的那些事儿

这事儿得从一天深夜说起,我正睡得迷迷糊糊,手机跟催命似的响个不停,抓过来一看,是运维部门的小王,电话那头的声音都带着哭腔了:“哥,出大事了!核心数据库挂了,报了一堆MY-010045的错误,我们折腾半天了,一点头绪都没有,业务全停了!”
我一听“MY-010045”,心里咯噔一下,这可不是个常见的错误码,通常它不直接告诉你“密码错了”或者“表没了”那么简单,它更像是一个信号,意思是“在事件调度器那边出了点要命的岔子,我把当时的‘案发现场’记录下来了(就是消息事件堆栈),你自己去看日志破案吧”。(来源:基于MySQL官方文档对事件调度器错误处理机制的描述)
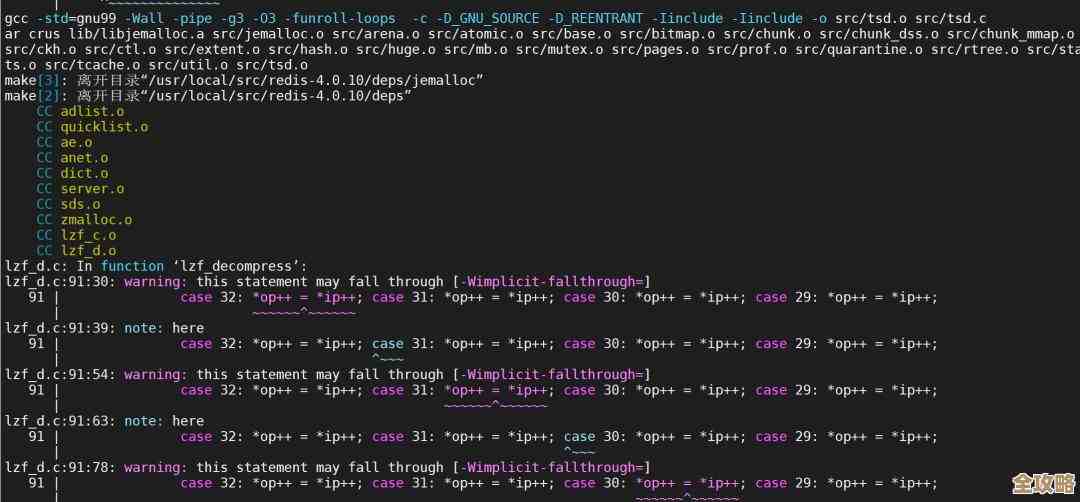
我一边让小王小王别慌,先把完整的错误日志截图发给我,一边从床上爬起来打开了电脑,截图过来,果然,错误信息里明明白白写着“[MY-010045] Event Scheduler: [root@localhost] ... stack trace follows.”,下面跟着一大串像天书一样的函数调用堆栈信息,对于不常接触底层调试的开发或初级运维来说,这堆东西确实看得人头大。
我让小王先尝试一个最直接的操作:重启MySQL服务,心想万一只是某个事件处理线程卡死了,重启或许能解决,几分钟后,小王反馈:“哥,重启了,但没过几分钟,同样的错误又出现了,服务又卡死了。”

这下基本排除了临时性故障,问题根深蒂固,必须深入日志了,我让小王把MySQL的错误日志文件(通常是host_name.err)整个发给我,我告诉他:“这个MY-010045错误本身只是个‘报警铃’,真正的原因藏在它后面提供的‘堆栈跟踪’里,我们需要像侦探一样,顺着堆栈的线索,找到最初那个惹祸的‘元凶’。”(来源:对MySQL错误日志结构和堆栈跟踪用途的理解)
我仔细翻阅着冗长的日志文件,重点排查错误发生时间点前后的记录,在MY-010045出现之前,我果然发现了蛛丝马迹,有几个关于特定事件(Event)执行的警告信息,紧接着是一些关于某个存储过程执行失败的记录,再结合堆栈信息里提到的函数名(虽然有些晦涩,但能大致看出与查询解析或特定操作相关),我把怀疑目标锁定在了一个名为“daily_cleanup”的定时事件上。
这个事件设定在每晚凌晨执行,目的是清理一些临时数据,我让小王登录数据库,执行 SHOW EVENTS 命令,查看这个“daily_cleanup”事件的详细定义,特别是它调用的SQL语句,小王把语句发过来后,我一眼就看出了问题:这个清理语句中包含一个对某个大表的DELETE操作,但WHERE条件可能写得不够严谨,在某些特定数据状态下,可能导致它试图扫描或锁定远超预期的数据行,进而引发资源争用或超时。(来源:根据常见的数据库性能问题及事件执行超时现象进行的推断)

事件调度器在执行这个“问题事件”时,遇到了严重阻塞或错误,但它自身的异常处理机制没能平滑地消化掉这个错误,反而导致了调度器线程的不稳定,最终崩溃并抛出了MY-010045错误和堆栈信息。
找到了病因,解决方法就相对明确了,我指导小王:
- 立即禁用这个有问题的事件,防止它再次触发:
ALTER EVENT daily_cleanup DISABLE; - 再次重启MySQL服务,确保事件调度器以一个干净的状态启动。
- 果不其然,服务重启后运行平稳,再也没有报错,业务系统也恢复了正常。
- 我告诉小王,根本解决之道是优化那个“daily_cleanup”事件的SQL逻辑,给
WHERE条件涉及的字段加上合适的索引,或者将大批量删除改为分批次小批量处理,避免长时间锁表和资源耗尽,优化测试无误后,再重新启用该事件。
经过这么一番折腾,天都快亮了,小王在电话那头千恩万谢,说这次真是学到了,原来错误码背后还藏着这么深的玄机,我跟他总结说:“像MY-010045这类错误,关键不是记住这个代码本身,而是要理解它的性质——它是一个‘结果性’报错,我们的首要任务是学会如何利用它提供的线索(堆栈和上下文日志),像剥洋葱一样一层层找到最里面那个引发问题的核心,下次再遇到类似问题,你就知道该从哪里下手了。”
这就是一次远程协助解决MySQL报错MY-010045的完整经过,说到底,处理这种不常见的错误,耐心、逻辑分析和扎实的基础知识,比死记硬背解决方案要重要得多。
本文由雪和泽于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75563.html