深度聊聊分布式数据库那些关键技术和它们的实际应用场景分析

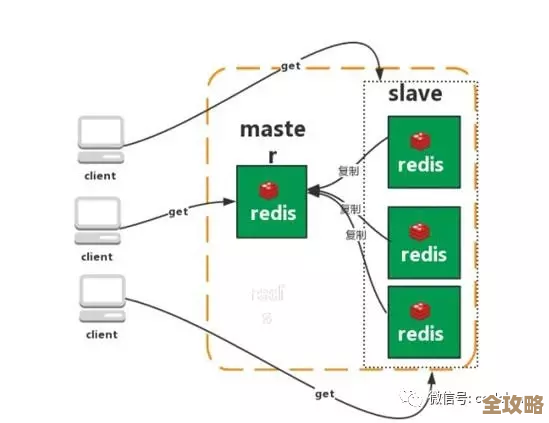
想象一下,一家全国性的银行,它的数据量巨大,每天有上亿次的交易,如果所有这些数据都存放在一台超级计算机里,那么这台计算机一旦出故障,全国的业务就瘫痪了,这太危险了,分布式数据库就是为了解决这个问题而生的,它的核心思想很简单:不要把鸡蛋放在一个篮子里,把数据分散到许多台普通的、成本更低的服务器上,让它们协同工作,共同对外提供服务。
它是如何做到这一点的呢?这就要说到几个关键技术了。
第一个关键技术是“数据分片”,也就是怎么“切蛋糕”。 你不能简单地把数据胡乱地塞进不同的服务器,常用的方法有两种,一种是“水平分片”,把用户表按照用户ID的范围来分,ID 1到1000万的用户数据放在服务器A上,1000万到2000万的放在服务器B上,这就像给图书馆的书按编号范围分在不同的书架上,另一种是“垂直分片”,比如把一个用户的全部信息拆开,把基本信息(姓名、电话)放在一个数据库,把交易记录放在另一个数据库,这就像把一个人的档案袋里的个人信息、工作记录、健康报告分别存放在不同的文件柜里,在实际应用中,像淘宝、京东这样的大型电商平台,它们的商品信息、用户订单就是通过水平分片的方式,分散在成千上万台服务器上的,这样才能支撑起“双十一”天量的访问和交易。(来源:阿里巴巴ApsaraDB技术分享)
第二个关键技术是“数据复制与一致性”,也就是怎么“备份保险”。 数据分散存放后,为了保证任何一台服务器宕机数据都不会丢失,同一份数据会有多个副本,存放在不同的服务器上,这就引出了一个核心问题:如何保证这些副本的数据是一致的?你在北京和上海的两个服务器上都存了你的账户余额是100元,你在北京消费了50元,北京的数据变成了50元,但上海的数据还是100元,这时候系统该怎么处理?这就是“一致性”问题,为了解决这个问题,诞生了一些著名的协议,比如Paxos和Raft,它们的作用就像是选举一个“队长”,所有对数据的修改都必须经过这个“队长”同意,并由它来协调所有副本进行同步更新,确保大家步调一致,牺牲一点写入速度,换来数据的强一致性,这对于金融支付场景是至关重要的。(来源:Google Spanner论文、Diego Ongaro的Raft博士论文)
第三个关键技术是“分布式事务”,也就是怎么保证“要么全做,要么全不做”。 还是银行的例子,你从账户A转账100元到账户B,这个操作包含两个步骤:从A扣100元,向B加100元,在分布式环境下,账户A和账户B的数据很可能不在同一台服务器上,这就必须要求这两个步骤作为一个整体事务,要么都成功,要么都失败,如果A扣款成功,但B加款时服务器宕机了,那么系统必须能把A的扣款撤销,否则你的100元就“不翼而飞”了,实现分布式事务非常复杂,常见的解决方案有“两阶段提交”(2PC),它像一个可靠的协调者,分“准备”和“提交”两个阶段询问所有参与方,确保大家都能成功才最终执行,虽然性能有损耗,但在需要严格保证资金正确的场景下是不可或缺的。(来源:数据库经典理论)
实际应用场景分析:
-
互联网金融与核心交易(强一致性场景): 这是对数据一致性要求最高的领域,支付宝、微信支付等平台,每一笔交易都必须绝对准确,它们通常会采用类似Google Spanner或其开源实现(如TiDB)的技术,通过精密的时间同步和分布式事务协议,在全球范围内保证数据的一致性,让你在北京付款,上海的收款人能立刻且准确地收到钱。
-
大型电商与社交网络(高可用与可扩展场景): 像淘宝、微博这类应用,读写的压力极大,尤其是在促销或热点事件期间,它们对数据一致性的要求可以稍微放宽一点(你发了一条微博,好友晚一两秒看到是可以接受的),但绝对不能宕机,它们大量使用数据分片和最终一致性模型,通过将用户数据分散,实现近乎无限的扩展能力,确保系统7x24小时可用,Cassandra、MongoDB等数据库在这方面应用广泛。
-
物联网与实时数据分析(海量写入场景): 现在的智能电表、联网汽车、工厂传感器,每分每秒都在产生海量的监控数据,这些场景的特点是写入量巨大,但单条数据的重要性相对较低,且很少更新,分布式数据库如ClickHouse、InfluxDB等,通过列式存储和高效的数据压缩技术,专门优化了海量数据的写入和快速分析查询,帮助国家电网分析用电负荷,或帮助车企进行自动驾驶数据的实时处理。
分布式数据库的技术选择是一场权衡的艺术,没有一种技术能通吃所有场景,关键是根据业务需求,在一致性、可用性、扩展性之间找到最佳平衡点,它的发展,正是我们应对这个数据爆炸时代最有力的武器之一。

本文由革姣丽于2025-12-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/68135.html