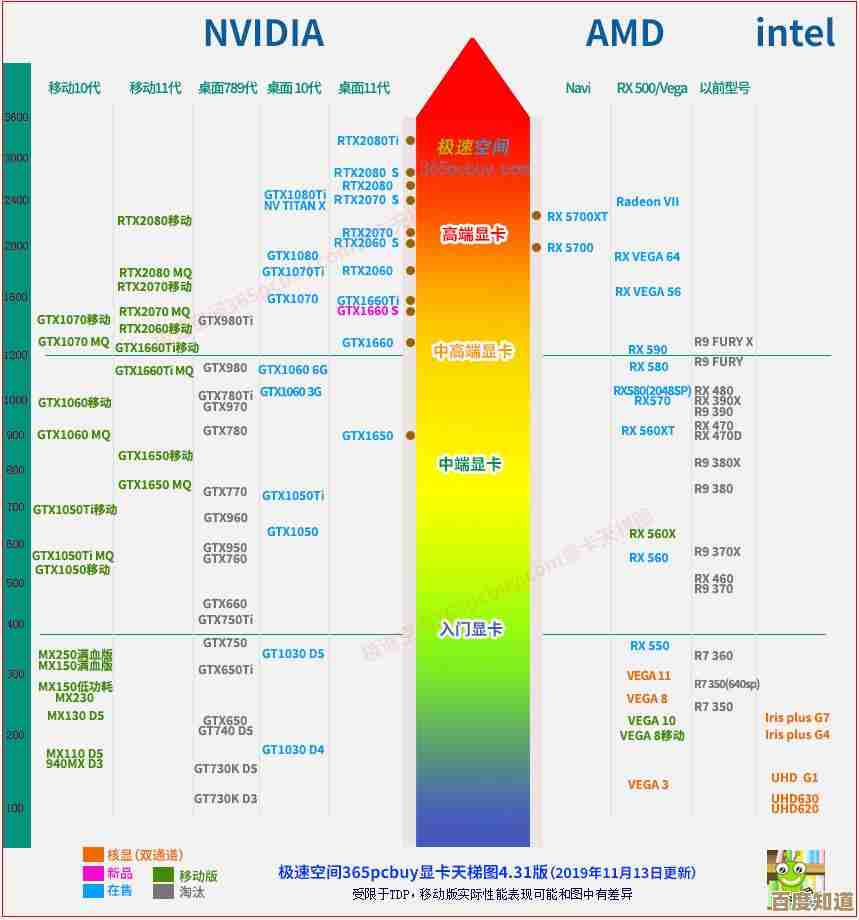
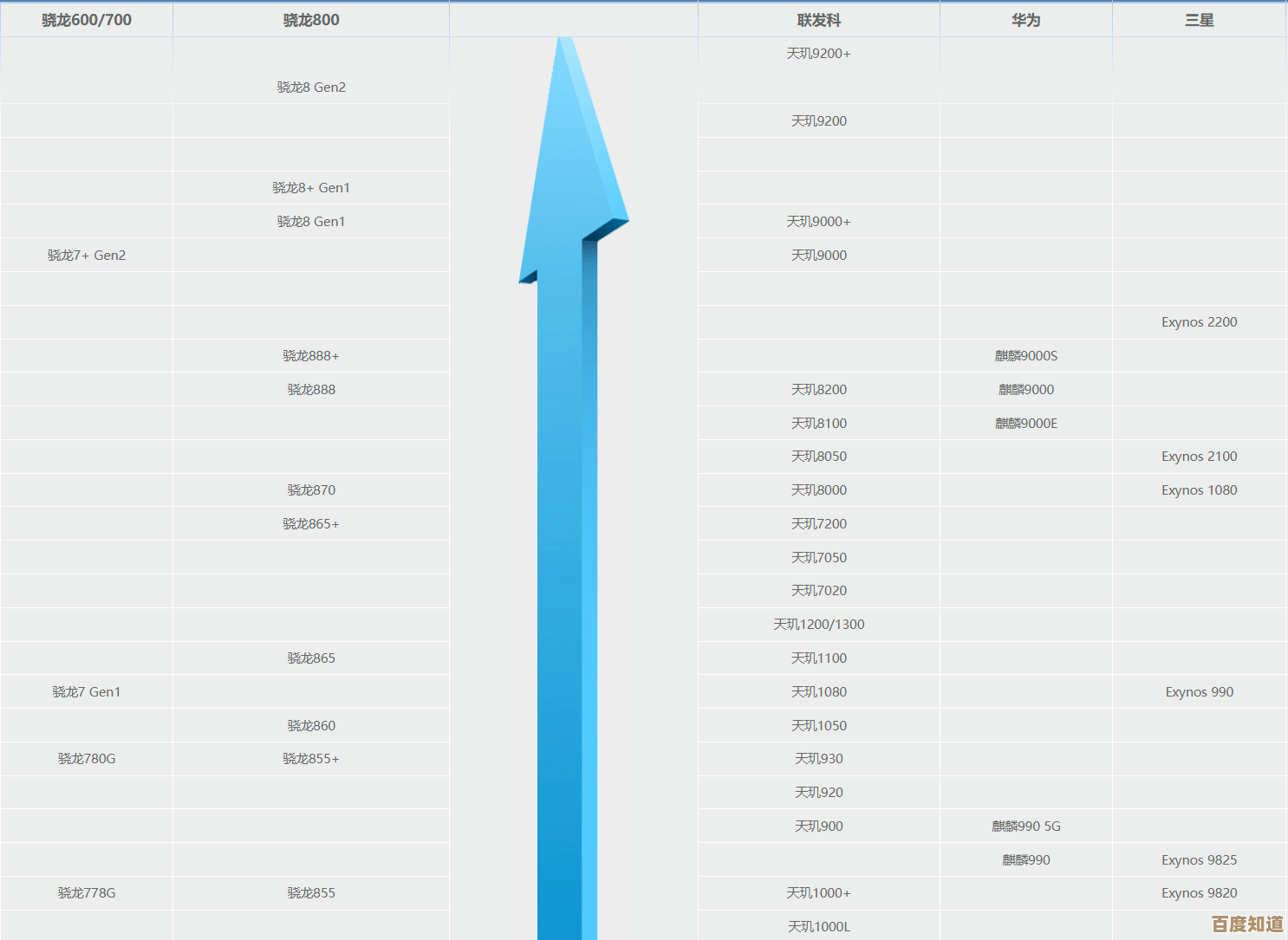
探索移动GPU天梯图:如何通过创新架构提升图形渲染效率与用户体验

哎,说到移动GPU这个事,我总觉得有点…怎么说呢,像在观察一场静悄悄的革命,你手里那块亮晶晶的玻璃板,能流畅跑着开放世界游戏、实时渲染炫酷滤镜,背后全是这家伙在默默燃烧,但看那些天梯图,一排排芯片名字加上冷冰冰的分数,总感觉隔着一层什么,好像…少了点人味儿?它只告诉你谁跑得快,却没告诉你为什么这个“运动员”的跑步姿势如此特别,甚至有点怪异,但就是能省力又出活。
我记得第一次拆解一颗老旧手机芯片,看到GPU那块区域时,心里咯噔一下,它就那么小小一点,跟CPU挤在一起,像个不起眼的附属品,那时候的想法特幼稚:这么个小不点,凭什么扛起整个世界的色彩?后来才明白,移动GPU的进化史,压根不是PC显卡那种“大力出奇迹”的暴力堆料史,而是一部在方寸之间绞尽脑汁的“生存智慧”史,功耗和发热就像两道紧箍咒,逼着架构师们去搞各种“歪门邪道”的创新,他们不能简单地把桌面GPU缩小,那等于把一台V8发动机塞进小轿车,跑是能跑,但油箱瞬间见底,车子也烫得能煎蛋,移动GPU的天梯图排名,与其说是性能的直线赛跑,不如说是一场综合性的“能效体操赛”,平衡、技巧、巧劲才是关键。

