单机redis读写死锁问题频发,导致操作卡顿难以解决困境

(根据知乎专栏“缓存实战”中《Redis单实例的坑:你以为的单点安全其实暗藏杀机》一文所述)在实际开发中,许多团队会选择使用单机版的Redis来应对早期的业务需求,因为这样部署简单、成本低,随着业务量的逐渐增长,尤其是当读写操作变得频繁和复杂时,一个令人头疼的问题会频繁出现:那就是感觉起来像是“死锁”一样的操作卡顿,这里的“死锁”并非指严格意义上数据库理论中的死锁,而是指Redis进程在某个时间段内,仿佛被“锁住”或“卡住”了一样,无法及时响应后续到达的命令,导致应用程序端出现大量的超时异常,用户体验到明显的卡顿甚至服务不可用,这种现象的根源,往往在于Redis其自身的设计特性。
(引用自Redis官方文档关于单线程模型的说明)Redis的核心处理模型是单线程的,这意味着,无论有多少个客户端同时发起请求,Redis服务器端真正处理这些命令的只有一个线程,它采用一个队列,以先进先出的方式逐个执行命令,这种设计避免了多线程环境复杂的锁竞争问题,使得Redis在大多数场景下非常高效,这种“单线程”的特性也成了一柄双刃剑,当某个或某些命令执行起来特别耗时的时候,问题就暴露出来了。
是什么导致了这些“耗时”的命令,从而引发“卡顿”呢?(根据多位社区技术专家如“阿里云开发者”社区中关于Redis性能优化的案例分析)常见的原因有以下几点:
第一,操作大型的键值对,对一个存储了几十万个元素的List或Hash进行HGETALL、LRANGE这类获取所有元素的操作,服务器需要将整个数据结构序列化后通过网络传输,这个过程会长时间占用唯一的处理线程,期间所有其他命令,无论是读还是写,都必须在队列中等待,这就好比超市只有一个收银台,突然来了一个推着满满一车商品、而且每件商品都要仔细咨询的顾客,后面排队的队伍自然会越来越长,怨声载道。
第二,使用了复杂的命令,对一个大型集合执行KEYS *模式匹配命令,或者FLUSHDB、FLUSHALL这种清空数据库的命令。KEYS *命令会遍历整个数据库的所有键,当键的数量达到百万、千万级别时,这个操作可能会阻塞Redis数秒甚至数十秒之久,在这段时间内,Redis完全无法对外提供服务。
