高并发场景下,分布式限流到底咋搞,理论和实操都得懂才行

说到高并发场景下的分布式限流,咱们可以把它想象成一个大热门景区在黄金周的入园管理,如果不对涌入的游客进行控制,那么景区内就会人山人海,寸步难行,所有人都玩不好,甚至可能发生踩踏事故(这就是系统崩溃),单台服务器的限流,就像是景区的一个小入口自己数着人数放行,但当你有很多个入口(多台服务器)时,每个入口只知道自己放了多少人,但不知道其他入口的情况,加起来就可能远远超过景区的总承载能力,分布式限流要解决的,就是让所有这些入口协同工作,确保总人数不超过安全上限。
核心理论:几种常见的“限流算法”
这就像是景区管理层制定的几种不同风格的放行策略。

-
固定窗口计数器法(来自经典限流思想)
- 怎么搞:把时间切成一个个固定的窗口,比如每分钟一个窗口,规定每个窗口最多允许100个请求,每当一个请求进来,就看当前这个分钟窗口的计数器是否已经到100了,没到就放行,计数器加1;到了就拒绝,下一分钟开始时,计数器清零,重新计算。
- 优点:实现简单,理解容易,内存消耗小。
- 致命缺点:窗口临界问题,想象一下在1分59秒瞬间来了100个请求,在2分00秒瞬间又来了100个请求,虽然这两个瞬间都在各自的1秒内,但因为恰好在两个窗口的交界处,所以在1分钟这个窗口维度上,系统在2秒内承受了200个请求,这可能会压垮系统,这就好比在59分59秒放进去100人,紧接着在00分00秒又放进去100人,景区瞬间压力巨大。
-
滑动窗口计数器法(对固定窗口的优化)
- 怎么搞:为了解决固定窗口的临界问题,滑动窗口把大窗口再细分成更小的格子,比如把1分钟的大窗口分成6个10秒的小格子,每个请求来时,统计的是当前时间点往前推1分钟内(即最近6个小格子)的所有请求数量总和,这样,计算就不再是僵化地以整分钟为界,而是“滑动”的。
- 优点:比固定窗口平滑很多,很大程度上缓解了临界突变的问题。
- 缺点:实现比固定窗口稍复杂,格子划分得越细,就越精确,但占用的存储也相应增多。
-
漏桶算法(来自网络流量整形)

- 怎么搞:想象一个底部有固定大小出水口的木桶,请求像水一样以任意不规则的速率流入桶中,而桶的出口,则以一个恒定的、预先设定好的速率向外漏出请求(比如每秒10个),如果水流入太快,桶满了,后续的请求(水)就会被溢出(拒绝)。
- 优点:能够非常严格地强行限制数据的传输速率,无论请求多么不均匀,出口永远是平滑的,这对于保护下游系统特别有用。
- 缺点:无法应对突发流量,即使系统现在完全空闲,有处理能力,漏桶也只会以固定速率放行,无法快速消费掉积压的请求,可能会造成不必要的延迟。
-
令牌桶算法(目前最常用的算法之一)
- 怎么搞:想象一个桶,这个桶里放着“令牌”,系统以一个恒定的速率(比如每秒10个)向桶里放入令牌,当桶满了,新令牌就被丢弃,每当一个请求到来,它必须从桶里拿走一个令牌才能被处理,如果桶里有令牌,请求立即被处理;如果桶里没令牌了,请求就会被拒绝或等待。
- 优点:既能够将整体的流量平均到各个时间点(因为令牌是匀速产生的),又能够允许一定程度的突发流量,比如桶的容量是100,且是满的,那么瞬间可以处理100个请求,这对于系统资源闲置后突然来的流量高峰是友好的。
- 缺点:实现相对复杂一些。
实操:如何实现“分布式”?
理论上的算法知道了,但在多台机器上怎么协同呢?关键在于找一个“总指挥”,让所有服务器都能向它汇报和申请。

