用Redis怎么快速又稳妥地更新缓存,写入和刷新那些事儿

关于用Redis怎么快速又稳妥地更新缓存,写入和刷新那些事儿,这确实是日常开发中经常要面对的难题,处理不好,轻则数据不同步,重则可能导致数据库被压垮,这里不谈那些高大上的理论,就说几种实际中常用的、接地气的做法和要注意的坑。
核心问题:先操作数据库,还是先操作缓存?
这是所有讨论的起点,不同的顺序会带来截然不同的后果。
先删除缓存,再更新数据库(Cache-Aside + Write-Aside)
这是很多人直觉上会用的方法:要更新数据了,先把缓存里的旧数据删掉,然后再去数据库里更新,想着等下次有请求来读数据时,发现缓存没有(Cache Miss),自然就会从数据库拉取新数据并重新塞回缓存。
- 听起来的好处:逻辑简单直接。
- 隐藏的巨坑:数据不一致的经典场景,想象一下这个顺序:
- 线程A(写请求)来了,先删除了缓存里的某个Key。
- 线程B(读请求)来了,发现缓存没有,于是去数据库查询此时还是旧值的数据。
- 线程B把查到的旧数据写回了缓存。
- 线程A这才完成了数据库的更新。
- 结果就是:数据库里是新数据,但缓存里是旧数据,除非这个Key再次被更新(删除缓存)或有其他机制,否则这个旧数据会一直存在,导致数据不一致。
除非你对短时间内的数据一致性要求不高,否则单独使用这种策略风险很大。

先更新数据库,再删除缓存(Cache-Aside,推荐做法)
这是目前更被推崇的一种主流方案,流程是:先踏踏实实地把数据库更新好,再去把缓存里的旧数据删除。
- 好处:出现上述那种严重不一致的概率降低了,因为更新数据库通常比删除缓存慢得多,在那个极短的时间窗口内,读请求很可能还是读到旧缓存,但一旦数据库更新完成、缓存被删除,后续的读请求就能拿到最新数据。
- 依然存在的问题:
- 极小概率的不一致:如果在删除缓存这一步失败了呢?那缓存里就一直是脏数据。删除缓存这一步必须有重试机制,可以引入消息队列(如RabbitMQ、Kafka)来保证:如果删除失败,就将这个删除任务持续重试,直到成功,这也就是常说的“异步确保”机制。
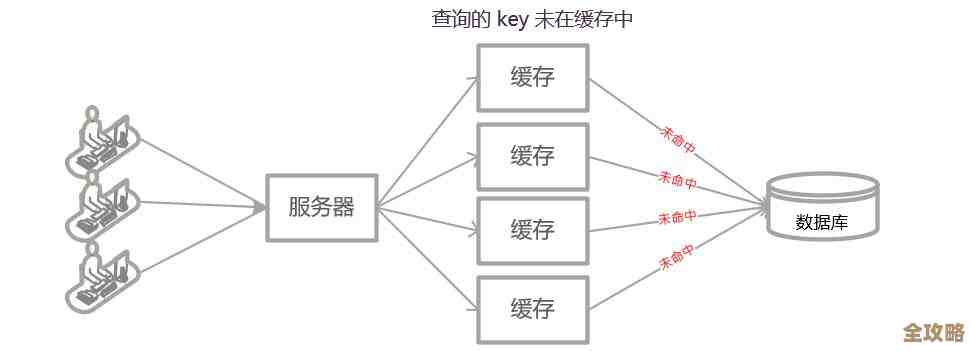
- 缓存击穿:如果这是一个热点Key,你刚删掉,瞬间有大量请求涌来,发现缓存为空,全部打到数据库上,数据库可能压力山大,解决办法可以是使用互斥锁(Mutex Lock),只让一个请求去数据库拉取数据并重建缓存,其他请求等待,这在Redis里通常用
SETNX(或其替代命令)来实现。
要不要用“更新缓存”代替“删除缓存”?
有人想,我直接更新缓存的值不行吗?为啥非要删掉?这要分情况看:

- 适用场景:对于计算成本非常高的缓存数据(比如需要复杂聚合查询的结果),直接更新缓存可能比等到Cache Miss时再重新计算要划算,可以避免下一次读请求的延迟高峰。
- 不适用场景/风险:
- 并发写导致数据错乱:两个写请求同时过来,A请求和B请求更新数据库的顺序可能是A->B,但更新缓存的顺序可能变成B->A,最终缓存里的数据可能是A请求的旧值,又乱了。
- 缓存利用率:你可能更新了缓存,但这个数据可能很长时间没人读,白占了内存,删除策略(惰性删除)反而更有利于提高缓存空间的使用效率。
关于缓存预热和刷新
- 预热:系统启动时,如果已知热点数据,可以提前加载到Redis里,避免上线后所有请求都直接穿透到数据库,可以用脚本批量操作。
- 刷新:除了上面被动的“读时刷新”(Cache-Aside),对于时效性要求极高的数据,可以采用主动刷新,后台数据更新后,通过消息通知或其他机制,主动、及时地去更新缓存,而不是等用户来触发,这通常需要更复杂的系统设计来支持。
总结一下稳妥的建议:
对于大多数通用场景,最稳妥、最常用的组合拳是:先更新数据库,再删除缓存,给这个“删除缓存”的动作加上一个失败重试的保障机制(比如通过消息队列),并且对热点Key的删除和重建考虑加锁来防止缓存击穿。
记住一个核心原则:**缓存不是可靠系统,它可能会丢数据,不要把不能丢的中间状态或唯一一份数据只放在Redis里,数据库才是数据的最终归宿,Redis的核心目标是“快”,一切设计都要围绕这个来。
一个相对稳妥的通用组合拳是:写操作时,采用“先更新数据库,再删除缓存”,并为删除操作配备重试机制(如消息队列),读操作时,采用标准的Cache-Aside模式,并对热点Key的缓存重建加锁防止击穿。 根据具体业务的数据一致性要求和数据热度,在这个基础上做微调。
本文由颜泰平于2026-01-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/73346.html