就拿那个…嗯…Tile-Based Deferred Rendering(TBDR)架构来说吧,这名字拗口得像个法律条款,但 idea 其实特别有生活气息,传统的即时渲染,GPU像个豪放的画家,接到指令就对着整块画布(也就是你的屏幕)猛涂猛画,不管画布上哪些部分最终会被前景挡住,这太浪费了嘛!移动GPU的TBDR架构则像个精打细算的工匠,它先不急着动笔,而是把画布分成一小块一小块的瓷砖(Tile),然后像个侦探一样,先分析整个场景,找出每块瓷砖里哪些像素是最终能被人眼看到的,哪些是被前面物体挡住的“无用功”,分析完了,它只对那些真正需要着色的像素下笔,这就像…你收拾房间,TBDR不会把每个角落的灰尘都扫一遍,而是先看清楚家具摆放,只打扫那些露出来的地板,这种“延迟”和“分块”的思路,极大地减少了不必要的计算量,对功耗敏感的手机来说,简直是雪中送炭,你看,这不是单纯的算力强,是脑子好使。
还有那个统一着色器架构(Unified Shader Architecture),听着高大上,其实也挺有意思,早先的GPU,顶点着色器和像素着色器是各千各的,像工厂里两条独立的生产线,忙闲不均,一条线堆满了活,另一条可能在那儿闲着吹风,统一架构就把这帮“工人”都变成了多面手,哪里任务紧就去哪里帮忙,这种灵活性,让GPU的资源利用率大大提高,避免了“旱的旱死,涝的涝死”,这种设计哲学,是不是有点像我们应对多任务工作时的状态?不再死守一个岗位,而是随时切换,保持整体效率最高,调度起来也更复杂了,对驱动和开发者的要求也高了,但…这就是进步的代价吧。

说到细节,我特别喜欢琢磨那些芯片大厂在架构上玩出的小花招,他们会给GPU加入一些专用的硬件单元,专门处理特定的任务,像什么AI超分(用AI脑补更高清的画面)、光线追踪(模拟真实光线效果),这些单元不大,但极其专注,就像给团队请来了一个超级专业的顾问,碰到它擅长的问题,效率飙升,但有时候我也会想,这种“打补丁”式的创新,会不会让架构变得越来越复杂,像一件打满补丁的衣服,虽然还能穿,但终究不如一件设计时就考虑周全的新衣来得优雅?