配置Oracle RAC时遇到各种问题,教你怎么一步步解决那些麻烦事儿

(引用来源:基于Oracle官方文档、Oracle Support知识库文章以及社区实践经验总结)
配置Oracle RAC(Real Application Clusters)确实是个技术活儿,就算你照着文档一步步来,也常常会碰到各种意想不到的麻烦,下面我就把一些常见的问题和解决思路给你捋一捋,希望能帮你少走点弯路。
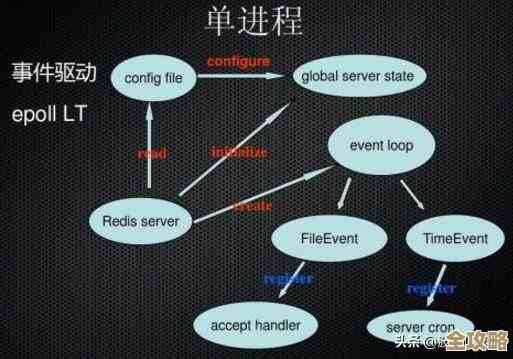
集群软件安装就卡住了,网络检查通不过
这可能是最常遇到的第一个坎儿,你兴冲冲地运行Oracle Grid Infrastructure安装程序,结果在“先决条件检查”那一步,它就报红了,尤其是网络检查那块。
- 具体表现:安装程序提示“网络配置不满足要求”,比如私有网络的网卡没有正确配置、子网掩码不对、或者SCAN(Single Client Access Name)解析有问题。
- 怎么一步步解决:
- 先别急着点“忽略”:虽然安装程序允许你忽略某些警告,但对于网络问题,强烈建议你彻底解决,否则后面会出大乱子。
- 核对hosts文件:在两台(或多台)服务器的
/etc/hosts文件中,确保为每个节点配置了三个地址:公有IP地址、私有IP地址和虚拟IP(VIP)地址,格式要规范,别写错了。# 公有IP 192.168.1.101 node1 192.168.1.102 node2 # 私有IP 10.10.10.1 node1-priv 10.10.10.2 node2-priv # 虚拟IP (VIP) 192.168.1.201 node1-vip 192.168.1.202 node2-vip - 检查SCAN解析:SCAN名字应该在DNS服务器上做轮询解析,指向三个IP地址(这三个IP需要提前在网络上预留并配置好),如果测试环境没有DNS,可以在每个节点的
/etc/hosts文件里临时写一条记录,但不推荐在生产环境这么做,因为这会失去SCAN的高可用性,你可以用nslookup your_scan_name命令来测试解析是否正确。 - 验证网络连通性:用
ping命令确保所有节点之间都能通过公有主机名、私有主机名、VIP主机名互相ping通,特别是私有网络,要确保延迟低且稳定,没有丢包。
共享存储认不出来或者权限不对
RAC的核心就是多个节点能同时读写同一份数据库文件,所以共享存储(比如SAN、NAS或ASM磁盘组)的配置是关键。
- 具体表现:安装过程中,在配置ASM磁盘组时,发现“候选磁盘”列表是空的;或者虽然看到了磁盘,但创建磁盘组时提示权限不足或路径错误。
- 怎么一步步解决:
- 多路径配置:如果服务器通过多条光纤链路连接存储,必须正确配置多路径软件(如Linux上的DM-Multipath),确保操作系统看到的是统一的、经过聚合的磁盘设备(如
/dev/mapper/mpathX),而不是多条路径对应的多个原始设备,否则ASM会认为这是多个不同的磁盘,导致混乱。 - 权限和所有者:确保这些共享磁盘设备的所有者和组是安装Grid Infrastructure的软件所有者(通常是
grid:oinstall),使用ls -l /dev/mapper/mpath*命令检查,如果不是,需要用chown和chmod命令修改权限。 - 使用ASMLib还是UDEV:在Linux上,Oracle推荐使用ASMLib或UDEV规则来持久化绑定磁盘设备,UDEV是现在更通用的方法,你需要为每个共享磁盘创建UDEV规则,确保每次重启后,磁盘的设备名和权限都是固定的,网上有很多具体的UDEV规则配置示例,照着做就行,关键是保证规则能正确匹配到你的共享磁盘。
- 让ASM识别:配置好权限和UDEV后,以grid用户身份运行
