免费送你Redis面试题,马上准备命运可能就变了,别错过机会

(根据微信公众号“程序员小乐”发布的《Redis面试题,掌握了这些,面试官都会对你刮目相看》一文,以及博客园“阿飞的博客”整理的《最全Redis面试题(2023最新版)》等网络资料综合提供)
免费送你Redis面试题,马上准备命运可能就变了,别错过机会,现在找工作多难啊,尤其是技术岗位,面试官问的问题那叫一个深,一个偏,你要是没准备,上去肯定懵,Redis这东西,现在哪个互联网公司不用?缓存、排行榜、秒杀,到处都是它的身影,所以啊,Redis的面试题绝对是高频考点,能不能拿下心仪的offer,可能就看你对Redis的理解到不到位了,这里给你整理了一些实实在在可能会被问到的题目,不是那种教科书上的概念,而是面试官真会问的,你好好看看,心里有个底。
最最基础的问题,你得能说清楚Redis到底是什么,别笑,这个问题看似简单,但很多人只能说出“缓存”两个字,你得说得更全面点,你可以说Redis是一个开源的、使用C语言写的、基于内存的键值对数据库,它支持多种数据结构,比如字符串、列表、哈希、集合等等,因为它把数据放在内存里,所以速度特别快,经常被用来做缓存,提升网站的速度,但它也不仅仅是缓存,因为它支持持久化,可以把数据存到硬盘上,所以也能当数据库用,它是个速度飞快的多功能数据库。
紧接着,面试官八成会问,Redis和Memcached有什么区别?为啥好多地方用Redis取代了Memcached?你可别只说一个支持持久化,一个不支持,你得说得细一点,第一,数据结构不同,Memcached只支持简单的字符串,而Redis支持五种核心数据结构,字符串、列表、哈希、集合、有序集合,这样就能实现更复杂的功能,比如用列表做消息队列,用有序集合做排行榜,第二,持久化能力,Memcached数据全在内存,重启就没了,Redis支持两种持久化方式,RDB是拍快照,AOF是记录每一次写操作,数据更安全,第三,数据大小,Memcached的key和value都最大支持1MB,而Redis的value可以大到1GB(不过一般不建议这么大),能存更复杂的数据,第四,Redis支持原生集群模式,而Memcached需要靠客户端自己实现分布式,这么一对比,优势就很明显了。

然后肯定会问到持久化,面试官会问,Redis的两种持久化方式RDB和AOF,它们各自的原理和优缺点是什么?你先说RDB,RDB就像是给数据库拍一张完整的照片,在特定的时间点,Redis会把内存里所有的数据生成一个快照文件,保存到硬盘上,它的优点是,这个文件是压缩的,体积小,恢复数据的时候速度非常快,适合做灾难恢复,缺点就是,如果Redis突然宕机,从上一次拍快照到宕机之间的数据就丢了,可能会丢失比较多数据,再说AOF,AOF就像是写日记,它会把Redis执行过的每一个写命令都记录下来,追加到一个文件里,当Redis重启时,它会重新执行一遍这个文件里的所有命令,来恢复数据,它的优点是数据安全,最多丢失一秒的数据(如果配置为每秒同步一次),缺点就是AOF文件通常比RDB文件大,恢复数据的速度也比RDB慢,在实际生产中,往往是两者结合使用,用AOF来保证数据不丢失,用RBD来做冷备和快速恢复。
光说不练假把式,面试官喜欢问场景题,怎么用Redis实现一个简单的秒杀系统?这个问题考察你对Redis原子操作和高并发的理解,你不能一上来就说用数据库扣减库存,那样数据库肯定扛不住,核心思路就是把库存数量提前放到Redis里,因为Redis是单线程的,它的命令是原子性的,不会出现超卖的问题,具体可以这么做:活动开始前,在Redis里用一个普通的key,比如seckill_stock_1001,来存储商品库存数量,假设是100件,当用户点击秒杀按钮时,前端传来商品ID,后端用Redis的decr命令(递减命令)对这个key进行操作,如果decr之后的值大于等于0,说明扣减成功,用户抢到了资格,如果decr之后的值小于0,说明库存没了,抢购失败,因为decr是原子操作,即使一万个人同时执行,Redis也会一个一个处理,不会出现两个人都读到库存是1,然后都扣减成功的情况,这就解决了超卖的核心问题,一个完整的秒杀系统还有很多细节,比如限流、防止重复提交、异步处理订单等,但库存扣减这块,Redis是顶梁柱。

