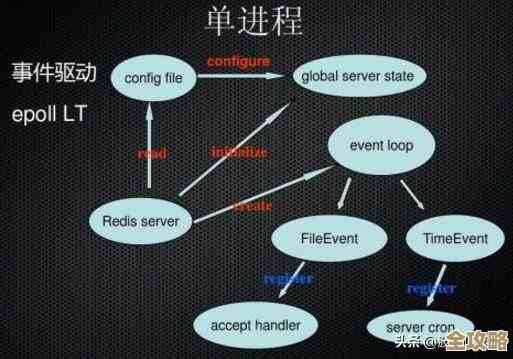
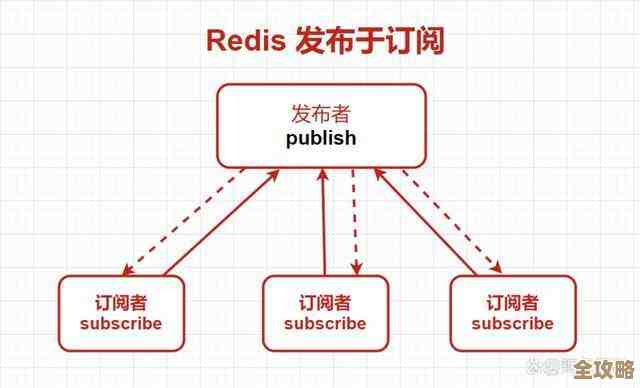
Redis到底是怎么用键值对来存数据的,底层又是什么结构支撑着呢

Redis的核心就像是一个超级快的大字典,你给他一个“键”(Key),他立刻就能返回给你对应的“值”(Value),这个“值”可以是各种类型,比如字符串、列表、哈希、集合等等,但无论值多么复杂,最外层永远是一个简单的键值对映射,这个看似简单的“字典”背后,是靠什么结构支撑起如此高效的读写能力呢?答案主要在于两个方面:一个是用来管理所有键值对的全局“字典”,另一个是针对不同数据类型的值所采用的精巧数据结构。
我们来看这个全局的字典,它被称为键空间,你可以把它想象成一个巨大的哈希表,当你执行 SET username "张三" 这个命令时,Redis会在键空间(哈希表)里创建一个条目:键是“username”,值是一个指向存储“张三”这个实际数据结构的指针,这个键空间哈希表是Redis能够实现O(1)时间复杂度快速查找的关键,无论你的数据库里存了多少亿个键,理论上它都能通过哈希计算直接定位到某个键的位置,为了应对哈希冲突(即不同的键计算出相同的哈希值),Redis采用了链地址法,也就是在同一个位置用一个链表把冲突的键连接起来。

也是最精妙的部分,是Redis为不同类型的“值”设计了不同的底层数据结构,这正是Redis速度快、功能强的秘密所在,它并不是把所有值都当成傻乎乎的字符串来存储,而是“看菜下饭”。
-
简单的字符串:这是最基础的类型,它的底层实现叫简单动态字符串,它不像C语言的原生字符串那样死板,而是自带了一些“元信息”,比如当前字符串的长度和剩余空闲空间的长度,这使得它可以高效地进行长度计算和追加修改,避免了每次修改都重新分配内存的开销。

-
列表:当你存储一个列表(List)时,比如文章评论ID的队列,Redis在数据量小的时候使用一种叫压缩列表的结构,它是一种非常紧凑的、元素紧挨着存放的序列,能极大地节省内存,但当列表元素增多或单个元素变大时,为了效率,Redis会将其转换为双向链表,这样在列表的头尾进行插入删除操作就非常快,时间复杂度是O(1)。
-
哈希:哈希(Hash)类型适合存储一个对象的多个字段,比如一个用户的姓名、年龄、城市,它的底层在数据量小时也使用压缩列表,把所有字段和值依次排列,数据量大时,则会转换成一个哈希表,这样就能直接通过字段名快速找到对应的值。

-
集合:集合(Set)的特点是元素不重复且无序,它的底层实现有两种:当集合元素全是整数且数量不多时,使用整数集合,这同样是一种非常节省内存的紧凑数组,否则,就会使用哈希表来实现,这时哈希表的每个键是集合元素,值则设为NULL,因为只需要键的唯一性。
-
有序集合:这是Redis最复杂的数据结构之一,它既能保证元素唯一,又能给每个元素赋予一个分数(score)用于排序,它的底层是跳跃表和哈希表的结合体。跳跃表是一种可以快速进行范围查询(比如取排名前十的元素)的数据结构,它通过建立多级索引来实现近似二分查找的效率,而哈希表则用于实现根据元素名快速找到其对应分数的O(1)查找,两种结构相辅相成,共同支撑起有序集合的强大功能。
Redis还会根据数据的实际情况,在不同数据结构之间自动转换,以在内存使用和性能之间取得最佳平衡,为了持久化数据,Redis还会将内存中的这些数据结构以特定的格式(如RDB的快照或AOF的命令日志)写入硬盘。
Redis使用键值对存储数据的核心在于:一个高效的全局哈希表(键空间)负责快速定位键,而一系列精心设计、可相互转换的底层数据结构(如简单动态字符串、压缩列表、哈希表、跳跃表等)则负责以最高效的方式存储和操作不同类型的值,这种分工明确、因地制宜的设计哲学,是Redis高性能的基石。
(参考资料:Redis官方文档、《Redis设计与实现》一书、以及多位技术专家如黄健宏对Redis源码的解读)
本文由称怜于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74596.html