用Redis那些算法来搞ID生成,分段处理效率还能再高点吗?

你问用Redis搞ID生成,用那些算法,分段处理能不能让效率更高,答案是肯定的,而且这几乎是现在很多公司处理大规模ID生成时最常用、也最实在的一种办法,咱们就别绕弯子了,直接说怎么回事。
为啥要用Redis生成ID?
最根本的原因就一个字:快,传统数据库用自增ID,比如MySQL的AUTO_INCREMENT,在单机小流量时没问题,但一旦业务大了,系统要拆分成多个服务、多个数据库(分库分表),这个自增ID就麻烦了,每个数据库都自己从1开始增,那全系统范围内的ID肯定就重复了,这绝对不行,我们需要一个全局唯一、并且大体上越来越大的ID生成中心,Redis因为速度极快,天生就适合干这个。
基础的玩法:INCR命令
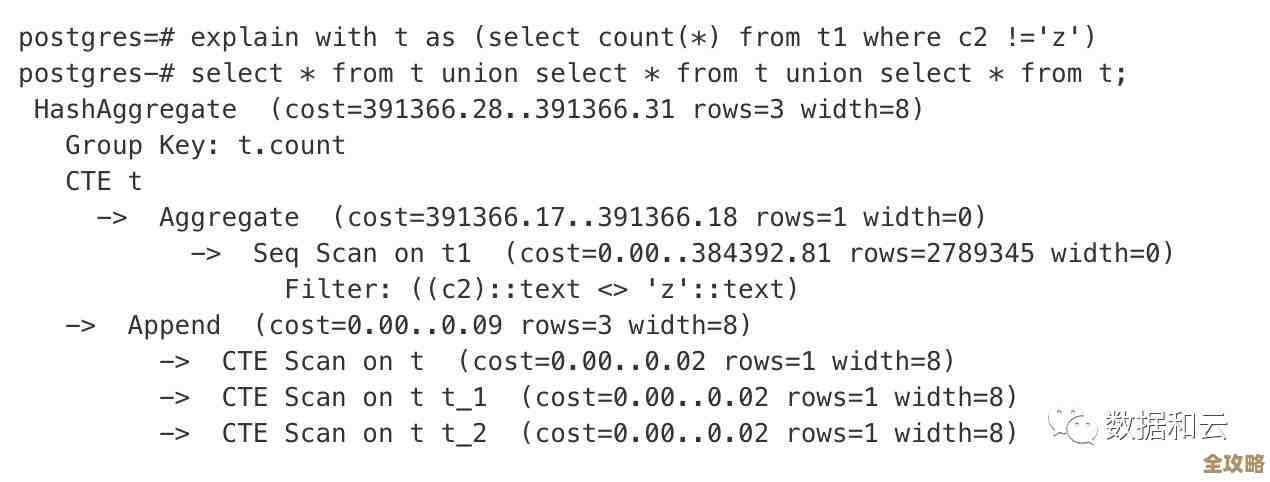
最直接、最简单的算法就是用Redis的INCR命令,你只需要一个键,比如叫global:user:id,每次需要新ID的时候,业务服务就向Redis发一个INCR global:user:id命令,Redis会保证这个命令是原子性的,也就是哪怕一万个请求同时过来,它也会一个一个加,绝对不会给出重复的ID,拿到这个数字,就是你的唯一ID。
这方法简单,但有个大问题:效率瓶颈。
你想啊,所有生成ID的请求,不管来自哪里,都得排队访问Redis里那一个键,这个键就成了一个单点,平时可能感觉不出来,一旦到了像秒杀、或者业务高峰时段,海量请求涌向这个单点,Redis的CPU压力会非常大,网络IO也可能成为瓶颈,虽然Redis本身很快,但这种集中式的访问模式限制了它的扩展性,这时候,“分段处理”的思路就派上用场了。

分段处理:把“大仓库”变成“小卖部”
分段处理,也叫号段模式(Segment或Step),是解决上述瓶颈的一个非常聪明的办法,它的核心思想是:别一个一个地要,一次申请一大段,然后慢慢用。
具体是怎么操作的呢?
- 预备工作:你在Redis里还是需要一个基础键,比如
global:user:id,它的值代表当前已经分配出去的最大ID号。 - 批量申请:业务服务(比如用户服务)不是每次需要ID都去调用Redis,而是先去申请一个“号段”,它向Redis请求:“给我下一个1000个ID”,Redis收到请求后,执行
INCRBY global:user:id 1000,假设操作前值是10万,操作后Redis的值变成101000,Redis把“10万到101000”这个范围(实际上是100001到101000,这1000个号)返回给业务服务。 - 本地消费:业务服务拿到这1000个ID号段后,把它存在自己的内存里,在内存里维护一个当前值
currentId=100001和一个最大值maxId=101000。 - 生成ID:每当业务需要生成一个新用户ID时,它再也不需要连接Redis了,直接在自己的内存里执行
currentId++就行了,速度是纳秒级别的,和本地变量操作一样快,几乎没有性能损耗。 - 再次申请:当本地的ID快用完时(比如
currentId达到100500了),业务服务再提前向Redis发起下一次号段申请,再要一批新的号段(比如再要1000个),这样就能保证业务服务本地几乎永远有ID可用,不会断档。
分段处理为什么效率能“再高点”?

对比一下两种模式,效率的提升是显而易见的:
- 极大减少网络开销和Redis压力:这是最关键的,原来每生成一个ID,就有一次Redis网络往返,现在生成1000个ID,才需要一次Redis网络往返,对Redis的请求频率降低了成百上千倍,Redis的单点压力骤降。
- 将性能瓶颈转移:ID生成的性能瓶颈从“Redis的网络和处理能力”转移到了“业务服务的内存操作”,而内存操作的速度是极其恐怖的,几乎可以忽略不计,这样,整个系统的ID生成吞吐量理论上只受业务服务自身数量的限制,扩展性变得非常好。
- 应对网络波动的能力强:即使网络出现短暂抖动,或者Redis有瞬间的高负载,因为业务服务本地有库存,也不会立即影响ID的生成,业务有很强的抗干扰能力。
需要注意的地方
分段处理也不是完美的,需要处理一些小细节:
- 号段大小设置:号段设置多大合适?设小了,申请频繁,Redis压力还是大,设大了,如果业务服务突然重启,内存里还没用完的ID段就浪费了,会造成ID号段的不连续(但这通常不影响唯一性),需要根据业务量找一个平衡点。
- 服务重启处理:业务服务重启时,内存里没用完的ID段就丢了,所以服务启动后,需要立即向Redis申请一个新的号段来用。
- ID的连续性:这种方法生成的ID在大体趋势上是递增的,但不是绝对连续,比如一个服务申请了1-1000,另一个服务申请了1001-2000,但第一个服务可能因为重启浪费了200-300的号,所以全局来看ID序列中间会有空洞,但只要你的业务不要求ID绝对连续(绝大多数业务都不要求),这就不是问题。
总结一下
回到你的问题,用Redis的INCR算法是基础,而引入分段处理的模式,绝对不是“还能再高点吗”的疑问,而是实实在在的、大幅度的效率提升,它是一种非常经典的空间换时间、批处理思想的应用,通过将集中式的实时请求,转变为分散式的预分配消费,巧妙地化解了性能瓶颈,现在你去看很多大厂的ID生成器(比如美团Leaf的号段模式,来源:美团技术博客),其核心思想就是这么朴实无华且有效。
本文由度秀梅于2026-01-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/72988.html