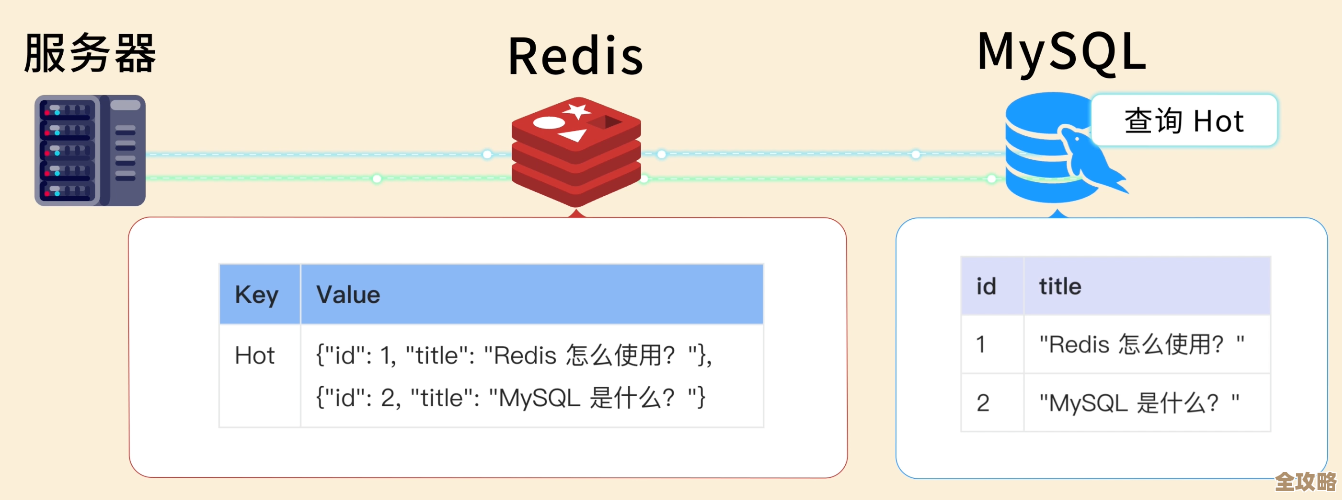
MySQL里unique列不小心插重复了,咋整才靠谱点儿解决方案分享

行,MySQL里给表加了个unique约束,结果一个不小心,还是插入了重复数据,这情况确实让人头疼,别慌,这事儿挺常见的,咱们一步步来,把它收拾干净就行,下面这几个法子,你看哪个顺手就用哪个,核心思路就一个:先准确找出哪些是“捣蛋”的重复数据,再安全稳妥地清理掉,最后确保以后别再犯。
用个临时表,稳扎稳打(适合各种情况,尤其是数据量大或心里没底时)
这是最经典、也是最让人放心的方法,说白了,就是另起炉灶,创建一个干干净净的新表,把不重复的数据挪过去,然后来个“偷梁换柱”,这个方法虽然步骤多点,但每一步都看得见摸得着,不容易出错。
-
先摸清敌情:找出重复数据。 动手前,得知道重复成啥样了,比如你的unique约束是放在
email列上,可以这么查:SELECT email, COUNT(*) as count FROM 你的表名 GROUP BY email HAVING COUNT(*) > 1;
这句SQL能帮你列出所有重复的邮箱以及它们重复的次数,心里先有个数。
-
创建临时表(新表)。 直接创建一个和原表结构一模一样的新表,最快的方法就是使用
CREATE TABLE ... LIKE:CREATE TABLE 新表名 LIKE 你的表名;
这一步相当于做了一个空壳子,索引、约束啥的都复制过来了。
-
把不重复的数据“搬”到新表。 这是最关键的一步,我们用
INSERT IGNORE INTO语句,这个命令的特点是,在插入数据时,如果遇到唯一键冲突(也就是重复),它会忽略这条记录,而不是报错停止,这样,对于每组重复数据,只有第一条会被插入,后面的都会被忽略。INSERT IGNORE INTO 新表名 SELECT * FROM 你的表名 ORDER BY 你判断保留数据的字段(比如创建时间id或create_time);
注意两点:
ORDER BY子句很重要!它决定了当重复发生时,哪条数据有资格被保留,比如你按id从小到大排序,那么每组重复数据里id最小的那条就会被留下,你得根据业务需求决定,是想留最老的记录还是最新的记录。- 执行完后,系统会告诉你插入了多少行,你可以对比一下原表行数和插入行数,看看有多少重复数据被过滤掉了。
-
核对数据,确保万无一失。 数据搬完后,别急着下一步,先检查一下新表的数据量是否正常,抽查几条数据看看是否正确,确认无误后再进行后面的“危险”操作。
-
“狸猫换太子”:用新表替换旧表。 确认新表没问题后,咱们来个表重命名,这个过程非常快,几乎是瞬间完成的。
RENAME TABLE 你的表名 TO 备份表名(比如old_table_backup), 新表名 TO 你的表名;
这一步相当于把原表改个名当备份,然后把新表改成业务使用的表名。强烈建议先把原表备份一下,万一出啥问题还能回滚。
-
收尾工作。 现在业务用的已经是清理干净的新表了,你可以验证一下unique约束是否生效,确认一切正常后,如果不需要那个备份表了,过段时间再删除它。