-
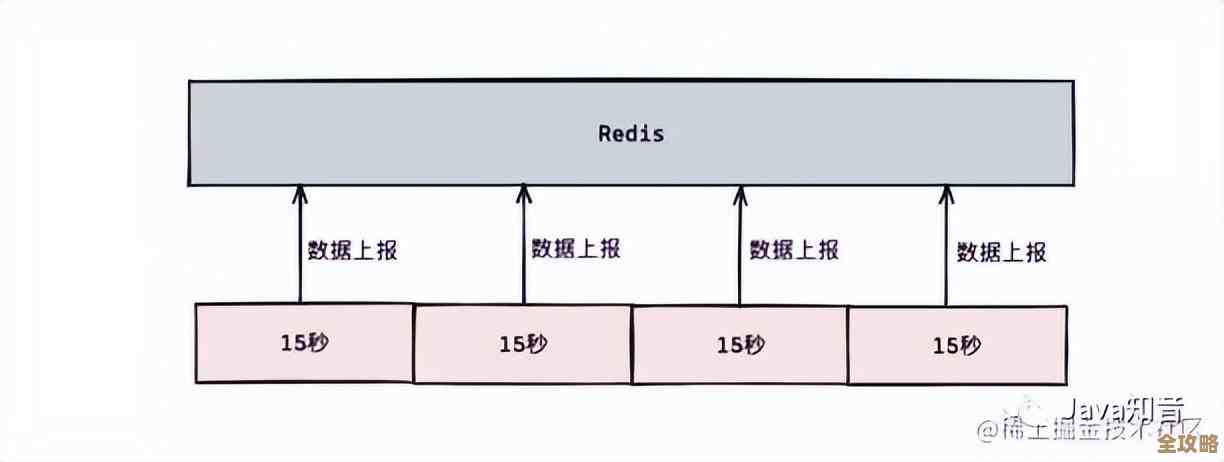
基于Redis的分布式限流(最主流和实用的方案)
- 核心思想:利用Redis的单线程特性和强大的性能,让它充当那个“总计数器”或“总令牌桶”。
- 实操举例(以令牌桶为例):
- 在Redis中为每个需要限流的服务(用户注册接口”)设置一个键(key)。
- 这个key的值存储当前的令牌数量,并设置过期时间(比如等于令牌被填满的时间,避免无用数据长期存在)。
- 当一台服务器的应用收到请求时,它不自己计算,而是向Redis发送一个Lua脚本,这个脚本原子性地执行一系列操作:计算自上次请求后到现在应该新产生多少令牌、更新当前令牌数、判断是否够一个令牌、如果够就减一然后返回成功,不够就返回失败。
- 为什么用Lua脚本? 因为Lua脚本在Redis中是原子执行的,可以确保在高并发下不会出现计算错误(比如多个请求同时读到旧的令牌数,都认为有令牌,然后都去减一,导致超发)。
- 优点:性能高,实现相对直接,可利用现成的Redis基础设施。
- 缺点:强依赖于Redis的可用性,如果Redis挂掉,限流就失效了,需要保证Redis本身是高可用的(比如用集群模式)。
-
基于网关的分布式限流(更上层的解决方案)
- 核心思想:不让业务代码操心限流,而是在所有请求到达业务服务器之前,由一个统一的网关(如Nginx、Spring Cloud Gateway、Zuul)来负责限流。
- 实操:在网关层面配置限流规则(比如使用Nginx的
limit_req_zone和limit_req指令实现漏桶算法,或者用Lua扩展实现令牌桶),所有流量都必须先经过网关,由网关判断是否放行,被放行的请求才会被转发到后端的多台业务服务器上。 - 优点:对业务代码完全无侵入,限流逻辑统一管理,降低业务开发复杂度。
- 缺点:网关本身可能成为性能瓶颈,需要保证网关的高可用和可扩展性,配置和管理网关的限流规则需要额外的运维知识。
在高并发下搞分布式限流,理论上是选择一个合适的算法(令牌桶因其灵活性成为首选),实操上是选择一个可靠的“协调者”(Redis是常见选择,网关是架构层面的选择),没有绝对最好的方案,只有最适合当前系统架构和团队技术栈的方案,关键是要理解每种方法的优缺点,知道它们分别适用于什么场景,这样才能在真正的流量洪峰到来时,让你的系统稳如泰山。
本文由帖慧艳于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74285.html