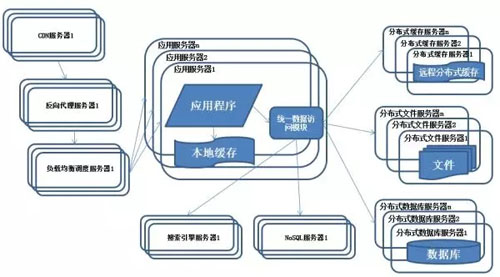
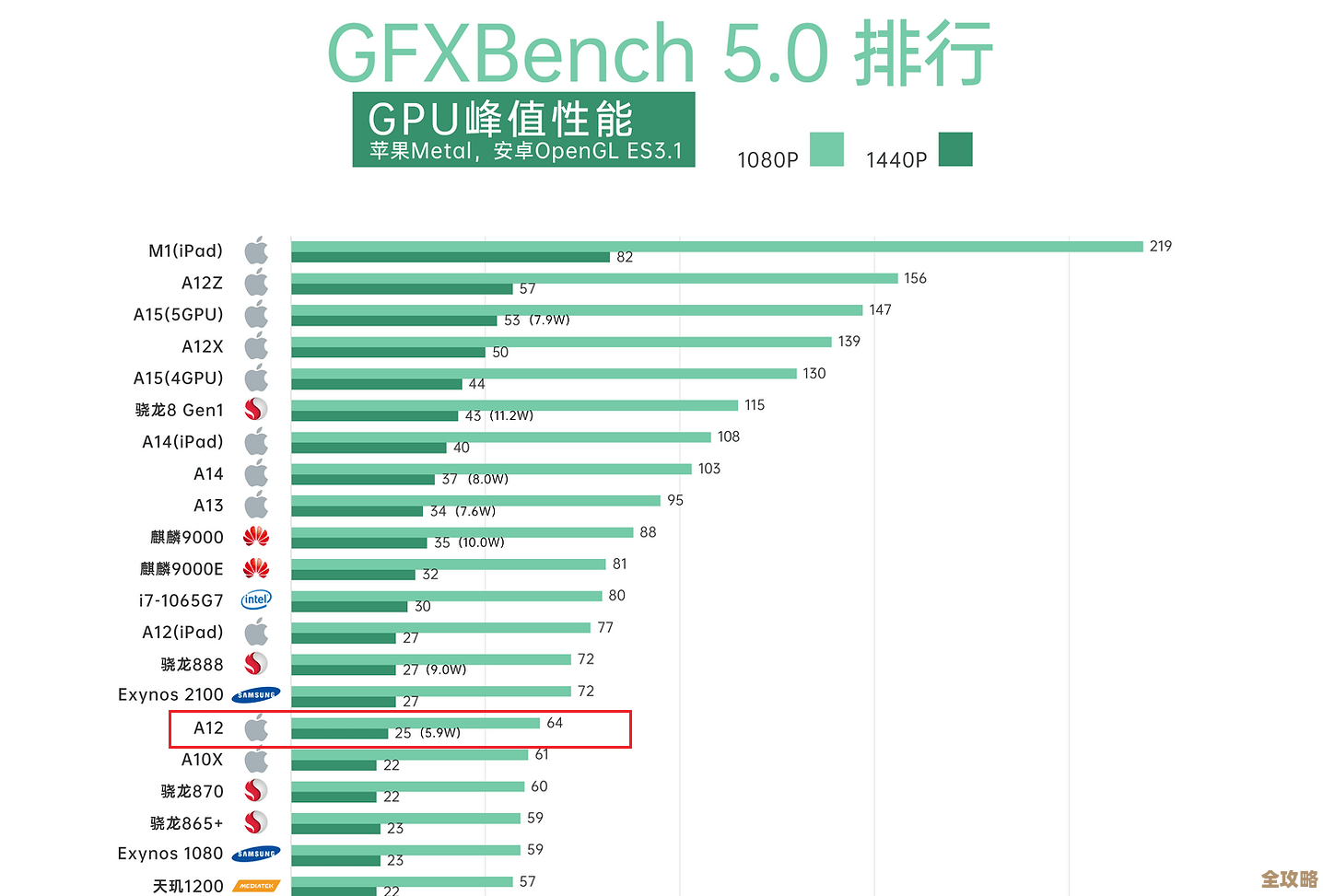
DB2里那个聚集目标表到底是怎么回事,为什么大家都在用它做数据整理和查询优化

说到DB2里的聚集目标表,这其实是大家在实际工作中为了方便理解而起的一个“花名”,它在DB2的官方术语里,更准确地说是物化查询表,或者英文叫Materialized Query Table,简称MQT,你把它理解成一个“预先计算好的结果集”或者“数据快照”就非常形象了。(来源:IBM DB2官方文档关于MQT的核心定义)
它到底是怎么回事?