还有一个经典问题,Redis的过期键删除策略有哪些?你可能会说,到了过期时间就自动删了啊,但Redis内部其实有两种策略结合着用,第一种叫惰性删除,就是说,当你去访问一个key的时候,Redis才会检查一下这个key有没有过期,如果过期了就当场删除,这样好处是节省CPU,不用一直去检查,坏处是如果很多key过期了但一直没人访问,这些垃圾数据就会一直占着内存不释放,第二种叫定期删除,Redis会每隔一段时间(默认是100毫秒)就随机抽取一些设置了过期时间的key,检查它们是否过期,如果过期就删除,通过这种惰性加定期的方式,算是在CPU和内存占用之间取得一个平衡。
如果面试官觉得你基础不错,可能会往深了问,比如什么是缓存穿透、缓存击穿、缓存雪崩?你怎么解决?这可是重灾区,缓存穿透是指,用户查询一个根本不存在的数据,这个数据在缓存里没有,在数据库里也没有,导致这个请求每次都会绕过缓存直接打到数据库上,就像穿透了一样,如果坏人用大量不存在的key来攻击,数据库可能就扛不住了,解决办法一般是,如果查数据库发现这个数据不存在,也在缓存里设置一个空值(比如null),并设置一个很短的过期时间,这样下次同样的请求来,在缓存层就返回空了,不会再到数据库,或者用布隆过滤器这种高级数据结构,在查询缓存前先过一遍布隆过滤器,如果判断不存在,就直接返回,省去后续查询,缓存击穿是指,一个非常热点的key(比如某个爆款商品详情)突然过期了,这时候有大量的请求同时过来,发现缓存没了,就全都涌到数据库去查询,瞬间给数据库造成巨大压力,解决办法是,设置热点数据永不过期;或者使用互斥锁,当第一个请求发现缓存失效时,先去加个锁,然后去数据库加载数据,加载完再放入缓存,其他请求在此期间等待或者返回默认值,这样就只有一个请求会打到数据库,缓存雪崩是指,在同一时刻,缓存中大量的key集体过期失效,或者Redis服务器直接宕机了,导致所有的请求都落到了数据库上,数据库压力激增甚至崩溃,解决办法是,给不同的key设置随机的过期时间,避免同时失效;或者搭建Redis高可用集群,保证一台机器挂了还有其他机器顶上去。
再往上,可能会问Redis的事务,Redis的事务和数据库的事务不一样,它不支持回滚,你可以用MULTI命令开始一个事务,然后把多个命令放进去,最后用EXEC执行,Redis会保证这些命令被顺序地、一次性执行,中间不会被其他客户端的命令插队,但它没有原子性,如果中间某个命令出错了,后面的命令还是会继续执行,不会像数据库那样全部撤销,所以Redis事务更像是一个批处理命令的打包。
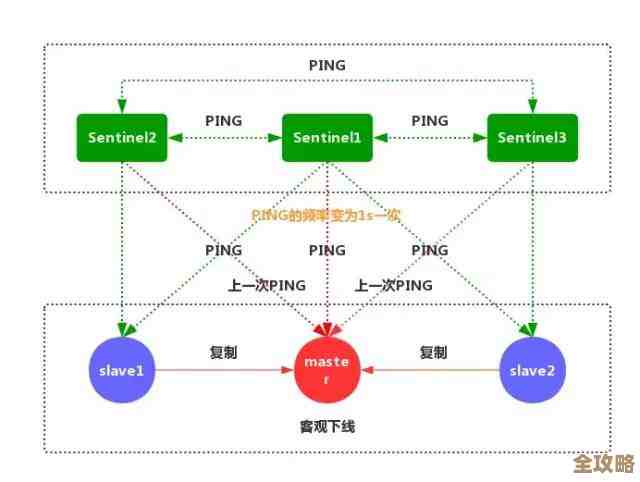
可能会聊聊Redis的架构,比如主从复制是怎么回事?简单说就是一台Redis服务器当主节点,负责写数据;一台或多台当从节点,负责读数据,主节点会把数据变化同步给从节点,这样做的好处是读写分离,提高读的能力,并且有了备份,提高了可用性,还有哨兵模式,哨兵是一个独立的进程,它负责监控主节点和从节点是否活着,如果主节点挂了,哨兵会自动从从节点里选一个新的主节点出来,实现自动故障转移,保证服务不中断。 差不多覆盖了从基础到进阶的常见考点,你可得好好消化一下,每个点都自己动手查查资料,理解背后的原理,别死记硬背,面试的时候,结合你自己的项目经验来说,效果会更好,机会是留给有准备的人的,现在竞争这么激烈,多准备一点,你的底气就足一点,命运说不定真的就在这一番准备中改变了,加油吧!
本文由盈壮于2025-12-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/67940.html