asmcmd scandisks命令,然后再次用asmcmd lsdsk查看,应该就能看到候选磁盘了。
- 多路径配置:如果服务器通过多条光纤链路连接存储,必须正确配置多路径软件(如Linux上的DM-Multipath),确保操作系统看到的是统一的、经过聚合的磁盘设备(如
集群明明装好了,但创建数据库时节点间通信失败
有时候Grid Infrastructure安装得很顺利,各个服务也起来了,但当你用DBCA(Database Configuration Assistant)创建数据库时,却报错说无法在另一个节点上启动实例。
- 具体表现:DBCA日志或alert日志中可能出现类似“ORA-29740: 实例已与通信域连接,但其他实例尚未连接”或网络超时类的错误。
- 怎么一步步解决:
- 检查集群状态:用
crsctl status cluster -all命令确认所有节点的集群服务都是在线(ONLINE)状态,再用crsctl status resource -t仔细查看每个资源(特别是网络相关的VIP、SCAN监听器、节点应用)是否都健康运行。 - 深挖私有网络:这个问题十有八九还是出在私有网络上,虽然之前ping通了,但可能存在不稳定的抖动或高延迟,你可以使用
ping -s 65507 目标节点私有IP命令(发送大包)持续ping一段时间,观察是否有丢包或响应时间剧烈波动,私有网络应该使用专用的、高性能的交换机和网线,避免与其他业务网络流量混杂。 - 检查时间同步:RAC节点之间的系统时间必须高度同步(误差通常要求在秒级以内),虽然Oracle Clusterware会尝试同步,但最好配置一个外部的NTP(Network Time Protocol)服务器,让所有节点都从同一时间源同步,用
date命令对比两个节点的时间,看差异是否在允许范围内。 - 查看集群日志:到Grid Infrastructure的家目录下的
log/<节点主机名>目录里,查看alert<节点主机名>.log和crsd.log等日志文件,寻找在出错时间点附近的警告或错误信息,这些是定位问题的关键线索。
- 检查集群状态:用
数据库运行一段时间后,某个节点突然被踢出集群
这叫“节点驱逐”(Node Eviction),是RAC的一种自我保护机制,但发生的时候很吓人。
- 具体表现:一个或多个节点的数据库实例突然关闭,集群日志显示该节点被“驱逐”了。
- 怎么一步步解决:
- 首要任务:查看日志:立即查看被踢出节点的
alert<节点主机名>.log和集群的cssd.log文件,里面通常会明确记录驱逐的原因,心跳丢失”(Network heartbeat failure)或“磁盘心跳失败”(Disk heartbeating failed)。 - 网络心跳丢失:如果原因是网络心跳,回头彻底检查私有网络的硬件(网卡、交换机、网线)和配置,可能是网络瞬间拥塞、网卡驱动有bug或交换机端口故障。
- 磁盘心跳丢失:如果原因是磁盘心跳,说明所有节点都无法在预期时间内写入投票盘(Voting Disk),这说明共享存储的I/O路径出现了严重问题,检查存储控制器、光纤交换机、HBA卡是否正常,是否存在路径切换延迟过高的情况。
- 系统资源不足:也可能是由于操作系统内存不足、SWAP空间用尽、或CPU被耗尽,导致集群守护进程无法及时响应心跳,检查系统资源使用情况的历史记录。
- 首要任务:查看日志:立即查看被踢出节点的
解决RAC的问题,日志是你最好的朋友,一定要养成第一时间查看、分析相关日志的习惯,对网络和共享存储的稳定性投入百分之百的精力去保障,这两样是RAC的命根子,它们一旦出问题,RAC的各种奇怪现象就会接踵而至,希望这些实际的麻烦事儿和解决思路能对你有所帮助。

本文由太叔访天于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75035.html