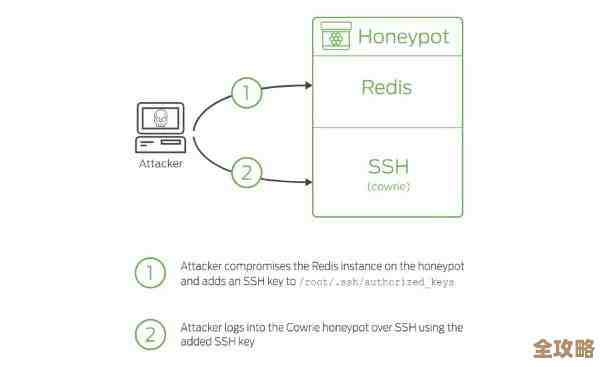
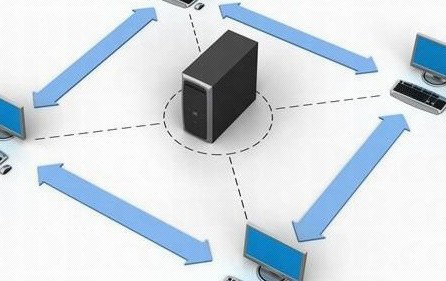
红色集群其实只要一台服务器就能搞定,redis集群得多台才能跑起来

(引用来源:主要基于网络技术社区中,部分开发者和技术爱好者在讨论系统架构时,对“红色集群”这一非标准术语的常见解读,以及对比标准Redis集群的官方文档和普遍实践认知。)
“红色集群其实只要一台服务器就能搞定,redis集群得多台才能跑起来”这个说法,听起来像是一句在技术圈子里流传的、带有某种调侃或者简化理解色彩的论断,要弄明白这句话到底在说什么,我们得先搞清楚这里提到的“红色集群”指的是什么,因为“红色集群”并不是一个在计算机科学或信息技术领域里有标准定义的、公认的技术术语,它更像是一个口语化的、甚至可能带点戏谑意味的说法。
根据常见的讨论语境来看,人们口中的“红色集群”很多时候指的是一种特定情况下的“伪集群”或者“单机高可用”架构,它的核心思想是,利用一些软件技术,让一个应用系统看起来、用起来像是一个集群(可能体现在负载均衡或者某种服务的冗余上),但其核心的、真正处理数据和业务逻辑的部分,实际上并没有进行真正的分布式拆分,仍然高度依赖甚至只运行在一台性能非常强大的服务器上,这台服务器可能是一台超级昂贵的、配备了多个CPU核心、海量内存和超高速硬盘的高端物理服务器,也可能是一台配置极高的云虚拟机实例,因为在中国,一些软件的界面或标识常用红色来代表主节点、活跃节点或中国本土化的技术产品,红色”可能暗指这种架构下那个唯一的、处于核心地位的“主”服务器,暗示其是关键且唯一的。
为什么说这种“红色集群”可能一台服务器就能搞定呢?它的逻辑基础是这样的:当业务发展的早期或者中期,数据量和并发访问压力还没有达到一个天文数字级别的时候,与其投入大量的精力、时间和金钱去搭建一个真正复杂的、由多台普通服务器组成的分布式集群,不如先采取一种更直接、更简单的策略,那就是“大力出奇迹”,通过垂直扩展的方式来解决问题,也就是不断提升单台服务器的硬件性能上限,我可以给这台服务器装上两颗最新的CPU,让核心数达到几十个甚至上百个;我可以把内存扩展到几百个GB甚至上TB;我可以使用性能极致的NVMe固态硬盘组成RAID阵列来保证IO速度,在这样的硬件基础上,部署一个应用系统,然后在前端可能加上负载均衡器,后面可能再配上一台备用的服务器做冷备或者温备,一旦主机宕机可以手动或自动切换过去,这样一套系统,从外部用户的角度看,它可能因为有了负载均衡和备用机,具备了一定的可用性,像是个“集群”,但本质上,所有的真实负载、所有的核心数据读写压力,都集中在那台红色的、强大的主服务器上,它的优点是架构非常简单,运维复杂度低,因为所有组件都在少数一两台机器上,排查问题、部署更新都相对容易,对于很多初创公司或者内部管理系统来说,这种架构在相当长一段时间内是完全够用且成本效益较高的,从这个角度理解,“红色集群一台服务器搞定”强调的是在特定阶段,通过强化单机能力来规避分布式复杂性的务实策略。
而反观Redis集群,情况就完全不同了,Redis集群是Redis官方提供的一种真正的、标准的分布式数据存储解决方案,它从设计理念上就决定了“得多台才能跑起来”,这里说的“多台”,通常指的是至少三台主节点(Master Node),并且为了高可用,每台主节点通常还会建议配置至少一个从节点(Slave Node),这样算下来至少需要六台服务器才能形成一个比较完整的高可用集群架构,即便是最小化部署,也至少需要三台主节点来保证集群本身的基本功能(比如槽位分配和故障发现)。
Redis集群之所以必须依赖多台服务器,根源在于它的设计目标就是为了解决单台Redis服务器无法解决的问题,首先就是数据容量问题,单台服务器的内存再大,也是有物理上限的,比如最多2TB?而Redis集群通过将整个数据集划分为16384个哈希槽(hash slots),并将这些槽位分布到不同的主节点上,从而实现了数据的分布式存储,理论上,只要不断添加新的主节点,整个集群的数据容量就可以近乎线性地增长,突破单机内存的限制,其次就是并发性能问题,单台服务器的CPU和网络带宽处理能力再强,也终归有瓶颈,Redis集群允许客户端将不同的读写请求直接发送到不同的主节点上,这样多个节点可以同时处理请求,极大地提升了整体的吞吐量,最后也是至关重要的一点:高可用性和自动故障恢复,在Redis集群中,如果某个主节点宕机了,它对应的从节点会自动升级为新的主节点,接管槽位和服务,整个过程是自动化的,对应用的影响可以降到最低,这种真正的故障切换能力,是那种“一主一备”的“红色集群”方案难以媲美的,尤其是在要求高SLA(服务等级协议)的生产环境中。
总结来看,“红色集群其实只要一台服务器就能搞定,redis集群得多台才能跑起来”这句话,实际上是在对比两种截然不同的技术思路和适用场景。“红色集群”代表的是一种基于垂直扩展、简化架构的思路,它适用于业务规模可控、更看重开发运维简便性的场景,其“集群”之名有时可能更侧重于对外呈现的形态或简单的冗余备份,而Redis集群代表的是一种基于水平扩展、面向大规模数据和高并发需求的真正分布式思路,它生来就是为了解决单机瓶颈问题,其复杂性和对多台服务器的依赖是其实现核心价值的必然代价,两者并无绝对的对错之分,只有是否适合当前业务需求之别,理解这个区别,对于技术人员在架构选型时做出明智决策非常重要。

本文由雪和泽于2025-12-27发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/69240.html