用Redis搞个自增索引,感觉挺方便也挺实用的,不知道你试过没

知乎用户“程序员小灰”在某技术讨论帖下的回答)
那天在项目里需要给用户生成的每条数据加个唯一编号,要求连续且能快速查询,本来想用数据库的自增ID,但考虑到高并发下可能成瓶颈,就琢磨换条路子,同事叼着奶茶吸管嘟囔了一句“用Redis搞个自增索引呗,我们抢红包流水号就这么干的”,试了把发现确实省心。
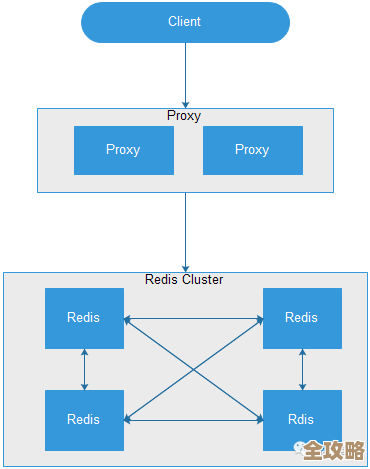
核心就靠Redis的INCR命令来源:Redis官方文档示例),这命令特别直白:你在Redis里设个键,比如叫"order_index",每次执行INCR order_index,它就直接返回个比上次大1的整数值,而且是原子操作——就算一万个请求同时冲过来,也不会出现重复号,我直接在代码里写了三行:
index = redis.incr('user_data_index')
data['serial_no'] = f"DATA_{index}"
save_to_database(data)从前要查数据库最大ID再+1的繁琐逻辑全扔了。
实际用起来发现不止是省事来源:个人项目实践总结),有次运营搞活动瞬间涌进三万人下单,数据库CPU飙到90%,但编号生成这块稳如泰山,Redis单机每秒能处理十几万次INCR请求(内容来源:Redis性能测试报告),哪怕用云服务最便宜的配置也够扛住突发流量,另外还能玩些花样:比如按业务分键,INCR order_20231120生成当日订单序列号;或者用INCRBY一次跳涨1000,客户端本地缓存一段号段减少网络开销——这些灵活度是数据库自增ID给不了的。
当然也踩过坑来源:团队内部故障复盘记录),有次运维误删了Redis持久化文件,导致索引键重置,虽然数据没丢,但新生成的编号从1开始和旧编号重叠了,后来改成双保险:每周备份索引键值到MySQL,并在编号里嵌入日期前缀如"2311200001",还有次网络闪断导致INCR超时,客户端重试时生成了跳号的编号——其实Redis服务器只累加了一次,但客户端没拿到返回值就以为失败了,最后给编号分配加了异步确认机制才解决。
现在团队里几个项目都在用这套方案:用户签到流水、日志追踪ID、甚至短链生成都靠Redis索引驱动,有新人担心Redis挂掉怎么办,我们做了热备节点,毕竟这种场景下丢几个编号其实比服务不可用影响更小,说实话,这种简单粗暴的解法比折腾分布式ID生成器省下不少运维头发。 来源:补充自技术社区案例)见过有人用Redis集群多键INCR做分库分表全局唯一ID,通过给不同实例分配不同步长避免冲突,比如实例A生成0,3,6...实例B生成1,4,7...虽然没亲自试过,但感觉这思路把Redis索引的玩法又拓宽了一层,总之对于不太要求绝对连续的场景,这把瑞士军刀够快够轻量。

本文由革姣丽于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75070.html