Redis集群遇到单台机器挂了,怎么快速应急处理和恢复方案分享

当Redis集群中单台机器突然挂掉,其实不用太慌,这事儿有套路可循,咱们就按“先保服务,再修数据,最后恢复机器”的步骤来,下面说的很多思路,其实在Redis官方文档的集群教程和故障恢复部分,以及像阿里云、腾讯云这些大厂的技术博客里,都反复提到过,咱们把它揉碎了说。
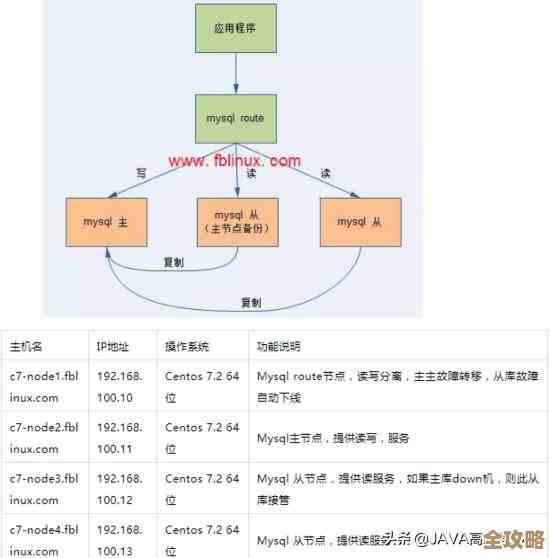
第一步:紧急止血,确保服务还能用 机器一挂,最先要搞清楚它影响了啥,Redis集群通常把数据分片放在不同的主节点上,每个主节点可能还有一两个从节点跟着,如果挂的是个从节点,那问题不大,客户端可能感觉不到,因为读请求可能去了别的从节点或者主节点,但如果挂的是个主节点,那就麻烦了,它负责的那部分数据就暂时写不进去了。
这时候,集群自己会尝试“做主从切换”,根据Redis官方文档的说明,如果这个主节点有从节点,而且从节点数据比较新,集群会主动把这个从节点“提拔”成新的主节点,让它接手工作,这个过程通常是自动的,但需要一点时间(几十秒),你的首要任务就是快速确认自动切换是否成功,可以用redis-cli --cluster check命令,或者直接通过集群管理工具(比如你用的云平台控制台)看看那个出问题的分片是不是已经有了新的主节点在干活,如果服务看起来基本正常,只是有少量错误,那可能切换正在进行中,等一会儿就好。
如果自动切换没发生(比如这个主节点没有从节点,或者从节点也一起挂了),那就得手动干预,立刻从剩下的从节点里,选一个数据最新的,手动把它变成主节点,命令是redis-cli --cluster failover,但需要指定节点,这个操作要快,目的是让这个分片尽快恢复写入能力,别让业务一直报错。
第二步:处理可能的数据“小尾巴” 新主节点上位后,最让人担心的是数据有没有丢,因为主从复制是异步的,老主节点挂掉前,可能有一部分最新数据还没同步给从节点,根据很多公司的实战经验(比如知乎的一些技术分享里提到过),这时候要先评估一下数据的重要性,如果这部分数据非常关键,而挂掉的那台机器硬盘没坏,那首要任务就是别动那块硬盘,考虑后续把数据捞出来,如果数据允许少量丢失(比如缓存场景),那就可以继续下一步,先保证服务。
要立刻调整客户端的连接和告警,告诉客户端应用,故障发生了,可能有点波动,检查一下客户端的重试机制是不是正常,别因为一直连不上老节点而卡死,把监控告警的关注点,从“掉线”转移到“新主节点是否正常服务”上。
第三步:把挂掉的机器拉回来,恢复完整阵容 服务稳定之后,就该处理那台挂掉的机器了,把它修好(比如重启、换硬件、或者如果是云服务器就重建一个),然后重新加入到集群里。
这里有个关键点,根据Redis集群的设计,这台机器回来时,它上面的旧数据可能已经过时了(因为新主节点已经产生了新数据)。不能直接把它当主节点加回去,标准的做法是,让它作为一个全新的从节点,重新加入集群,去同步现在新主节点上的全部数据,命令大概是redis-cli --cluster add-node,然后把它设置为某个节点的从节点,这样,数据会在后台安静地同步,不影响集群当前服务。
等它数据同步完成了,集群就恢复了完整的主从结构,抗风险能力又回来了,这时候,你可以根据原来的规划,考虑是否要重新调整一下主从关系,让集群的布局更合理。
一定要“吃一堑长一智” 事处理完了,报告也得写,重点记录:故障怎么发现的、自动切换生效没、手动操作了啥、数据丢了没(丢了多少)、恢复了多久,然后根据这个,想想怎么改进:是不是监控不够快?是不是某些分片没有从节点,成了单点?是不是日常的集群健康检查没做到位?把这些改进措施落实了,下次再遇到,就能更从容。
核心就是:自动切换优先,手动干预要快;先保服务可用,再管数据完整;恢复机器时,老老实实当学徒重新同步数据,多练几次,这套流程就熟了。

本文由邝冷亦于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/85300.html