想象一下这个场景:你是一家大公司的数据分析师,老板经常要你出一份销售报表,报表需要统计每个地区、每个产品类别在过去一个季度的总销售额和平均订单金额,这个查询本身不复杂,但它要扫描过去三个月里上亿条的订单明细记录,每次运行都要花上好几分钟,甚至更久。
这时候,聚集目标表(MQT)就派上用场了,你可以这样做:
- 创建一个表:这个表的定义不是你手动指定有哪些字段(比如订单号、客户名),而是直接写成那条复杂的汇总查询语句,你的创建语句可能就是“SELECT 地区, 产品类别, SUM(销售额) as 总销售额, AVG(订单金额) as 平均金额 FROM 原始大表 GROUP BY 地区, 产品类别”。
- “物化”过程:DB2会根据你这个定义,实实在在地、一次性地去执行这个查询,然后把查询结果——也就是汇总好的数据(比如最后可能就只有几千行,按地区和产品类别分好的汇总数据)——存储在一个真正的物理表里,这个物理表就是聚集目标表。(来源:对DB2 MQT物化过程的普遍解释)
它不是一个视图(视图只是保存查询逻辑,每次查询还是要去底层表现场计算),而是一个装着“现成答案”的实体表。
为什么大家都在用它做数据整理和查询优化?
原因非常直接,就两个字:快和省。
查询速度的飞跃(快) 这是最核心的好处,当你的老板再次要那份报表时,DB2的优化器是非常聪明的,它会发现“咦,这个查询请求的数据,好像在那个聚集目标表里已经有现成的了!”它就不会再傻乎乎地去扫描上亿条的原始订单表,而是直接去查询那个只有几千行数据的聚集目标表,这个速度的提升是数量级的,可能从几分钟变成一秒甚至毫秒级,这对于需要高频访问汇总数据的报表系统、决策支持系统来说,体验是颠覆性的。(来源:数据库性能优化实践中对MQT作用的普遍共识)
减轻系统负担(省)
- 省计算资源:每次复杂的GROUP BY、JOIN操作都会大量消耗CPU和内存,现在这些耗力的计算工作只在数据刷新时(比如每天凌晨)进行一次,而不是在每天业务高峰期的每次查询时都发生,这大大降低了数据库主机的压力。
- 省I/O资源:读取几千行的小表,和扫描上亿行的大表,对磁盘I/O的压力是天壤之别,减少了I/O争抢,整个系统的其他业务查询也会运行得更流畅。
数据整理的维度 “数据整理”在这里体现在,它帮你把散乱的、颗粒度很细的原始数据(比如每笔交易记录),按照业务需求,聚合成结构清晰、颗粒度较粗的汇总数据,这本身就是在为分析型查询准备一个“干净”、“规整”的数据集市,数据分析师可以直接基于这个整理好的表进行更上层的钻取和分析,而不必每次都从最底层开始构建查询,降低了复杂度也减少了出错的可能。
使用时的关键点和注意事项
这么好用的东西也不是没有代价的,主要在于数据同步问题。
既然聚集目标表是某个时间点的“快照”,那么当底层原始表的数据发生变化(比如新增了订单、修改了销售额)时,这个快照就会“过期”,如何更新它就成了关键,DB2提供了几种刷新模式:(来源:IBM DB2文档中关于MQT刷新模式的说明)
- 即时刷新:一旦底层数据有变动,MQT立刻更新,这能保证数据绝对实时,但对性能有持续影响,适合更新不频繁但对实时性要求极高的场景。
- 延迟刷新:这是更常见的做法,数据变更先被记录下来,等到一个合适的时机(比如执行
REFRESH TABLE命令时,或者在一个事务提交后)再批量更新MQT,这是一种在数据新鲜度和系统性能之间的折衷。 - 按需刷新:完全由管理员手动控制刷新时机,通常用于数据仓库环境,结合ETL流程,在每天夜间业务低峰期进行全量或增量刷新。
大家在使用聚集目标表时,需要根据业务对数据实时性的要求,精心设计刷新策略,如果业务要求看到的是实时数据,那么可能就不太适合用延迟刷新的MQT。
DB2的聚集目标表(MQT)本质上是一个用空间换时间的经典优化手段,它通过预先计算并存储昂贵的查询结果,将运行时的大量计算和I/O消耗,转移到了非高峰期的预处理阶段,从而极大地提升了高频汇总查询的响应速度,并减轻了系统整体负担,这正是它在数据整理和查询优化领域备受青睐的根本原因。

本文由符海莹于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/71380.html