数据库集群节点状态怎么查?各种方法和技巧都在这儿分享给你看看

数据库集群节点状态怎么查?各种方法和技巧都在这儿分享给你看看
想知道数据库集群里的各个节点是不是都好好的,有没有掉队或者生病(出现故障)的,这是管理集群最基础也最重要的一步,不同的数据库软件有不同的检查方法,但思路都差不多,下面我们就分门别类地说一说。
通用方法:通过数据库管理系统自带的工具或视图

这是最直接、最准确的方法,因为数据库自己最清楚自己的状态。
-
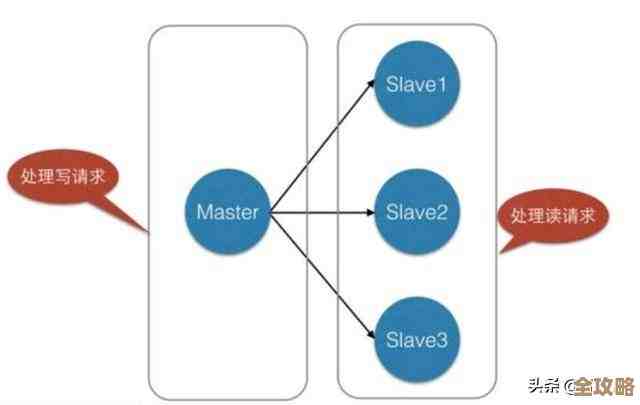
对于 MySQL 集群(特别是 Percona XtraDB Cluster / Galera Cluster)
- 最常用的命令: 登录到任何一个集群节点,执行 SQL 语句
SHOW STATUS LIKE 'wsrep%';,这个命令会显示一大堆以wsrep开头的状态变量,它们是查看 Galera 集群健康度的关键。 - 重点看这几个:
wsrep_cluster_size:这个数字直接告诉你当前集群里有多少个节点是正常在线的,如果你配置了3个节点,但这里显示2,那肯定有一个节点掉线了。wsrep_cluster_status:这个会显示当前节点的状态,正常情况应该是Primary,如果变成Non-Primary,说明出现了脑裂等严重问题。wsrep_ready:这个值是ON就表示该节点可以正常处理读写请求,如果是OFF,说明它可能因为网络问题或数据不一致等原因被暂时隔离了。wsrep_connected:显示该节点是否与其他节点保持着网络连接。
- 另一个简单命令: 也可以执行
SHOW GLOBAL STATUS LIKE 'wsrep%';,效果类似。
- 最常用的命令: 登录到任何一个集群节点,执行 SQL 语句
-
对于 PostgreSQL 集群(例如基于流复制的集群)

- 在主节点上查看: 执行
SELECT * FROM pg_stat_replication;这个视图非常强大,它会列出所有正在连接到这个主节点的备库(从节点)的信息。- 你可以看到每个备库的 IP 地址、复制状态(
streaming就表示流复制正常)、复制延迟 等重要信息,如果这个表是空的,可能意味着没有备库在正常工作。
- 你可以看到每个备库的 IP 地址、复制状态(
- 在备节点上查看: 执行
SELECT pg_is_in_recovery();,如果返回t(true),说明这个节点是一个只读的备节点,如果返回f(false),说明它是可写的主节点。
- 在主节点上查看: 执行
-
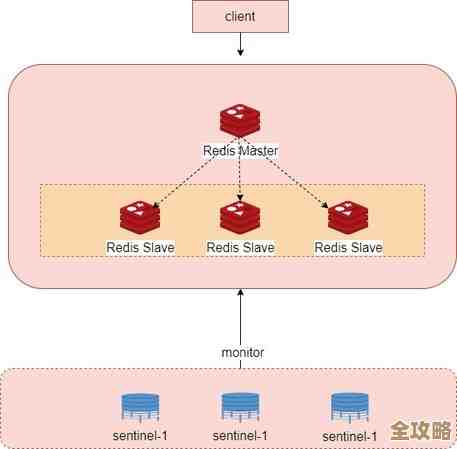
对于 Redis 哨兵(Sentinel)集群
- Redis 用哨兵来监控主从节点,你可以连接上任何一个哨兵实例(注意是哨兵的端口,默认是26379,不是Redis的6379)。
- 关键命令: 使用
redis-cli连接哨兵后,执行sentinel masters会列出所有被监控的主节点及其状态,执行sentinel slaves <master-name>可以查看指定主节点下的所有从节点信息,包括它们的运行状态和复制偏移量。
-
对于 MongoDB 复制集(Replica Set)
- 连接上 MongoDB 的任何一个节点,在管理员权限下执行
rs.status(),这个命令会返回一个非常详细的结果。 - 在返回的信息里,你需要关注每个成员的 "stateStr" 字段,常见的状态有:
PRIMARY:主节点。SECONDARY:健康的从节点。STARTUP,RECOVERING:启动或恢复中,是临时状态。DOWN:节点无法连接。UNKNOWN:状态未知,通常也是网络或通信问题。
- 连接上 MongoDB 的任何一个节点,在管理员权限下执行
借助第三方监控系统

除了手动敲命令,更省心的方法是使用现成的监控系统,这些系统会定期帮你执行上述检查,然后用漂亮的图表展示出来,出现问题时还会自动发警报。
- Prometheus + Grafana: 这是现在非常流行的组合,你需要先在数据库集群中部署一个“导出器”(exporter),MySQL 有
mysqld_exporter,PostgreSQL 有postgres_exporter,这个导出器负责收集数据库的各种状态指标,Prometheus 会定时来抓取这些数据,最后在 Grafana 上做成可视化的仪表盘,你一眼就能看到集群大小、节点延迟、负载等所有信息。 - Zabbix / Nagios: 这些是老牌的企业级监控工具,它们通过自定义的监控脚本或模板,去连接数据库并执行特定的查询(就像我们上面手动的那些命令一样),然后根据返回值判断节点是否健康。
操作系统层面的辅助检查
有时候数据库进程本身还在,但可能已经“卡死”了,或者网络出现了问题,这时需要结合系统命令来判断。
- 检查进程是否存在: 在服务器上执行
ps -ef | grep mysql(以MySQL为例),看看数据库主进程是否在运行。 - 检查网络连通性: 使用
ping命令检查节点之间的网络是否通畅,更进一步的,可以用telnet <IP地址> <端口号>来测试数据库的服务端口是否能连通。 - 检查系统资源: 使用
top或htop命令查看服务器的 CPU、内存使用率,如果资源耗尽,数据库节点也会表现异常。
总结一下技巧:
- 不要只查一个节点: 养成从不同节点查询的习惯,比如在A节点上看到B节点掉了,最好再登录C节点或者直接尝试连接B节点确认一下,避免是网络瞬断或查询工具本身的问题。
- 关注核心指标: 对于集群,最核心的就是 节点数量 和 复制延迟,先把这两个盯紧了,大部分严重问题都能及时发现。
- 自动化是王道: 手动检查只能用于临时排查,生产环境一定要配置监控告警,让系统主动通知你,而不是等你发现。
希望这些具体的方法和思路能帮你更好地掌握数据库集群的健康状况!
本文由黎家于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/71863.html