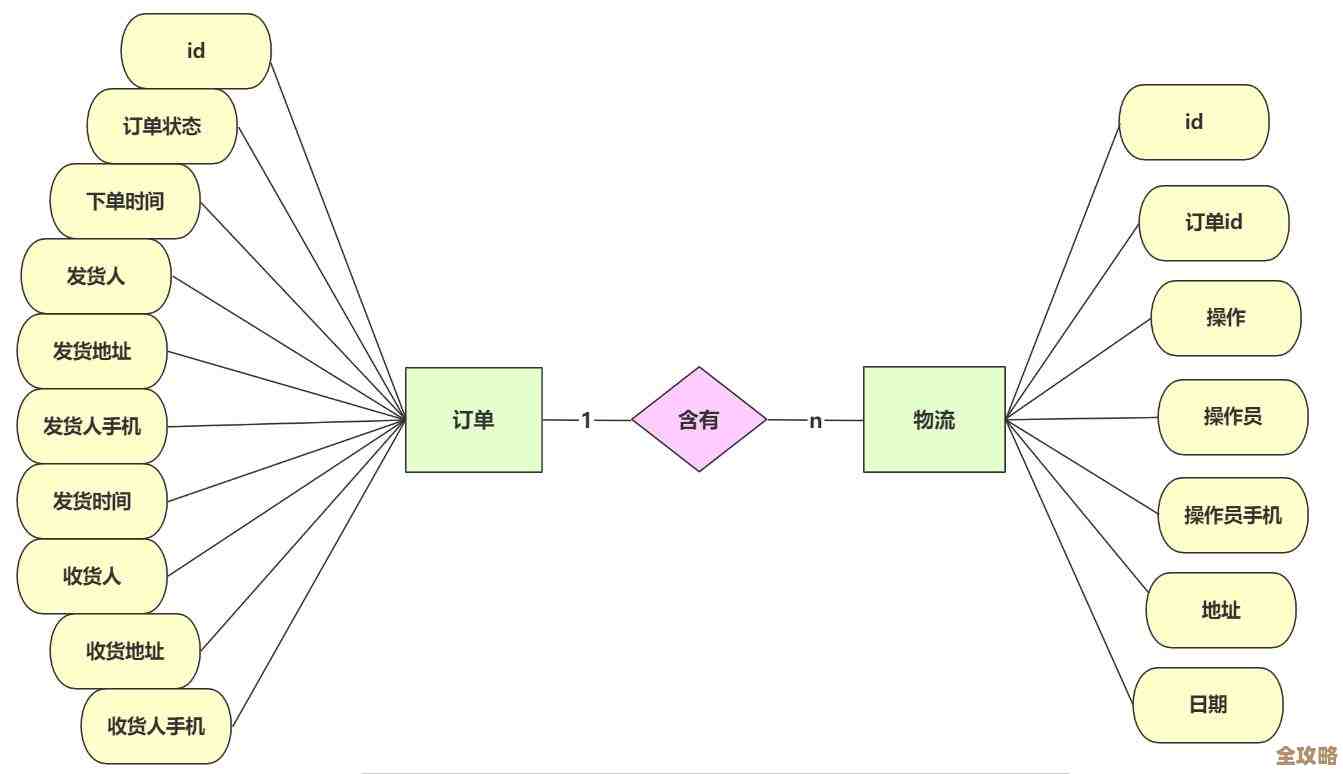
应急处理Redis集群从节点故障,快速搭建稳固又不慌乱的方案

当Redis集群中的一个或多个从节点突然发生故障时,首要任务是保持冷静,避免因慌乱而做出错误操作,一个稳固的应急方案核心在于“先稳住当前,再恢复故障,最后复盘优化”,整个过程可以分为故障发现与评估、应急处理、故障恢复和事后复盘四个关键阶段。
第一阶段:快速发现与评估,做到心中有数
当监控系统(如Prometheus、Zabbix或云监控服务)发出告警,提示某个从节点连接失败、同步中断或服务不可用时,不要立即上手重启或修复,首先需要花几分钟时间进行快速评估,这能避免误判。
-
确认故障范围与影响:登录集群管理工具(如Redis Insight)或使用
redis-cli --cluster check命令,快速检查整个集群的状态,关键要确认:- 故障的是否真的只是从节点?主节点是否健康?
- 该从节点对应的主节点是否运行正常?如果主节点也异常,那么优先级完全不同,需要立即启动主从切换预案。
- 集群是否仍然能够正常提供服务?即,是否每个主节点都至少有一个健康的从节点?如果某个主节点失去了所有从节点,它就处于“裸奔”状态,风险极高,需要优先处理。
- 业务侧是否已经感受到影响?是否出现了读性能下降(因为读请求无法分发到故障的从节点)?
