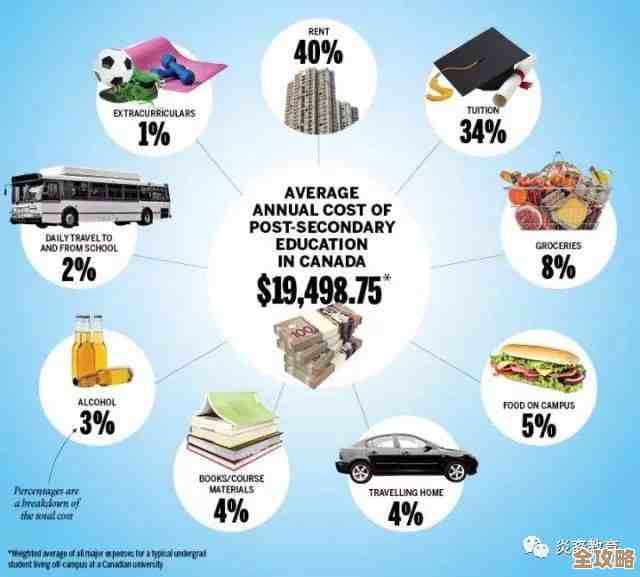
用Redis怎么快速搞定用户画像,聊聊那些实操和坑点

直接上干货,聊怎么用Redis这把“瑞士军刀”来搞用户画像,还有过程中那些让人头疼的坑,这东西听起来高大上,其实说白了就是给用户贴标签,90后”、“游戏宅”、“消费能力强”,然后快速地把有相同标签的人找出来做精准推荐或者营销。
为什么选Redis?就图一个“快”字
用户画像的核心操作就俩:一是给用户打标签(写操作),二是根据标签组合快速圈人(读操作),比如双十一前,运营想找“最近30天看过但没下单的女性用户”发优惠券,这种查询关系型数据库(比如MySQL)可能就歇菜了,表关联一多,慢得吐血,Redis所有数据放内存里,速度是它的最大王牌,特别适合这种需要实时或准实时响应的场景。
实操:最常见的两种玩法
别想太复杂,最实用的就两种数据结构:Set(集合) 和 Bitmap(位图)。
用Set集合——简单直接,小白友好
-
怎么玩? 一个标签就是一个Set,这个Set里存的就是有这个标签的所有用户ID。
- 比如你有个标签叫“VIP用户”,那你的Redis里就有一个 key 叫
tag:vip,它的 value 就是所有VIP用户的ID集合。 - 给用户打标签:
SADD tag:vip user_id1 user_id2(把user_id1和user_id2加入VIP集合) - 取消标签:
SREM tag:vip user_id1 - 圈人查询:比如找既是“VIP”又是“北京”的用户,直接用交集命令:
SINTER tag:vip tag:beijing,结果瞬间就出来了。
- 比如你有个标签叫“VIP用户”,那你的Redis里就有一个 key 叫
-
优点: 理解起来毫无门槛,操作命令也简单,适合标签数量不是特别多(比如一个用户最多几百个标签),用户总量在千万级以内的场景。
-
坑点:
- 内存炸弹: 这是最大的坑!如果一个标签特别火,注册用户”这个标签,所有用户都在里面,这个Set会巨大无比,非常吃内存,Redis单个Value太大(比如超过10KB)时,性能会下降,而且集群环境下数据迁移能卡死你。
- 查询别太浪:
SINTER计算交集虽然快,但如果你一次性交集五六个巨大的Set,Redis可能会“愣住”一下,阻塞其他请求,所以复杂的多标签组合查询要谨慎。
用Bitmap——极致压缩,大佬首选
-
怎么玩? 这个有点抽象,但极其省内存,我们把每个用户分配一个数字ID(比如自增ID),然后一个标签就是一个巨大的Bitmap(位图),它的每一位(bit)对应一个用户,如果某位是1,就代表对应用户有这个标签。
- 比如用户ID为1、3、5的用户是VIP。
tag:vip这个Bitmap的第1、3、5位就被设置为1(二进制表示就是 ...0010101)。 - 打标签:
SETBIT tag:vip 1 1SETBIT tag:vip 3 1SETBIT tag:vip 5 1 - 圈人查询:找既是“VIP”又是“北京”的用户,用位运算的交集:
BITOP AND result_tag tag:vip tag:beijing,这个操作在CPU层面执行,快得飞起。
- 比如用户ID为1、3、5的用户是VIP。
-
优点:
- 内存杀手级节省: Bitmap是压缩存储的,一个标签记录一亿用户的状态,大概只需要12MB左右的内存,节省得令人发指,这是Set完全没法比的。
- 运算极快: 位运算是计算机的强项,处理海量数据时优势巨大。
-
坑点:
- 用户ID必须数字化: 你得有一套连续(或比较连续)的数字ID体系,不能直接用UUID那种字符串,否则玩不转。
- 稀疏数据不划算: 如果你的标签是个偏门标签,只有几千个用户,用Bitmap反而可能更占内存,因为Redis会分配一个完整的位图段。
- 小心稀疏位图: Redis的Bitmap是自动扩展的,如果你一不小心给一个超大用户ID(比如一亿)打标签,Redis会瞬间分配一个足以容纳一亿位的位图,可能直接打满内存,所以用户ID的生成要合理控制。
避坑指南:实战中的血泪教训
- Key的设计是门艺术: 别瞎起名,像
tag:1000:vip这种,1000是标签ID,清晰明了,千万别用含糊的Key,不然后期维护想死,参考阿里云的Redis规范,用冒号分隔,做到见名知意。 - 别让Redis“单干”: 用户画像系统≠Redis,用户的基础属性(姓名、手机号)、标签的元数据(标签名、创建时间)等,还是得老老实实存在MySQL等数据库里,Redis只干它最擅长的活儿:存储标签关系和快速查询,这叫“各司其职”。
- 过期时间(TTL)策略: 有些标签是有时效的,近7天活跃”,一定要给这些临时标签的Key设置TTL,让他们自动过期,不然垃圾数据会堆满你的内存。
- 集群模式下的坑: 在Redis集群中,多个Key的操作(比如求交集SINTER)要求这些Key必须在同一个哈希槽(slot)上,你需要用
{tag}这种哈希标签来保证,比如把{user_tag}:vip和{user_tag}:beijing强制放到同一个槽里,否则命令会失败。 - 数据一致性是个麻烦事: 用户注销了,你怎么把他从所有标签集合里删掉?如果同时有多个系统在打标签,如何保证不出错?这通常需要引入消息队列或者binlog同步等更复杂的架构来保证,不能光靠Redis。
- 小公司、初创项目,标签和用户量不大,用Set,省心省力。
- 中大公司,数据量海了去了,必须上Bitmap,为了省内存,前期麻烦点也值得。
- 永远记住Redis是缓存,不是数据库,重要数据要有备份和持久化方案。
- 性能测试不能少,在上线前,用真实数据量模拟一下最复杂的查询场景,看看Redis会不会扛不住。
搞用户画像,Redis是神器,但用不好也容易伤到自己,希望这些实操和坑点能帮你少走点弯路。

本文由帖慧艳于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/72540.html