Redis读库同步写缓存加锁这事儿,怎么能又快又稳地搞定呢?

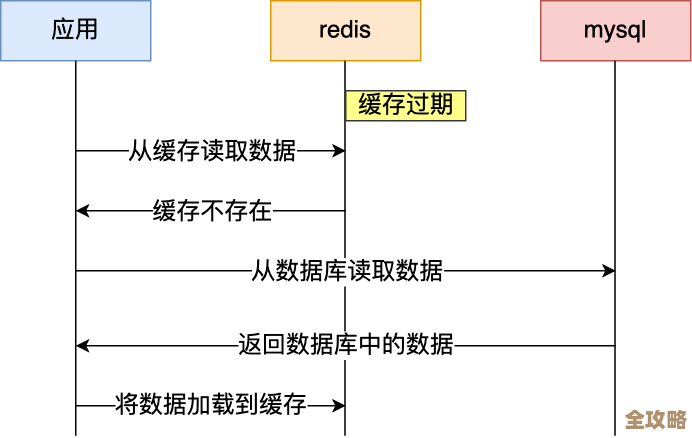
这事儿说白了,就是在高并发的场景下,当缓存(比如Redis)里没有我们要的数据时,我们需要去数据库(比如MySQL)里查,然后把查到的结果写到缓存里,这个“查数据库”和“写缓存”的过程,如果控制不好,就会引发一堆麻烦,核心目标就两个:快(低延迟、高吞吐)和稳(数据一致、防止雪崩)。
先说说最基础的玩法:先更库,再删缓存。
这不是加锁,而是一种降低不一致概率的策略,思路很简单:当有数据更新时,先去把数据库里的数据更新了,然后立刻把缓存里对应的旧数据删掉。

- 为啥这么做? 你想啊,如果先删缓存再更库,在删完缓存但数据库还没更新完的这个极短间隙里,另一个请求过来发现缓存没了,就会去读数据库里的旧数据,然后把这个旧数据又塞回缓存,导致缓存里一直是脏数据,反过来,先更库再删缓存,虽然理论上也存在极小概率的脏数据问题(比如在数据库更新完但缓存还没删掉的瞬间,有请求读了旧缓存),但因为数据库写操作通常比读操作慢,这个时间窗口非常非常小,出问题的概率低很多。
- 优点: 实现简单,没有加锁的性能损耗,大部分情况下表现不错。
- 缺点: 不是百分百保证一致性,属于一种折中方案,如果删缓存失败了,还得有重试机制,不然就一直是脏数据。
再说说怎么加锁才能又快又稳。
当多个请求同时发现缓存失效(比如缓存过期),都会涌向数据库,这就是臭名昭著的“缓存击穿”,搞不好会把数据库打挂,这时候就需要“锁”来保护数据库。
分布式锁(求“稳”的经典做法)

思路是:只让一个请求去读数据库写缓存,其他请求等着,等它搞定了,直接从缓存里拿数据。
- 怎么实现? 通常用Redis自己实现一个分布式锁,比如用
SETNX(SET if Not eXists)命令,只有第一个请求能设置成功,相当于拿到了锁,拿到锁的请求去读库,写完缓存后,再释放锁,其他没拿到锁的请求可以循环等待一小会儿,等锁释放后就能从缓存读到数据了。 - 关键点:
- 锁的过期时间: 一定要给锁设置一个过期时间,比如5秒,这是为了防止拿锁的请求因为某种原因(如应用崩溃)一直不释放锁,导致其他请求永远等待(死锁)。
- 谁加的锁谁释放: 释放锁的时候要确保是同一个请求释放的,避免把别人的锁给释放了,可以在锁的值里存一个唯一标识(比如UUID)。
- 锁失败的处理: 没拿到锁的请求怎么办?常见的做法是“锁等待+重试”,即等一小段时间(比如100毫秒)再尝试获取锁或直接查缓存,也可以直接返回一个默认值或者错误提示,取决于业务场景。
- 优点: 能很好地保护数据库,防止缓存击穿,保证了数据的一致性。
- 缺点: 引入锁会带来一定的性能开销,增加了系统的复杂度,如果锁的粒度没控制好(比如锁的key太粗),还会影响并发性能。
逻辑过期时间 + 异步刷新(求“快”的优化方案)
这是一种“用空间换时间”的思路,完全避免在热点key失效时请求打到数据库。

- 核心思想: 我们不在Redis里设置key的物理过期时间(TTL),而是把过期时间作为一个字段,和业务数据一起存入缓存的值(value)中。
- 工作流程:
- 请求A查缓存,发现数据还在(因为没设物理TTL)。
- 它检查数据里的逻辑过期时间,发现已经过期了。
- 这时,请求A不会自己去查数据库,而是果断返回当前这个已经过期的旧数据给用户(虽然旧了点,但可能还能用,保证了速度)。
- 同时,请求A会尝试获取一个分布式锁,如果获取成功,它就异步地开启一个线程(或提交一个任务)去数据库拉取最新数据,然后更新缓存(同时更新逻辑过期时间),如果获取锁失败,说明已经有别的请求在后台更新了,它就不用管了。
- 优点: 用户请求几乎不会因为缓存更新而阻塞,响应非常快,用短暂的“脏读”换取了极高的吞吐量,非常适合对一致性要求不是那么极致(比如资讯、商品描述等),但对性能要求极高的场景。
- 缺点: 存在一段时间的“脏读”窗口期(从逻辑过期到后台更新完毕),不能保证强一致性,实现起来更复杂一些。
怎么选择?怎么结合才能又快又稳?
没有银弹,需要根据业务场景权衡。
- 对一致性要求极高(如库存、金额): 优先考虑分布式锁方案,为了更快,可以优化锁的粒度(锁的key要细,比如锁具体某个商品ID,而不是锁整个库存操作),并设置合理的锁超时时间。
- 对性能要求极高,允许短暂不一致(如文章详情、商品页): 可以采用逻辑过期 + 异步刷新的方案,这是“快”的极致体现。
- 一种常见的折中实践:
- 大部分场景使用 “先更库,再删缓存” ,简单有效。
- 针对少数明确的、访问量巨大的热点key,采用分布式锁来防止缓存击穿,可以通过提前预热缓存、设置不同的过期时间等手段,尽量减少缓存同时失效的概率。
- 在极端追求性能的场景下,对特定key启用逻辑过期。
别忘了“稳”的其他基石:
- 缓存空对象: 如果数据库也查不到,就在缓存里存一个空值(或特殊标记)并设置一个较短的过期时间,防止反复查询不存在的数据攻击数据库。
- 设置合理的过期时间: 给不同的数据设置不同的、随机的过期时间,避免大量缓存同时失效,引发“缓存雪崩”。
- 做好降级和熔断: 如果Redis挂了呢?系统要有能力直接读数据库,哪怕慢点,也要保证核心服务可用。
又快又稳地搞定这事儿,关键在于理解业务需求,灵活组合“删缓存”、“分布式锁”、“逻辑过期”这几样工具,并做好各种异常情况的兜底处理,没有一劳永逸的方案,只有最适合当前场景的权衡之策。
本文由召安青于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/72265.html