MSSQL里头那种死锁阻塞咋整,教你几招快速解围不慌乱

说到MSSQL数据库里的死锁和阻塞,这确实是让很多搞数据库维护的人头疼的问题,想象一下,就像一条单行道上,两辆车都想通过,但谁也不肯后退,结果就卡死了,这就是死锁,而阻塞呢,就像一辆车开得特别慢,或者停在路中间,后面的车全都得等着,下面就直接上几招实用的,帮你快速解围,遇到事儿别慌。
第一招:先搞清楚到底是死锁还是阻塞,别搞混了
动手之前,得先分清楚你面对的是什么情况,这个很关键,因为处理方式不一样。
- 阻塞:这是最常见的,简单说,就是一个事务(比如事务A)锁住了某个资源(比如一行数据、一张表),而另一个事务(事务B)也想用这个资源,但必须等A完事儿释放了锁才能用,这时候B就被“阻塞”了,在那里干等,只要A一结束(提交或回滚),B就能继续跑了,阻塞不一定是坏事,在并发系统里,一定程度内的阻塞是正常的,表示有活干,但阻塞时间太长、太多,就成了性能问题。
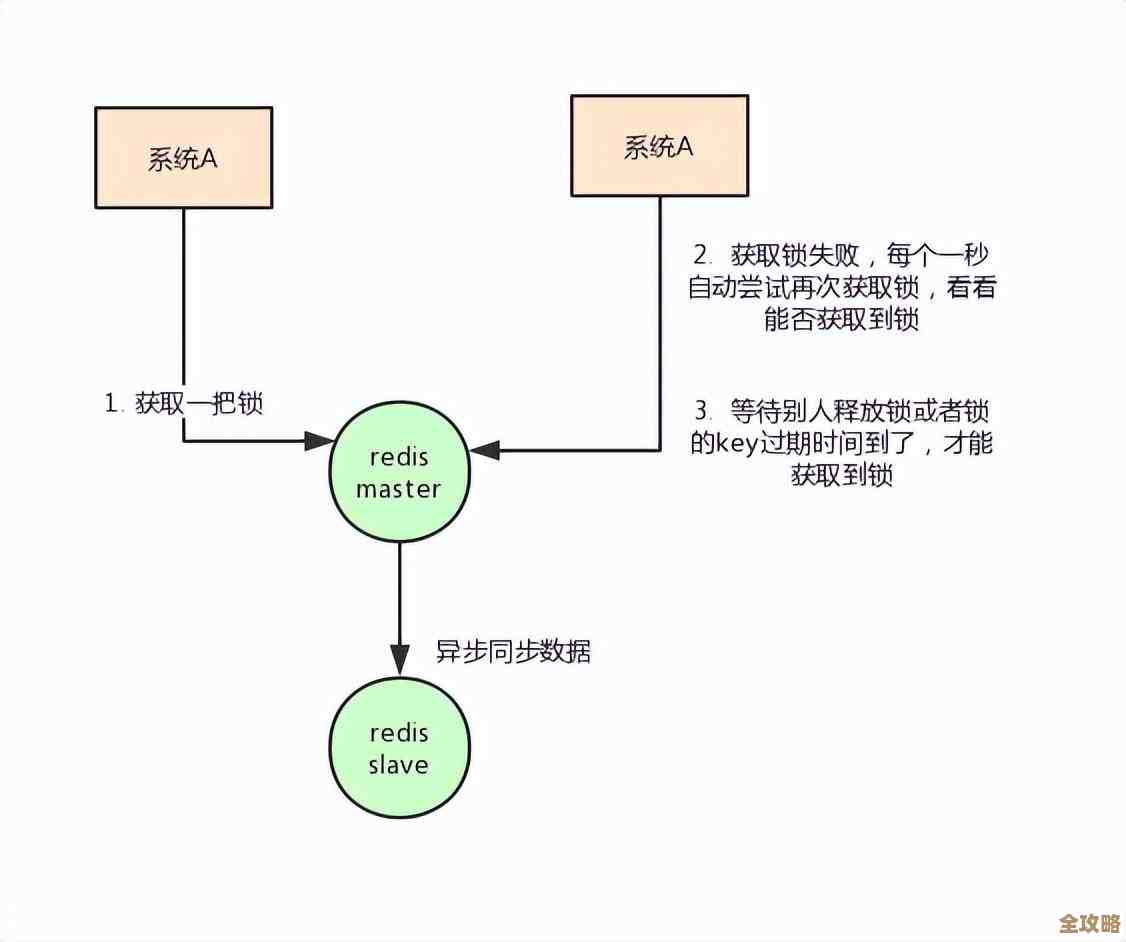
- 死锁:这个就比较麻烦了,它是指两个或更多事务互相卡住了,事务A锁住了资源1,同时想拿资源2;不巧的是,事务B已经锁住了资源2,同时它又想拿资源1,这下好了,A等着B释放2,B等着A释放1,俩人就这么大眼瞪小眼,谁也进行不下去,MSSQL自己有个后台进程叫“死锁监视器”,它隔几秒钟就会检查一次,一旦发现这种“死循环”,它就会挑一个“牺牲品”(通常认为是回滚代价较小的那个事务),把它干掉(回滚),让另一个事务能继续运行,所以你可能会在错误日志里看到1205错误。
怎么快速看? 有个挺常用的动态管理视图叫 sys.dm_exec_requests,你可以跑个查询,看看有没有 blocking_session_id 不为0的会话,那它就是被阻塞的了,如果等待类型(wait_type)是特定的,比如LCK_M_XXX之类的,那基本就是锁的问题。
第二招:遇到紧急阻塞,先救火——找到并干掉“罪魁祸首”

