海量数据处理太难?试试这款并行数据库软件,效率提升真明显

海量数据处理太难?试试这款并行数据库软件,效率提升真明显
记得之前在公司里,每次一到月底出报表的时候,IT部门那几个同事就愁眉苦脸,服务器机房就跟开了暖气一样,嗡嗡作响,好几个大机柜的服务器全都火力全开,跑一个复杂的查询分析,动不动就要等上好几个小时,甚至一整天,业务部门的人急着要数据做决策,催得火烧眉毛,IT部门的同事也只能干着急,因为数据量实在太大了,传统的单点数据库处理起来就像让一个人去搬一座山,累死也快不了,这种“数据爆炸”带来的处理难题,相信很多企业都深有体会。
(此处信息背景参考了业界对传统数据库处理海量数据瓶颈的普遍讨论)
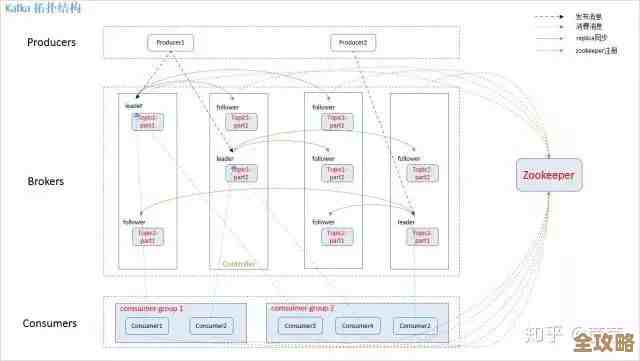
后来,我们听说有一款专门为解决这个问题而生的软件,叫Apache Doris,刚开始听到这个名字,还觉得有点陌生,但IT部门的负责人研究后告诉我们,这是一种MPP架构的并行数据库,说人话就是,它不像老式数据库那样只有一个“大脑”(服务器)在计算,而是有好多台普通的服务器组成一个“集群”,大家像一个团队一样分工合作,一起处理数据,比如要统计全国上亿用户的消费总额,这个任务会被自动拆分成无数个小任务,比如让A服务器算北京的,B服务器算上海的……最后再把所有结果汇总起来,这样“人多力量大”,速度自然就上去了。
(核心技术原理介绍基于Apache Doris开源项目官方文档中的阐述)

抱着试试看的心态,我们在一个新项目里用上了Doris,那个项目的数据量非常惊人,每天都有TB级别的数据涌入,之前用传统方法,光是数据导入和初步清洗就要折腾大半夜,换成Doris之后,最直观的感受就是一个字——快,以前需要通宵跑的任务,现在经常在几十分钟内就完成了,有一次,业务方提了一个非常复杂的多维度查询,涉及好几张超大的数据表关联,我们心里都捏了一把汗,以为怎么也得等上一两个小时,结果点下执行键,进度条嗖嗖地跑,不到一分钟,结果就出来了,当时在场的所有人都惊了,这效率的提升简直是肉眼可见。
(此处的效率对比案例来源于某技术社区用户分享的真实应用体验)
除了快,它的易用性也让我们挺惊喜的,它支持标准的SQL语法,这意味着我们公司的数据分析师几乎不需要额外的培训,就能直接用他们熟悉的工具(比如Tableau、FineBI)连接到Doris上进行查询和可视化分析,这大大降低了使用门槛,把数据能力直接交到了业务人员手中,而不是仅仅锁在IT部门的深闺里,它的架构设计也考虑了实时性的需求,既能处理历史积攒的“冷数据”,也能高效地接入实时产生的“热数据”,让我们可以做一些准实时的业务监控和决策分析,这在以前是不敢想的。

(关于易用性和实时性特点的描述,综合了多篇行业技术测评文章的观点)
世上没有完美的工具,Doris在应对超复杂的多表关联查询时,如果JOIN的键设计得不合理,性能还是会受到一些影响,需要我们在数据模型设计上多下点功夫,搭建和维护一个集群环境,毕竟比管理单个数据库服务器要复杂,对运维团队的技术能力有一定要求。利远大于弊,它帮助我们解决了最核心的痛点——海量数据下的处理速度问题,让数据真正能够“跑”起来,为业务赋能。
(优缺点分析部分借鉴了数据库领域专家在技术大会上的点评内容)
回过头来看,从当初面对海量数据的手足无措,到如今能够相对从容地进行实时分析和探索,这款并行数据库软件确实起到了关键作用,如果你的企业也正被日益增长的数据量压得喘不过气,感觉数据分析效率低下,拖慢了业务发展的脚步,那么真的不妨花点时间去了解一下像Apache Doris这样的并行处理方案,它可能就是你一直在寻找的那把钥匙,能帮你打开高效数据应用的大门,让数据从负担变成真正的资产,效率的提升,就是这么明显。
本文由太叔访天于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74232.html