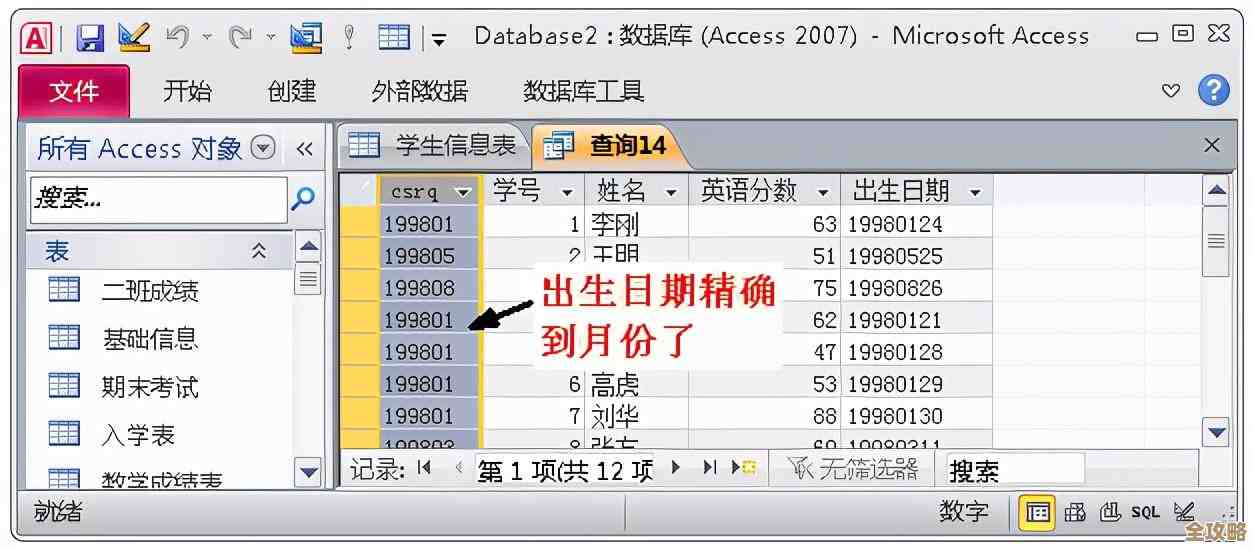
数据库更新维护时卡在Restricting状态,数据库一直显示Restring没动静

根据甲骨文技术支持文档(Oracle Support Document)中关于数据库启动阶段的知识,当数据库卡在“RESTRICTING”状态且长时间没有动静时,这通常意味着数据库实例已经启动,但在进入打开阶段之前,在某个内部检查或准备步骤上遇到了阻碍,这个状态本身表示数据库正处于受限会话模式下启动,但问题在于它无法顺利完成启动流程。
这种情况的发生,往往不是由一个单一的原因造成的,而是由一系列潜在问题触发的,根据甲骨文社区(Oracle Community)中多位专家用户分享的实际案例和经验,最常见的原因可以归结为以下几大类。
也是可能性较高的一种情况,是资源耗尽或系统瓶颈,数据库在启动过程中需要申请和分配大量的内存(特别是SGA,即系统全局区)以及其他系统资源,如果操作系统当前可用的物理内存不足,或者某些内核参数(如信号量、共享内存段的大小和数量限制)设置得不合理,数据库进程就可能因为申请不到足够的资源而陷入等待,从外部看就是卡住不动,存储系统出现性能问题,比如磁盘I/O速度极其缓慢,甚至出现暂时性的挂起,也会导致数据库在读取必要的系统文件(如控制文件、数据文件头)时被阻塞。
与控制文件相关的问题也极为常见,控制文件是数据库的“大脑”,记录了数据库的物理结构,在启动的某个阶段,数据库需要同步并验证所有控制文件的副本,如果某个控制文件损坏、丢失,或者由于权限问题(例如Oracle软件用户没有读取权限)而无法访问,启动进程就会停在那里,尝试反复读取或等待恢复,从而表现为“RESTRICTING”状态,同样,如果控制文件中记录的数据文件信息与实际不符,比如记录了一个不存在的数据文件,数据库也会在此步骤上停下来,等待管理员干预。
第三,复杂的恢复过程也可能导致启动缓慢,看起来像是卡住,特别是数据库非正常关闭(如服务器断电)后再次启动时,会自动进行实例恢复,如果崩溃前有大量未提交的事务需要回滚,或者需要应用大量的重做日志(Redo Log)进行前滚,这个恢复过程可能会持续很长时间,在此期间,数据库会处于一种类似“RESTRICTING”的状态(实际上可能更具体地显示为正在进行恢复),从用户角度看就是没有响应,如果重做日志文件本身损坏或丢失,恢复过程更是会直接中断,导致启动挂起。
第四,一些内部的竞争或等待事件也可能是元凶,根据甲骨文技术支持文档的一些晦涩案例,极少数情况下,数据库可能会在启动过程中陷入一种罕见的“死锁”或等待某个特定的内部闩锁(Latch)或互斥锁(Mutex),这通常与软件本身的Bug有关,某个后台进程在启动序列中需要获取一个资源,而该资源由于某种原因一直被另一个进程或自身以异常方式持有,从而导致整个启动链条被冻结,这类问题通常需要结合具体的错误跟踪文件(Trace File)和甲骨文支持提供的补丁来解决。
第五,不能忽视的是集群环境下的特殊问题,如果数据库是运行在Oracle RAC(实时应用集群)环境中,那么实例启动时还需要与集群中的其他节点进行通信和协调,如果集群软件(Oracle Clusterware)本身存在問題,或者节点之间的网络通信出现故障,实例也可能在“RESTRICTING”状态等待集群服务的响应,从而表现为挂起。
当面对这种情况时,数据库管理员不能简单地反复重启数据库,而是需要像侦探一样,一步步排查线索,首要的行动是检查数据库的警报日志文件(Alert Log),这个文件是数据库运行和诊断信息最详细的记录者,数据库在启动的每个阶段,都会在警报日志中留下记录,通过查看警报日志最后打印的几条信息,通常就能精确定位到数据库卡在了哪个具体的操作上,如果最后一条信息是“控制文件识别号不一致”,那么问题就指向控制文件;如果是“等待检查点完成”,则可能与恢复过程有关。
在操作系统层面,可以使用诸如ps -ef | grep ora_(在Linux/Unix上)这样的命令来查看Oracle后台进程的状态,如果发现大多数后台进程(如DBWn, LGWR, SMON, PMON等)已经启动,但某个关键进程状态异常或频繁重启,这也是一条重要的线索,使用top或iostat等系统监控工具,观察服务器的CPU、内存和I/O使用情况,可以判断是否存在资源瓶颈。
数据库启动时卡在“RESTRICTING”状态是一个需要认真对待的信号,它背后隐藏的原因多种多样,从简单的资源不足、文件权限错误,到复杂的恢复问题乃至软件缺陷都有可能,解决问题的关键在于耐心和细致的日志分析,通过警报日志这条最主要的线索,结合对系统资源的检查,逐步缩小范围,最终找到并解决根本原因。

本文由召安青于2025-12-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/67172.html