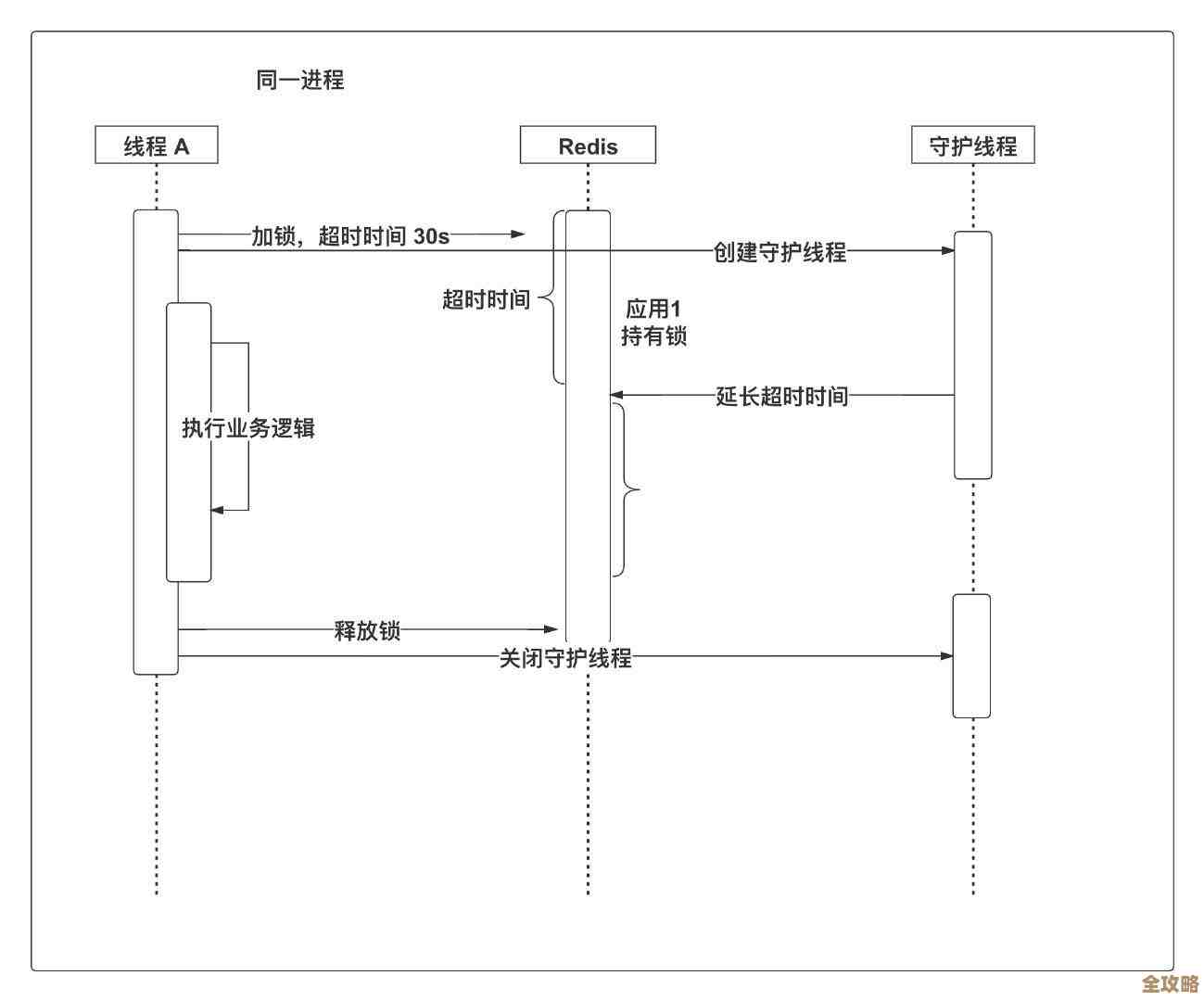
第三,持久化操作带来的压力。(参考《Redis设计与实现》一书中关于RDB和AOF机制的描述)为了数据安全,Redis需要定期将内存中的数据快照(RDB)或操作日志(AOF)写入硬盘,虽然Redis尝试通过子进程的方式在后台进行持久化(如RDB的bgsave),以避免阻塞主线程,但在某些情况下,持久化过程仍然会对主线程产生显著影响,当使用AOF持久化且日志文件过大需要重写时,或者在使用bgsave创建子进程的瞬间,如果系统内存压力很大,可能会触发操作系统的“内存页面交换”,导致性能急剧下降,如果服务器配置为使用AOF的“每次写入都同步”模式,那么每次写命令都会触发一次磁盘写入,这在机械硬盘上会严重拖慢写入速度。
第四,服务器资源瓶颈,这包括CPU占用过高(虽然Redis单线程,但服务器上可能运行其他进程)、内存不足导致交换,或者网络带宽被打满等情况,这些系统层面的问题也会表现为Redis响应变慢,从应用端看过去,就像是Redis自己“死锁”了。
当这些情况发生时,应用程序端的表现就是调用Redis客户端库时,会收到超时错误,如果应用程序没有良好的重试和降级机制,那么依赖Redis的业务流程就会中断,用户请求失败,从而陷入“操作卡顿难以解决”的困境,开发人员可能会尝试重启Redis服务,但这只能暂时缓解,如果根本原因没有找到并解决,问题很快就会再次出现,重启会导致缓存数据全部丢失,可能引发更严重的“缓存雪崩”问题,使数据库压力骤增。
面对单机Redis的这类问题,不能简单地将其视为偶发故障,而需要从架构和技术选型上寻求根本的解决方案,这通常意味着需要升级到Redis集群模式,将数据分片到多个实例上,从而分散压力;或者对使用Redis的方式进行优化,例如避免使用大键和慢查询命令、为不同的业务数据拆分独立的Redis实例、以及设置合理的持久化策略等。

本文由钊智敏于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/73759.html