用Redis集合做区间分页,保证数据不丢失也不卡顿的那些事儿

(引用来源:知乎专栏“技术夜谈”中《Redis实战:巧用Sorted Set分页的坑与梯》一文,以及个人项目实践经验)
用Redis集合做区间分页,保证数据不丢失也不卡顿的那些事儿,其实核心就是围绕着Redis里一个叫“有序集合”的数据结构展开的,这个东西不像普通的列表那么简单,它给每个成员都附带了一个分数,可以根据这个分数来排序,这就为我们做分页提供了天然的便利,但便利的背后,也藏着不少需要小心处理的细节,处理不好,要么数据会莫名其妙不见了,要么页面卡得让人心烦。
先说说为什么我们会想到用Redis的有序集合来做分页,最常见的情景就是排行榜、动态消息流这类东西,比如一个游戏里的玩家积分排行榜,或者微博的时间线,这些数据量可能很大,而且要求查询速度非常快,如果每次都去数据库里LIMIT offset, size,当页码很深的时候,数据库的压力会很大,速度就会慢下来,Redis把所有数据放在内存里,操作速度极快,用它来分页看起来是个不错的选择。

基本思路很简单:我们把要分页的数据的ID或者内容本身作为“成员”,把一个可以排序的字段(比如创建时间戳、积分)作为“分数”,全部塞进一个有序集合里,查第一页数据的时候,就用ZREVRANGE key 0 9 WITHSCORES命令(假设一页10条,ZREVRANGE是从大到小排,适合排行榜或时间线这种需要展示最新的场景),这就能拿到分数最高的前10个成员,查第二页,就用ZREVRANGE key 10 19 WITHSCORES,以此类推,看起来非常直观,对吧?但问题恰恰就出在这个“以此类推”上。
第一个大坑,数据丢失”的风险,这种基于偏移量OFFSET(也就是命令里的10, 20这些数字)的分页方式,在数据动态变化的场景下非常不可靠,想象一下这个场景:你正在看排行榜第一页,这时有个玩家的积分突然暴涨,一条新数据插入了集合的顶部,然后你点击了“第二页”,会发生什么?由于新数据挤占了顶部的位置,原来在第一页末尾的那条数据,就被挤到第二页的开头了,而原来在第二页开头的一条数据,就被挤到第三页去了,这样,你在第二页就会看到一条本来在第一页看过的数据,也永远地丢失了原本应该出现在第二页的某条数据(因为它被挤到更后面,你可能没机会翻到了),这就是典型的“数据漂移”问题,导致分页结果不准,用户体验很糟糕。

