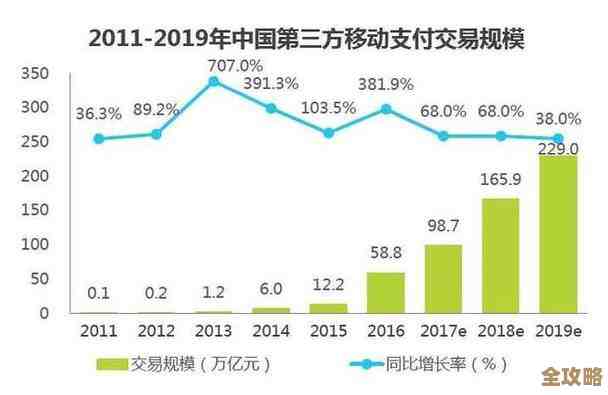
Redis到底能不能扛住那么多潮流和潮汐数据的疯狂发送量呢?

要回答Redis能不能扛住,我们不能简单地说“能”或“不能”,这就像问“一辆跑车能不能赢下所有比赛?”一样,答案取决于比赛的类型、赛道的情况、车手的水平以及后勤保障,Redis就是那辆性能极强的跑车,但把它用在什么地方、怎么用,才是决定它能否“扛住”的关键。

我们必须承认Redis的“天生神力”,它的核心优势就是“快”,快得惊人,这种快主要源于两点:第一,它把所有数据都放在内存里,内存的读写速度是硬盘的成千上万倍,这就避免了传统数据库磁盘I/O的瓶颈,第二,它的设计非常简洁,专注于键值存储,没有复杂的关系型数据模型和查询语言,这使得它的操作非常直接和高效,在面对“疯狂发送量”,也就是极高的并发请求时,这种简洁和高效变成了巨大的优势,很多大型互联网公司,比如微博、Twitter(根据其技术博客分享,他们使用Redis来处理时间线和个人信息)、GitHub(用于特定场景的缓存和队列)等,都在用Redis应对海量流量,这本身就证明了它具备处理高并发的能力。

“潮流和潮汐数据”这个说法点出了另一个关键挑战:数据的波动性,潮流是相对稳定的热点,比如一个热门话题的讨论数据;潮汐则是剧烈的、忽高忽低的流量,比如电商秒杀、明星官宣导致服务器瞬间被挤爆的场景,Redis能否扛住,就看我们如何应对这两种情况。

对于“潮流”——持续的高热度数据,Redis的应对策略主要是“扩展”。 单个Redis实例的能力是有上限的,它受限于单台服务器的内存大小和CPU处理能力,当数据量或请求量超过单个实例的极限时,我们就不能硬扛,必须“叫帮手”,Redis提供了成熟的主从复制(Replication) 和分片(Sharding) 技术,主从复制好比给主数据库找了多个备份和帮手(从库),读写分离,读请求可以分散到多个从库上,大大减轻主库的压力,而分片则是更彻底的解决方案,它把巨大的数据集拆分成很多小块,分布到多个Redis实例上,每个实例只负责一部分数据,这样,无论是存储容量还是处理能力,都实现了水平扩展,通过这两种方式,Redis理论上可以应对几乎任何规模的“潮流”数据。
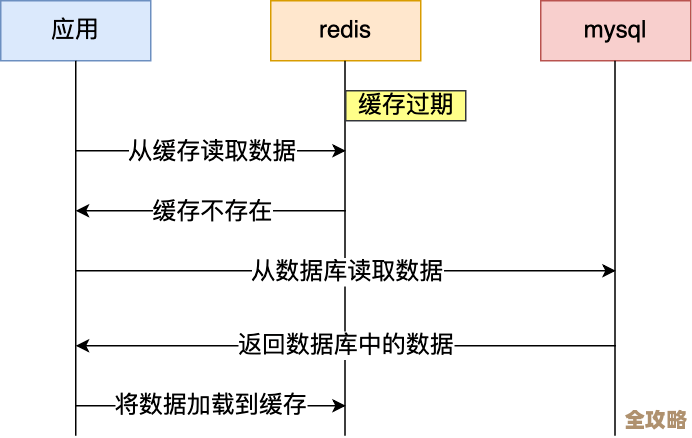
对于“潮汐”——瞬间的流量洪峰,这才是真正的考验。 秒杀开始时,每秒可能有数十万甚至上百万的请求涌来,要抢购寥寥无几的商品,这时,Redis的“快”是基础,但光靠快还不够,如果这百万请求都直接去读写数据库里的商品库存,Redis也可能被压垮,这里的核心策略不是硬碰硬,而是“缓冲”和“过滤”。
- 单线程模型的优势:很多人担心Redis是单线程处理命令,会不会成为瓶颈,恰恰相反,在应对潮汐流量时,单线程避免了多线程的上下文切换和锁竞争开销,使得CPU不用在管理线程上浪费时间,可以更专注、可预测地处理请求,保证了操作的原子性和顺序性,这在秒杀扣减库存时至关重要,能有效防止超卖。
- 前置过滤:在实际业务中,我们不会让所有请求都落到Redis上,通常会在更前面设置网关层或使用消息队列,对请求进行预处理和削峰填谷,先验证用户身份、过滤掉重复请求,然后把有效的请求平滑地送入后续处理环节,避免洪水直接冲击Redis。
- 精巧的数据结构和逻辑设计:以秒杀为例,我们不会简单地用
get/set操作库存,可能会利用Redis的原子操作,如DECR(原子递减),或者使用Lua脚本将多个操作封装成一个原子命令,确保在高并发下库存扣减的准确性,可以提前将秒杀商品库存加载到Redis中,并将用户ID、验证码等信息也存入,整个秒杀逻辑在Redis内存完成,速度极快。
Redis的软肋在哪里?什么情况下它可能“扛不住”?
- 内存限制与成本:所有数据都在内存,而内存比硬盘贵得多,如果数据量极其庞大(例如PB级别),且都是冷数据(不常访问),全用Redis成本会非常高,这时可能需要分层存储,热点数据放Redis,冷数据放传统数据库。
- 持久化瓶颈:虽然Redis有RDB快照和AOF日志两种持久化方式来保证数据不丢失,但在数据疯狂写入时,频繁做快照或写AOF日志会产生额外开销,如果配置不当,可能影响性能甚至阻塞服务,这需要根据业务对数据安全性的要求进行精细调整。
- 不当的使用方式:这是最常见的“扛不住”的原因,使用了
KEYS *这种阻塞式的命令,在大数据量下会直接导致服务暂停;或者没有设置合理的内存淘汰策略,导致内存爆满;再或者数据结构设计不合理,一个Key下面存了一个巨大的List或Hash,操作起来效率低下。
结论是: Redis本身是一柄应对高并发、潮汐流量的“神兵利器”,它的高性能和丰富的数据结构为解决问题提供了坚实的基础,它不是一个“一键解决”的方案,它能否扛住疯狂发送量,更大程度上取决于架构师和开发者如何运用它,通过合理的架构设计(如分片、集群)、精心的业务逻辑优化(如原子操作、Lua脚本)、以及前置的流量治理(如削峰填谷),Redis完全有能力成为扛住流量洪峰的中流砥柱,反之,如果只是简单部署、粗暴使用,那么再强大的工具也可能在潮水般的请求面前败下阵来,问题不在于Redis行不行,而在于我们能不能把它用对、用好。
本文由寇乐童于2025-12-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/67869.html