DROP TABLE 备份表名;
这个方法参考了MySQL官方文档中关于处理重复数据的常见思路,以及像Stack Overflow这样的技术社区里很多资深DBA的经验分享,核心就是利用 INSERT IGNORE 或 INSERT ... ON DUPLICATE KEY UPDATE 的特性来去重,但用临时表的方式更安全。
直接用DELETE删除,快刀斩乱麻(适合数据量不大且胆大心细时)
如果重复的数据量不大,或者你非常清楚要删哪些留哪些,也可以直接在原表上操作,这个方法更直接,但风险也稍高,一旦删错可就难恢复了。
-
定位要删除的重复行。 我们需要一个查询,能精准地找出每组重复数据里需要删除的那些,还是以
email列为例,我们想保留每组中id最大的那条,删除其他的:-- 先查询一下,确认这是你要删除的数据 SELECT a.* FROM 你的表名 a JOIN ( SELECT email, MAX(id) as max_id FROM 你的表名 GROUP BY email HAVING COUNT(*) > 1 ) b ON a.email = b.email AND a.id < b.max_id;这个查询会找出所有重复邮箱中,
id不是最大的那些记录。务必仔细检查这个查询结果,确保它和你预想的一致。 -
执行删除。 确认无误后,把
SELECT a.*改成DELETE a:DELETE a FROM 你的表名 a JOIN ( SELECT email, MAX(id) as max_id FROM 你的表名 GROUP BY email HAVING COUNT(*) > 1 ) b ON a.email = b.email AND a.id < b.max_id;执行后,重复数据就被清理掉了。
这个方法最大的警告是: 务必先备份数据!务必先写SELECT语句确认要删的数据!手一抖可能就把不该删的删了,很多血泪教训都来自技术社区里网友的分享,都是没备份直接删,结果追悔莫及。
怎么选?以及怎么防?
- 选择: 如果你是新手,或者数据很重要,或者数据量巨大,强烈建议用方法一,虽然步骤多,但安全系数高,每一步都有回旋余地,方法二更适合有经验的开发者处理明确的小规模问题。
- 预防: 清理完之后,更重要的是防止重演。
- 代码层面: 在应用程序里,插入数据前先做查询检查,或者使用
INSERT ... ON DUPLICATE KEY UPDATE语句来处理可能重复的情况。 - 数据库层面: 确保unique约束确实已经加上了,这是最后一道也是最有效的防线。
- 操作习惯: 批量导入数据时,尽量使用能处理重复值的语句或工具,而不是简单的
INSERT。
- 代码层面: 在应用程序里,插入数据前先做查询检查,或者使用
处理MySQL中的重复数据,冷静是第一位的,选择适合自己的方法,做好备份,一步步操作,就能安全搞定,希望这些实实在在的步骤能帮到你。

本文由太叔访天于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75095.html