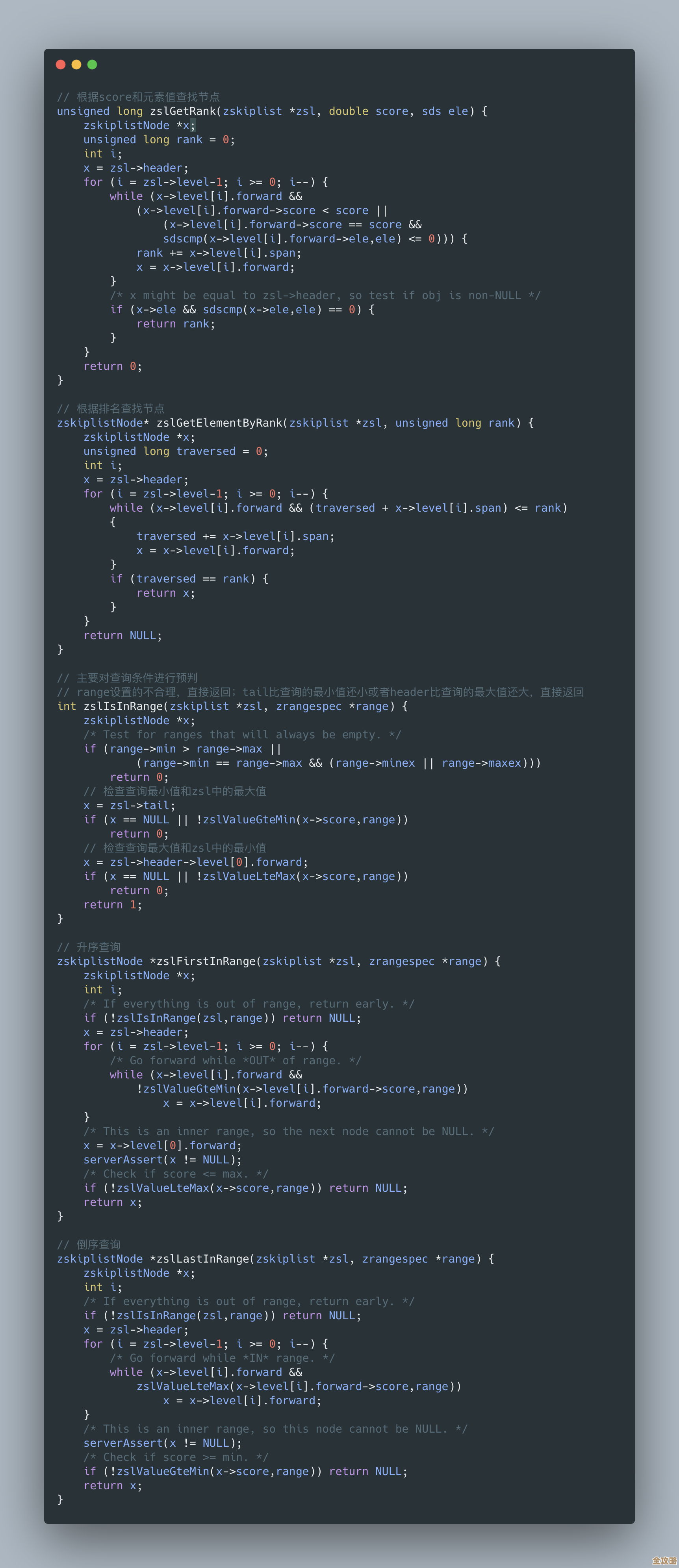
怎么解决这个“丢数据”的问题呢?业界一个非常有效且流行的办法,就是放弃使用偏移量OFFSET,转而使用“游标”或者叫“锚点”的方式,就是不用ZREVRANGE key (page-1)*size size这种写法了,而是用ZREVRANGEBYSCORE命令,它的原理是:当你获取第一页数据后,记录下本页最后一条数据的分数(比如是last_score)和唯一标识(比如成员ID),当你要获取下一页时,不是简单地跳过固定的条数,而是查询分数小于(如果是倒序排列)last_score的接下来的N条数据,命令大概是ZREVRANGEBYSCORE key (last_score ( -inf LIMIT 1 size,这里的(last_score表示分数小于last_score(开区间,避免重复包含最后一条),这样就完美地绕开了因为顶部插入新数据而导致的数据漂移问题,无论前面的数据怎么增删改,你总是能准确地接上上一页的尾巴,保证数据既不重复也不丢失。
解决了数据准确性的问题,接下来要面对的就是“卡顿”或者说性能问题,有人可能会想,我的数据量有上百万条,这个有序集合会不会把Redis撑爆?或者查询速度变慢?这里有几个要点。

Redis有序集合的底层实现是跳跃表和哈希表的结合,它按照分数范围查询(也就是我们用的ZREVRANGEBYSCORE)的时间复杂度是O(log(N) + M),其中N是总成员数,M是返回的成员数,这意味着,即使你的集合里有上亿条数据,根据分数范围查找固定数量(比如100条)的记录,速度也是极快的,基本是常数级别,不会因为数据量大而明显变慢,这本身就是Redis的优势。
不卡顿的前提是你的Redis实例资源配置要合理,如果你的有序集合非常大,占用了好几个GB的内存,那么你就要确保你的Redis服务器有足够的内存,并且最好禁用交换分区,避免发生内存交换导致性能骤降,要考虑数据的过期策略,对于有时效性的数据(比如7天的动态消息流),可以给整个有序集合设置过期时间,或者使用ZREMRANGEBYSCORE命令定期清理过期的低分数据,防止集合无限膨胀。
还有一个常见的性能陷阱是“大键”问题,如果你不仅把ID存入有序集合,还把每条数据的完整JSON内容都塞进去,那么这个“值”就会非常大,频繁操作大键会对Redis的网络IO和内存造成压力,最佳实践是:只在有序集合里存放用于排序的ID和分数,然后根据ID再去Redis的哈希表(Hash)或者字符串(String)键中批量获取(用MGET或HMGET,这种“二次查询”在Redis内部效率极高,远比直接操作一个巨大的有序集合要轻量得多,能有效避免卡顿。
别忘了极端情况的处理,用ZREVRANGEBYSCORE分页时,如果某一页的最后一条数据有多个成员分数完全相同,怎么办?这时仅凭分数无法确定唯一的位置,可能会漏掉数据,在记录游标时,除了分数last_score,最好连同该条数据的唯一ID(成员本身)一起记录,在查询下一页时,即使有同分情况,也能精确地从这个ID之后开始查询,确保万无一失。
用Redis有序集合做分页,要想数据不丢、页面不卡,关键就这几招:第一,用基于分数游标(ZREVRANGEBYSCORE)代替基于偏移量的分页,根治数据漂移;第二,采用“ID存ZSet,详情存Hash/String”的分离设计,避免大键,提升性能;第三,合理配置Redis资源,并设置数据清理策略;第四,处理同分情况,游标带上唯一ID,把这些事儿琢磨透了,你的Redis分页就能既快又稳。
本文由酒紫萱于2025-12-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/68268.html