用Redis怎么快速查用户信息,实际操作和技巧分享

用Redis查用户信息,核心思想就是“空间换时间”,简单说,就是把经常要查、对速度要求很高的用户数据,从慢吞吞的数据库里提前搬出来,放到内存里的Redis中,这样查的时候就不用去绕远路找数据库了,直接从内存读取,速度能快上百倍。
实际操作第一步:设计存储的Key
这是最基础也最重要的一步,Key设计得好,后面管理起来才方便,不能胡乱起名,得有规律,一个常见的做法是使用固定的前缀加上用户唯一标识,用户ID是123,那么他的信息在Redis里的Key就可以是 user:123 或者 user_info:123,这个冒号是习惯用法,它能在一些可视化工具里帮你把Key按层级展示,看起来更清晰,千万别用 user123 这种,以后想找所有用户相关的Key就麻烦了。
实际操作第二步:选择存储的数据结构
用户信息通常是一个包含多个字段的对象,比如用户名、头像、年龄、积分等,在Redis里,存这种数据最佳的选择是 Hash(哈希) 结构,它就像一个小的字典,有 field 和 value。
-
怎么存? 使用
HSET命令,要存用户123的信息,可以这样操作:HSET user:123 name "张三" avatar "1.jpg" score 1000这一条命令就能把多个字段一次性塞进去,你也可以分开用HSET user:123 name "张三",再HSET user:123 score 1000。 -
怎么查?

- 查整个用户信息:
HGETALL user:123,这会把这个用户的所有字段和值都返回给你。 - 只查个别字段:
HMGET user:123 name score,如果你只关心用户名和积分,用这个命令,它只返回你指定的字段,比HGETALL更高效。 - 查单个字段:
HGET user:123 name,就只查用户名。
- 查整个用户信息:
技巧分享一:缓存穿透及其应对
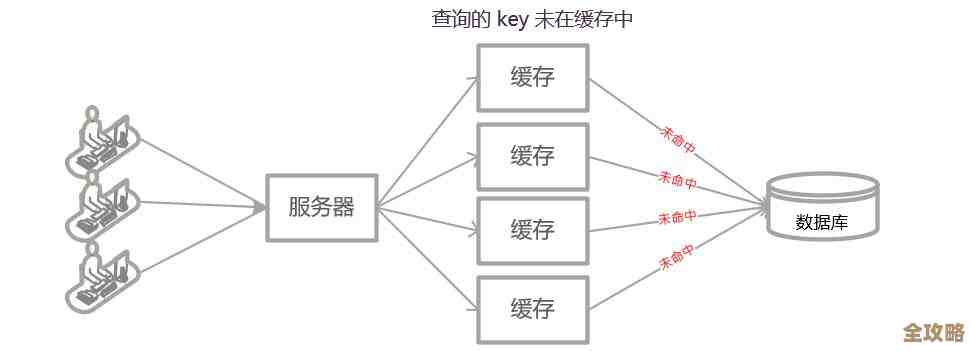
你可能会想,如果有个恶意请求,一直查一个不存在的用户ID(1或者9999999)会怎样?这个请求会先查Redis,发现没有(我们称之为“缓存未命中”),然后就会去查数据库,数据库也返回空,这样一来,这个无效的请求每次都会打到数据库上,失去了缓存的意义,这就是“缓存穿透”。
怎么办? 有个简单的技巧:即使数据库查不到,也在Redis里存一个空值,对于用户ID 9999999,我们执行 SET user:9999999 "null",并给它设置一个较短的过期时间,比如60秒,这样,在60秒内,再有请求查这个不存在的用户,Redis会直接返回空值,而不会去骚扰数据库,虽然占了一点点内存,但保护了数据库,非常划算。
技巧分享二:缓存雪崩及其应对

想象一下,如果你在系统启动时,把一万个用户数据全部加载到Redis里,并且都设置了相同的过期时间,比如2小时,那么2小时后的某一瞬间,这一万个缓存会同时失效,这时如果突然有大量请求进来,所有请求都会发现缓存没了,于是全部涌向数据库,数据库很可能瞬间就被压垮了,这种现象叫“缓存雪崩”。
怎么办? 核心技巧是 打散过期时间,不要在同一个时间点让大量缓存失效,在给缓存设置过期时间(TTL)时,不要都用固定的120分钟,可以在这个基础上加一个随机数,120分钟 + 随机0到30分钟,这样,缓存就会在120分钟到150分钟之间随机过期,失效的时间点就被均匀摊开了,数据库的压力就会平稳很多。
技巧分享三:如何保证数据最新?—— 缓存更新策略
用户信息不是一成不变的,用户可能会改名、换头像,这时,Redis里的缓存数据就和数据库里的真实数据不一致了,怎么办?有几种常见思路:
- 懒加载(被动更新): 这是最常用的,当用户更新自己的信息时,系统先去更新数据库。直接删除Redis里对应的缓存(
DEL user:123),下次再有请求来查这个用户时,发现缓存没了,就会去数据库取出最新数据,再重新写到Redis里,这个方法简单有效,虽然更新后第一次查询会慢一点,但保证了数据的一致性。 - 主动更新: 在更新数据库的同时,也主动更新Redis里的缓存,比如用户改名后,立刻执行
HSET user:123 name "新名字",这个方法读起来最快,但要注意操作的顺序,最好保证数据库更新成功后再更新缓存,否则可能出现奇怪的数据不一致,在高并发场景下,这个策略需要更精细的设计来避免并发问题,对初学者来说,优先推荐用第一种“懒加载”方式。
总结一下
用Redis快速查用户信息,说白了就是三部曲:设计好Key -> 用Hash结构存数据 -> 设置合理的过期时间,要留心缓存穿透和雪崩这两个坑,用“缓存空值”和“随机过期时间”这两个技巧来规避,至于数据更新,先从简单的“更新数据库后删除缓存”开始用起,把这些基础打牢,就能极大地提升你系统的查询速度,Redis是内存操作,速度极快,它的瓶颈往往不在于它本身,而在于我们如何使用它。
本文由帖慧艳于2026-01-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/73348.html