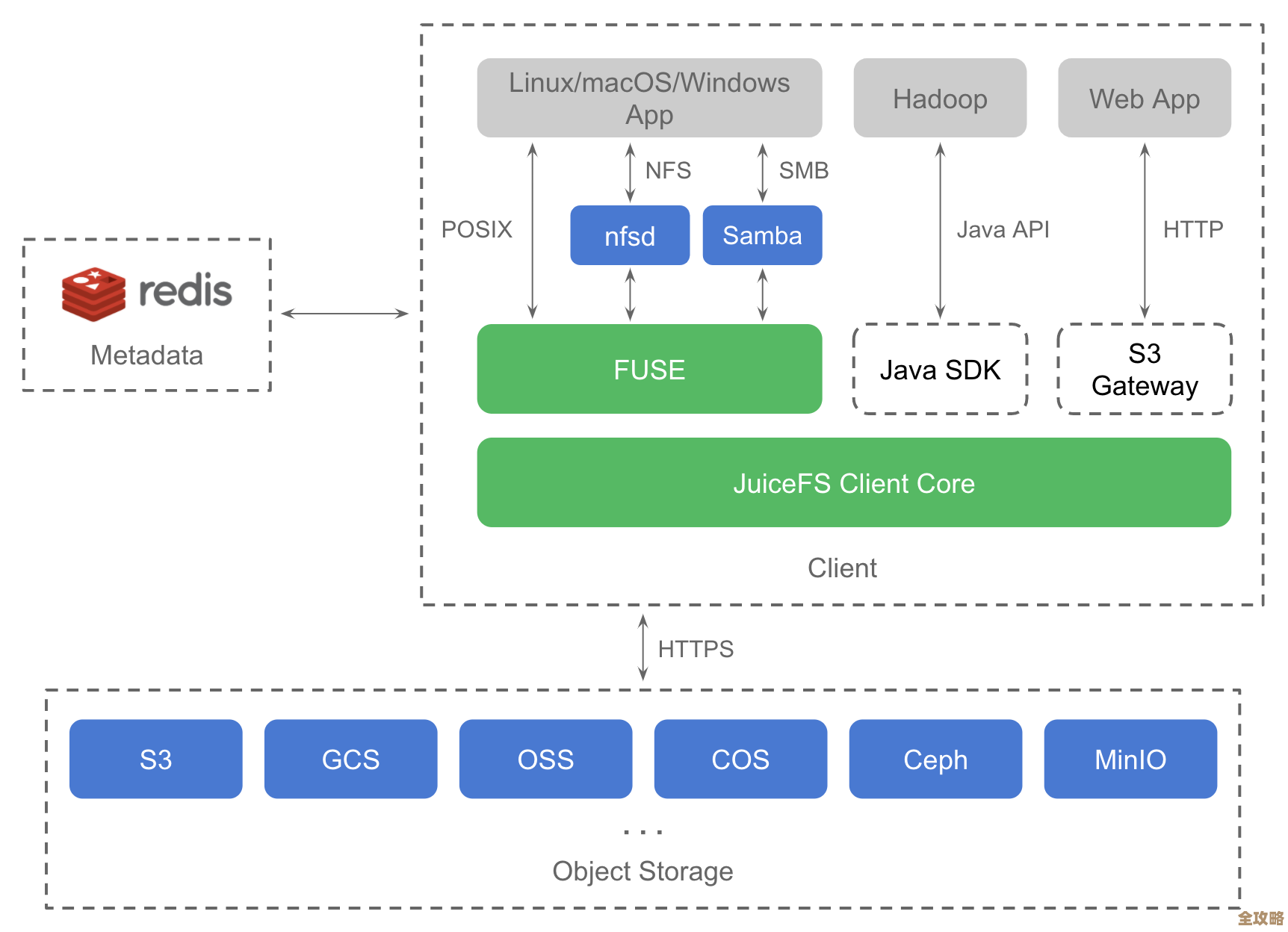
用Redis搞数据字典,顺便搭个复杂点的数据存储架构试试看

说到用Redis搞数据字典,这想法其实挺实在的,Redis这东西,快得像闪电,尤其适合放那些不怎么变但又经常被查的数据,数据字典就是典型,比如国家列表、城市列表、商品分类、状态码说明这些,你要是把这些东西老放在MySQL里,每次页面下拉框加载或者显示个状态名称都要去查一次数据库,数据库压力大,速度也快不起来。
那最简单的搞法就是,直接把字典表从MySQL里捞出来,一股脑塞进Redis,比如有个“商品分类”表,里面有分类ID、分类名称、父级ID这些字段,你可以用Redis的Hash结构来存,Key就叫 dict:product_category,然后把每个分类ID作为Field,把分类名称或者其他信息打包成JSON字符串作为Value,这样,应用要查分类名称,直接 HGET dict:product_category 1 就出来了,速度飞起,或者你想根据父级ID查所有子分类,那就在存的时候动点脑筋,比如再用一个Set结构,Key叫 dict:product_category:parent:0,里面放着所有顶级分类的ID,查的时候先从这个Set里拿到子分类ID列表,再去Hash里批量取详情,用 HMGET 命令,也很快。

但这只是开胃小菜,你说要搭个“复杂点的数据存储架构”,那咱们就得往深了想,光用Redis做缓存有个致命问题:数据一致性,你Redis里的数据是来自MySQL的,万一MySQL里的字典数据更新了(比如管理员后台修改了个分类名),Redis里的还是旧数据,那用户就看到不一致的东西了,得有个机制保证两边同步。
这时候,架构就得复杂一点了,一个比较靠谱的思路是“订阅数据库变更日志”,像阿里巴巴开源的Canal(来源:阿里巴巴Canal官方文档),它就能干这个事,你可以把Canal伪装成MySQL的一个从库,它实时监控MySQL的binlog(就是数据库的所有操作记录),当你在MySQL里对字典表进行了增删改,Canal会立刻捕捉到这个变化,然后把这个变化事件推送给一个消息队列,比如RabbitMQ或者Kafka(来源:常见的消息队列技术选型)。