-
初步判断故障原因:通过查看Redis日志、系统日志(如
/var/log/messages或dmesg)以及监控图表,尝试判断故障原因,常见原因包括:- 机器层面:服务器宕机、网络中断、磁盘写满。
- 进程层面:Redis进程因内存不足(OOM)被系统杀死、Redis本身bug导致崩溃。
- 同步层面:主从之间网络延迟过高,从节点同步落后(Replication Lag)过多,导致从节点被判定为失效。
这个阶段的目标是:用最短的时间搞清楚“发生了什么”和“可能的原因”,而不是“马上解决它”。(来源:常见的故障处理SOP原则)
第二阶段:立即采取的应急行动,稳住阵脚
在评估清楚影响后,根据不同的情况采取相应措施,核心是保证主集群的稳定运行。
-
如果故障不影响核心业务:某个主节点有多个从节点,只坏了一个,业务读流量可以自动切换到其他从节点,那么应急的重点是“隔离”故障节点,防止它可能对集群产生其他干扰,可以将其从集群中临时移除(使用
redis-cli --cluster del-node命令),告诉集群:“这个节点暂时不管了”,这样集群就不会再尝试向它分发数据或检查其状态。
-
如果故障导致风险升高:某个主节点只剩下一个从节点,现在这个从节点也故障了,导致该主节点没有备份,此时的应急措施是:
- 优先保障主节点:确保主节点的资源(CPU、内存、网络)充足,避免任何可能引起主节点波动的操作。
- 考虑临时调整架构:如果条件允许,可以快速从一个健康的、负载较低的主从组中,临时“借”一个从节点,通过
redis-cli --cluster add-node命令将其添加为高风险主节点的新从节点,先建立起复制关系,化解单点风险,这是一种“拆东墙补西墙”的临时策略,但能有效降低整体风险。
-
与业务方沟通:如果故障可能导致读性能下降或潜在风险,应及时通知业务方,告知当前状态和可能的影响,管理好预期。
切记:在情况没有完全明确前,尤其是在主节点健康的情况下,避免对主节点进行重启等高风险操作。
第三阶段:有条不紊地恢复故障节点
当集群整体稳定后,开始着手恢复故障的从节点。

-
解决根本问题:根据第二阶段判断的原因,修复底层故障,清理磁盘空间、重启宕机的虚拟机、解决网络分区问题等。
-
重新加入集群:确保节点服务器和Redis进程恢复正常后,将其重新加入集群。这里有一个关键点:如果从节点故障时间较长,它保存的旧数据可能已经远远落后于主节点,直接让它以从节点身份同步,可能会因为数据差异太大而导致主节点需要生成并传输整个数据集的快照(RDB),这个过程会大量消耗主节点的CPU和网络资源,可能影响主节点性能。
- 推荐做法:优先采用“空节点重新同步”策略,即,先清空故障节点上的所有数据(删除
dump.rdb、appendonly.aof文件或清空数据目录),然后以一个全新的、空数据的节点身份重新加入集群,让它执行全量同步,这样虽然同步过程需要时间,但对主节点的冲击是可控的、一次性的,相比于在同步过程中因资源竞争导致主节点卡顿,这种“长痛不如短痛”的方式更稳妥。(来源:Redis官方文档关于主从复制的建议)
- 推荐做法:优先采用“空节点重新同步”策略,即,先清空故障节点上的所有数据(删除
-
验证数据同步:节点加入后,使用
info replication命令持续监控其同步状态,直到slave_repl_offset与主节点的master_repl_offset基本一致,确认数据同步完成。
第四阶段:事后复盘与加固,告别慌乱
故障恢复后,工作并未结束,必须进行复盘,将这次意外转化为系统加固的机会。
- 根因分析:深入分析导致从节点故障的根本原因,是硬件老化?是配置不合理(如内存不足)?还是网络架构有缺陷?
- 优化监控告警:检查现有的监控指标和告警阈值是否足够灵敏、准确?能否更早地发现问题?增加对主从同步延迟(Replication Lag)的监控告警,在延迟超过一定阈值时就发出警告,而不是等到完全中断。
- 完善应急预案:将本次处理过程中验证有效的步骤固化下来,形成详细的、可操作的应急预案(Runbook),并组织相关人员进行演练。
- 架构优化:考虑是否可以通过优化架构来提升容错能力,比如增加关键分片的从节点数量,或者采用更高可用性的架构。
通过以上四个阶段的步骤,不仅能够快速、稳定地处理单次从节点故障,更能逐步提升整个Redis集群的稳健性和团队的应急能力,真正做到面对故障时“稳固又不慌乱”。
本文由钊智敏于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/70970.html