当系统反应巨慢,你怀疑是某个长事务阻塞了大家,需要立刻解决,这时候别想着慢慢分析,先恢复服务要紧。
- 找出阻塞源头:可以运行一些查询来定位,使用
sp_who2这个存储过程(虽然不是官方正式文档里的,但很常用),或者更规范地用sys.dm_exec_requests和sys.dm_tran_locks这些动态管理视图(DMV)联查,目标是快速找到那个blocking_session_id(通常是一个具体的SPID,比如56)。 - 评估能否终止:找到这个SPID后,别急着杀,先看看它在干啥,可以用
DBCC INPUTBUFFER(56)看看这个会话最近执行的命令是啥,判断一下这个操作重不重要,如果是个报表查询跑了很久,或者是个不小心没提交的事务,那杀掉的影响可能不大,如果是个正在更新核心数据的业务操作,那就要非常小心,杀了可能导致数据不一致。 - 执行终止命令:如果确定可以杀,就用
KILL 56命令,这个命令会强制回滚那个会话的事务,然后释放它占用的所有锁,被阻塞的会话就能继续了,注意,如果那个被KILL的事务很大,回滚可能需要点时间,期间可能还会阻塞其他操作,耐心等一下。
第三招:对付死锁,关键在于事后分析,防止再犯
死锁通常发生得很快,MSSQL自动就处理掉了,你的主要工作不是去“解”正在发生的死锁(因为数据库自己会解),而是分析死锁发生的原因,然后从根上避免它。

- 开启死锁跟踪:这是最重要的取证工具,默认情况下,MSSQL只会把死锁的概要信息记在错误日志里,信息量可能不够,你可以通过跟踪标志(Trace Flag)1222或1205来开启更详细的信息收集,在SQL Server配置管理器里给启动参数加上
-T1222,更现代、更推荐的方法是使用SQL Server Profiler(或扩展事件 Extended Events)来捕获死锁图(Deadlock Graph),死锁图会用XML的形式,非常直观地展示出是哪两个事务、在争抢哪些资源、各自持有什么锁又想申请什么锁,一目了然。 - 分析死锁图:拿到死锁图后,就像看破案线索,重点关注:
- 涉及哪些表和资源?(是同一行数据还是索引页?)
- 各个事务执行的语句是什么?(是UPDATE还是SELECT?)
- 事务的执行顺序是怎样的?(是不是所有事务都按相同的顺序去访问多个表?)
- 根据原因下药:常见的解决方法有:
- 保持访问顺序一致:这是解决死锁的黄金法则,如果多个事务都需要更新A表和B表,那就规定所有程序都先更新A,再更新B(或者都先B后A),避免交叉等待。
- 降低事务隔离级别:比如默认的
READ COMMITTED可能会因为共享锁(S锁)的持有时间问题导致阻塞和死锁,如果可以接受,考虑使用READ COMMITTED SNAPSHOT或SNAPSHOT ISOLATION,它们通过行版本控制来读数据,读操作不阻塞写操作,能极大减少死锁。 - 减少事务长度:事务里别做无关的操作,特别是用户交互(比如等用户点击确认),尽快提交或回滚事务,事务时间越短,持有锁的时间就越短,撞车的概率就越低。
- 使用提示:在非常特定的场景下,可以在查询里加表提示,比如
UPDLOCK,ROWLOCK等,来更精细地控制锁行为,但这招要慎用,用不好可能适得其反。
第四招:日常预防才是王道
不能总等着出问题了才去救火,平时就要做好预防。
- 索引优化:良好的索引能让查询快速找到数据,减少全表扫描,从而减少锁的粒度和持有时间,一个UPDATE语句如果因为没索引而扫全表,它可能会锁住整张表,阻塞所有其他操作。
- 代码审查:检查那些长时间运行的事务和复杂的SQL语句,确保事务被正确且及时地关闭(提交或回滚)。
- 监控告警:设置监控,当发现阻塞时间超过一定阈值(比如30秒)或者死锁频率突然增高时,主动发送警报,让你能提前介入。
遇到MSSQL死锁阻塞别慌,紧急情况,先KILL掉阻塞源救急;对于死锁,重点是利用死锁图分析根本原因,修改程序或设置来避免,平时则靠优化索引、规范编码来预防,这样就能比较从容地应对了。
(注:以上方法参考了常见的SQL Server DBA故障处理经验以及微软官方文档中关于锁、死锁和动态管理视图的相关说明。)
本文由符海莹于2026-01-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/73248.html