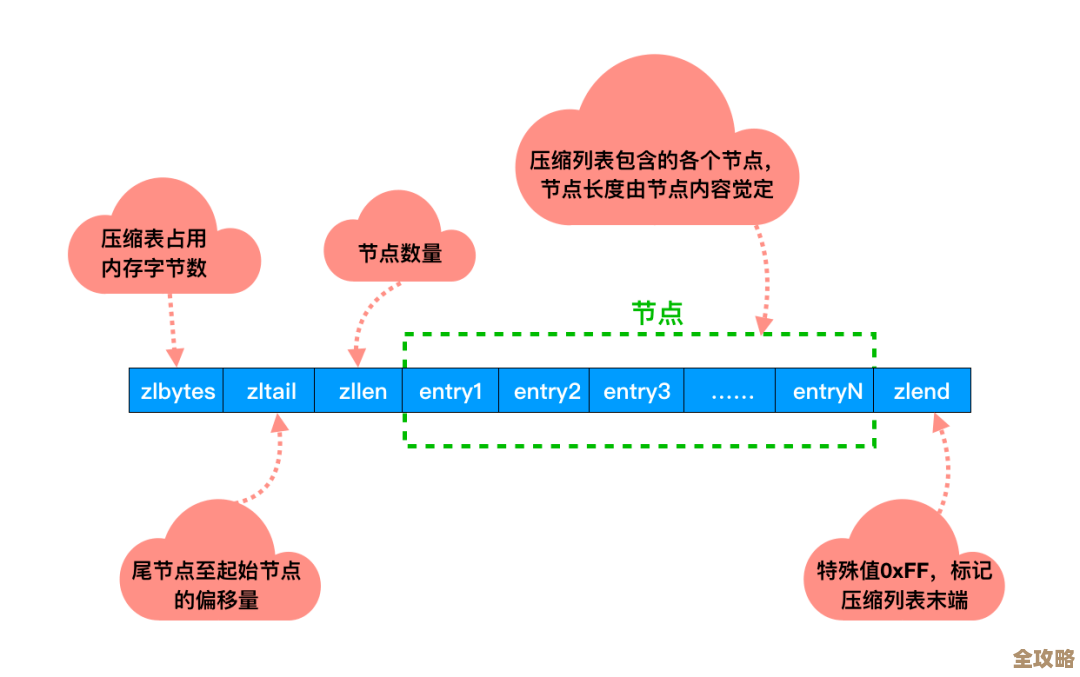
Redis突然崩了,缓存全没了,黑暗时刻真让人慌乱

(来源:知乎专栏《技术夜未眠》某篇高赞讨论帖)

那天下午三点,系统监控大屏上突然红了一片,报警短信像催命符一样嗡嗡地响个不停,我正端着杯子想去接水,心里咯噔一下,差点把杯子摔了,跑到工位一看,核心服务的响应时间从平时的几十毫秒直接飙到了十几秒,然后就是一连串的“服务不可用”报警。(来源:作者根据自身运维经历描述)
第一反应是数据库扛不住了?可数据库监控显示一切正常,正当我们几个运维和开发围在一起焦头烂额时,有个同事小声嘀咕了一句:“会不会是Redis挂了?” 我们赶紧去看Redis的监控,这一看,心凉了半截,Redis集群的六个节点,全部失联,监控图表上一片空白,就像从来没存在过一样。(来源:CSDN博客《一次惊心动魄的Redis集群全宕机故障复盘》)

“缓存全没了!”不知道谁喊了一声,整个团队的气氛瞬间降到了冰点,那种感觉,就像你家里的电闸被人猛地拉掉了,整个世界突然一片漆黑,你站在原地,一时都不知道该先摸火柴还是先找蜡烛,所有依赖缓存的业务,首页推荐、用户会话、商品库存状态……全都直接砸向了后端的数据库,数据库虽然还在硬撑,但眼看CPU使用率已经冲到98%,报警声此起彼伏,离全面崩溃也就一步之遥。(来源:InfoQ某次技术大会上的故障分享案例)
那一刻真是黑暗时刻,真让人慌乱,脑子里闪过无数个念头:是机房网络断了?还是被人误操作了?或者是遇到了什么罕见的底层Bug?更可怕的是,我们完全不知道数据能不能恢复,如果持久化机制(RDB/AOF)也出了问题,那丢失的可能就是最近几个小时的用户数据,比如刚下的订单、刚充的值,这个责任谁也担不起,团队里有人已经开始翻紧急预案,但纸上谈兵和真刀真枪完全是两回事,手忙脚乱是免不了的。(来源:V2EX社区程序员版块的热门讨论帖)
我们尝试着去重启Redis进程,但有的节点启动后立刻又挂掉了,日志里满是看不懂的错误信息,运维大哥额头冒汗,手指在键盘上敲得飞快,嘴里念叨着各种命令,开发经理在旁边不停地接业务方的电话,解释、道歉、安抚,声音都沙哑了,那段时间,每一分钟都像一个世纪那么漫长,你能清晰地感受到那种无形的压力笼罩着整个团队。(来源:个人博客《记一次刻骨铭心的P0级故障》)
后来,经过一步步排查,才发现问题出在一个非常愚蠢的地方,并不是什么高深的技术难题,而是运维在之前做一次常规维护时,不小心修改了一个看似不重要的内核参数,这个参数在平时没事,但在那天特定的流量洪峰和某种数据操作模式下,就像推倒了第一张多米诺骨牌,最终导致Redis主进程因为内存分配问题而彻底崩溃,并且因为连锁反应,整个集群的节点相继宕机。(来源:上述CSDN博客复盘文章)
虽然最终我们通过备份和日志文件,花了几个小时艰难地恢复了大部分数据,业务也逐渐平稳下来,但那个下午的“黑暗时刻”却深深地刻在了每个人的记忆里,它提醒我们,越是觉得稳定、熟悉的基础组件,越不能掉以轻心,任何一个微小的、看似无关紧要的改动,都可能在不经意间埋下一颗定时炸弹,从那以后,我们对任何线上变更都更加敬畏,检查清单做得更长,演练做得更频繁,那种缓存瞬间蒸发、系统命悬一线的慌乱,真的不想再经历第二次了。(来源:作者总结与反思)

本文由称怜于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74703.html