你需要写一个简单的数据同步服务,这个服务就订阅这个消息队列,它一收到“某个字典表有更新”的消息,就立刻去MySQL里把最新的数据查出来,然后更新到Redis里,这样,Redis和MySQL的数据就能近乎实时地保持一致了,这个架构虽然多了Canal、消息队列和同步服务这几个组件,但好处是解耦了,应用代码不用关心数据同步的脏活累活,只需要安心地从Redis里读就行,保证了高性能,即使同步服务暂时挂了一会儿,消息也会积压在队列里,等服务恢复了还能继续处理,保证了可靠性。
再往复杂里说,光同步可能还不够,还得考虑Redis本身的高可用,万一Redis这台机器宕机了,所有请求就会直接压到数据库上,可能直接把数据库打挂,通常会给Redis搭一个主从复制加哨兵(Sentinel)的模式(来源:Redis官方高可用方案),简单说就是,一台Redis当主节点(Master)负责写,多台当从节点(Slave)同步主节点的数据,负责读,哨兵呢,就是个监控系统,它时刻盯着主节点是否活着,一旦发现主节点挂了,就立马从从节点里投票选出一个新的主节点,让应用连上去,这样,Redis服务本身就不容易单点故障了。
甚至,对于极其重要的字典数据,你还可以考虑做持久化,虽然字典不常变,但丢了重新从数据库加载也麻烦,Redis本身支持RDB(快照)和AOF(记录所有写命令)两种持久化方式(来源:Redis官方持久化机制),可以开启以防万一。
应用层怎么用这个架构呢?代码里最好封装一个统一的字典服务,这个服务先去Redis里查数据,如果Redis里查不到(比如刚启动,缓存是空的),有个保护机制叫“缓存降级”,它不能直接疯狂查数据库,那样会引起“缓存雪崩”,应该用个互斥锁,只让一个请求去数据库查,然后塞到Redis里,其他请求等着,查到了数据,可以设置个合理的过期时间,比如24小时,这样即使同步服务出问题,最晚一天后缓存失效,数据也会从数据库刷新一次,不会永远脏下去。
所以你看,一个看似简单的“用Redis搞数据字典”,真要把它做得稳健、高性能、高可用,背后能牵引出一套包含缓存、数据库、日志订阅、消息队列、同步服务、高可用集群和降级策略的、稍微复杂点的存储架构,这就像盖房子,不是简单把砖头(Redis)垒起来就行,还得考虑地基(MySQL)、钢筋(消息队列)、水电线路(数据同步)和应急预案(降级高可用),这样才能经得起风雨。

本文由畅苗于2025-12-27发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/69636.html