云原生那些工具挺多,能帮你快点把软件弄上线,省心又高效

行,既然你问了,那我就不绕弯子,直接聊聊那些在云原生世界里,真能让你省心省力、快点把软件搞上线的工具,这些东西不是什么高深莫测的魔法,说白了就是一套套现成的“好帮手”,帮你把开发、测试、打包、上线这些麻烦事给自动化、流程化了。
容器:把你的软件和它的“家当”打包成一个箱子
想象一下,你要搬家,最怕啥?最怕搬到新家发现有个东西忘带了,或者新家的环境不对,东西用不了,传统软件部署就这德行,经常因为测试环境和生产环境(就是线上真实跑的环境)不一样,导致各种灵异问题。
这时候,Docker 这东西就派上用场了,它就像一个标准化的、万能的搬家纸箱,你用 Docker 可以把你的软件代码、它需要的系统库、环境配置、甚至它依赖的其他软件,统统打包进一个叫“镜像”的箱子里,这个箱子在任何安装了 Docker 的机器上(无论是你的笔记本,还是云上的大服务器),打开就能运行,运行起来的样子跟你打包时一模一样,这就彻底解决了“在我这儿好好的,怎么到你那儿就不行了”的千古难题,这是你能“省心”的第一步,也是最基础的一步,来源:Docker 官方文档的核心思想。

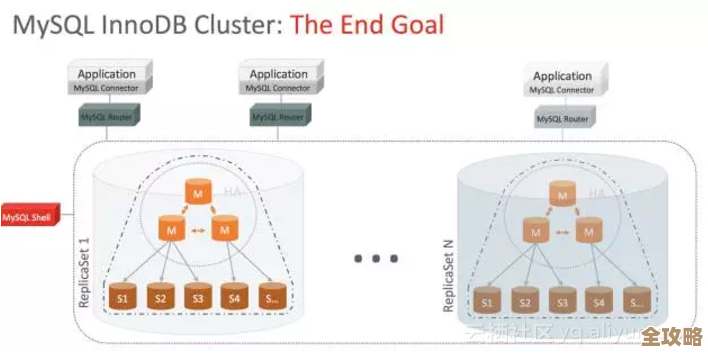
编排工具:从管一个箱子到管一个集装箱码头
Docker 解决了单个应用打包的问题,但现实中的软件,尤其是稍微复杂点的,都不是一个箱子能搞定的,比如一个网站,可能有前端页面、后端服务、数据库、缓存服务等等,得好几个箱子(容器)一起协作才行,你怎么管理这么多箱子?比如哪个箱子挂了要自动重启?流量大了要自动多开几个箱子?版本更新的时候怎么做到不停机平滑升级?
这时候,你就需要一个“集装箱码头调度系统”,也就是容器编排工具,这里面,Kubernetes(简称 k8s)基本上是现在的行业标准,你可以把它想象成一个超级智能的码头总管,你只需要告诉 k8s:“我要一个前端服务,给我跑 3 个副本;还要一个后端服务,跑 2 个副本;它们之间要能互相通信。” k8s 就会自动在它管理的服务器集群里找地方把这些容器跑起来,7x24 小时盯着它们,万一哪个容器崩溃了,k8s 会自动重启一个新的;如果流量突然暴增,你可以很方便地命令 k8s 多开几个前端容器来分担压力,这套机制让你从手动管理一堆虚拟机的苦力活里解放出来,大大提升了管理和扩展的效率,来源:Kubernetes 官网对其功能的概述。
CI/CD 流水线:让代码一提交,就自动奔向生产线

这是实现“快点上线”的核心环节,CI/CD 翻译过来就是持续集成和持续部署,这又是个啥呢?想象一个全自动的汽车组装流水线。
- 持续集成: 你的程序员同事每写一段新代码,提交到代码仓库(GitHub、GitLab),这个流水线就自动启动了,它会自动把新代码拉过来,编译打包(比如打成 Docker 镜像)、运行一系列自动化测试(单元测试、集成测试),如果测试通过了,说明这次代码提交是没问题的,可以放心集成到主代码库里,这避免了所有人攒了一大堆代码最后合并时冲突爆炸的惨剧。
- 持续部署/交付: 如果持续集成阶段通过了,流水线可以更进一步,自动把这个新打包好的镜像部署到测试环境甚至生产环境,这就意味着,开发人员提交代码后,可能只需要点个按钮,或者完全不用管,过一会儿新功能就已经悄无声息地上线了。
常用的工具有 Jenkins、GitLab CI/CD、GitHub Actions 等,它们就像是这个流水线的总控台,用了这套东西,软件发布的频率可以从以前的“按月”甚至“按年”,变成“按周”、“按天”,真正实现了快速迭代,你再也不用熬夜搞上线了,省心程度直接拉满,来源:对 Jenkins、GitLab CI/CD 等工具普遍功能的描述。
服务网格:微服务之间的“智能交通指挥系统”
当你用上了容器和 k8s,很容易就会把一个大应用拆分成很多个小服务(这就是微服务架构),服务多了,它们之间的通信就变成了一个复杂的网络,服务 A 要调用服务 B,怎么保证调用是可靠的?怎么知道服务 B 是否健康?如果想测试新版本的服务 B,只让一小部分流量过去试试水(这叫金丝雀发布)该怎么搞?

服务网格,Istio 或 Linkerd,就是干这个的,它不像一个具体的工具,更像是在你的微服务网络里嵌入了一个透明的“交通指挥系统”,你不用修改服务本身的代码,这个网格就能帮你管理服务间的通信,实现负载均衡、故障恢复(比如一个服务调用失败自动重试)、流量切分、安全加密等等,它把那些跨服务的、通用的网络管理问题从业务代码里抽离出来,让你更专注于业务逻辑本身,这也是另一种形式的“省心”,来源:Istio 官网对其概念的介绍。
监控日志:给你的软件装上“行车记录仪”和“健康手环”
软件上线了可不是就完事了,你得知道它跑得好不好,这时候你需要监控和日志工具。
- 监控: 像 Prometheus 这样的工具,会持续不断地抓取你各个服务的运行指标,CPU 用了多少、内存还剩多少、接口的响应时间多长、每秒处理多少请求,它就像个 24 小时在线的健康手环,一旦发现哪个服务指标异常(CPU 持续 100%),立马报警。
- 日志: 像 ELK Stack(Elasticsearch, Logstash, Kibana)或 Loki,负责集中收集所有服务产生的日志,当线上出现问题时,你就不用一台服务器一台服务器地去翻日志了,可以直接在这个日志系统里快速搜索、分析,像查数据库一样查日志,迅速定位问题根源,这玩意儿就是你的行车记录仪,出了事一查就明白。
有了这些可观测性工具,你才能心里有底,才能快速发现问题、解决问题,保证线上服务的稳定高效,这也是“省心”不可或缺的一部分,来源:Prometheus 和 ELK Stack 项目官方介绍。
所以你看,这一套工具链下来,从打包(Docker)、到编排管理(Kubernetes)、到自动化上线(CI/CD)、再到运行时的网络管理和监控(服务网格、Prometheus),它们各司其职,环环相扣,它们的目标都是一致的:把软件开发和运维中那些重复、繁琐、容易出错的手工操作,变成自动化、标准化的流程,最终让你能更专注于写代码实现业务功能,而不是折腾环境,从而真正实现“快点把软件弄上线,省心又高效”。
本文由颜泰平于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75358.html