这大概就是工程上的权衡艺术了,没有完美方案,只有当下最适合的取舍。
用户体验这东西,说起来很虚,但感知又特别实在,架构的创新,最终要落到你指尖的流畅感上,更好的能效意味着更长的续航,你可以多玩两局游戏而不用到处找充电宝;更高效的渲染意味着更稳定的帧率,在团战时不会突然卡成PPT,那种挫败感真的能让人摔手机,还有发热控制,谁也不喜欢捧着一个暖手宝讲电话吧?这些细微之处,才是移动GPU天梯图背后,真正和我们发生关联的故事,分数高一分,可能就意味着你多了一次畅快的游戏体验,或者一次关键时刻的从容。
下次再看移动GPU天梯图,或许可以多想想它背后的那些巧思与挣扎,那不仅仅是一串数字,更是一群工程师在功耗、面积、性能这个“不可能三角”里,努力画出最美妙图形的奋斗史,它不完美,充满了妥协,但正是这些不完美,让每一次微小的提升都显得如此珍贵,这玩意儿…真挺迷人的,对吧?就像在微观世界里,见证一场关于效率与美的无声竞赛。
本文由寇乐童于2025-10-22发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/yxdt/36359.html

![[yy下载]v1.0.0新版发布:高速下载通道,畅享高清影音游戏盛宴](http://www.haoid.cn/zb_users/upload/2025/10/20251022023258176107157880347.jpg)