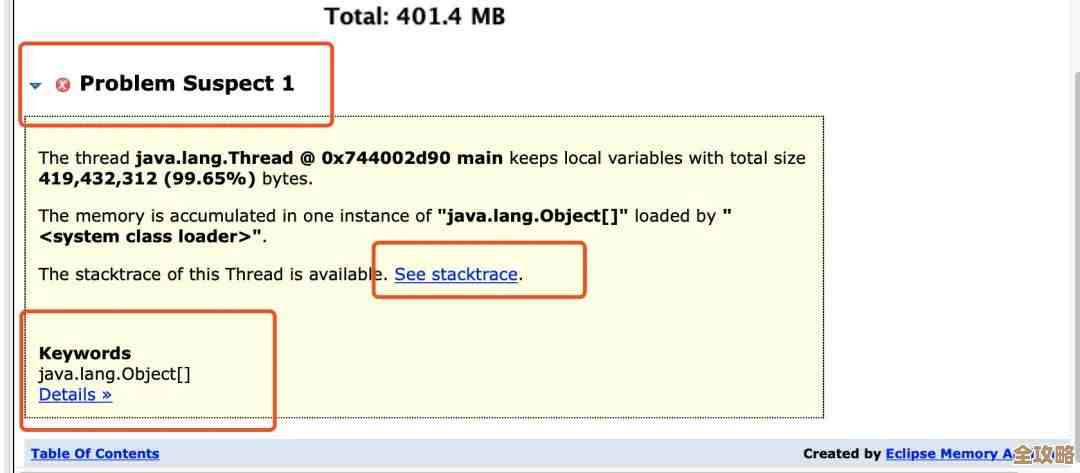
数据库里那个UUID到底是啥,为什么大家都说它重要又常用?

主要综合自维基百科“通用唯一识别码”词条、Stack Overflow上关于数据库主键的讨论、以及多个技术博客如Martin Fowler关于分布式系统设计的观点)
咱们现在就来聊聊这个数据库里神神秘秘的UUID,你可能经常听程序员们提起它,说它重要、常用,尤其是在设计数据库表的时候,它到底是个啥?为啥大家这么推崇它?
简单粗暴地说,UUID就是一串全球唯一的身份证号码,只不过这个身份证是发给你数据库里每一条记录的,它的全称是“通用唯一识别码”(Universally Unique Identifier),你想象一下,全世界有那么多电脑,那么多数据库,每时每刻都在创建新数据,UUID的目标就是确保你生成的这个号码,在其他任何地方、由其他任何人、在任何时间生成的号码都不会重复,这个目标非常宏大,所以它也被叫做GUID(全局唯一标识符),基本上可以把它俩当成一回事。
那它长什么样呢?它不是我们常见的1,2,3,4……这种简单的数字序列,它是一长串由数字和字母(A-F)组成的代码,看起来有点吓人,比如这样:f47ac10b-58cc-4372-a567-0e02b2c3d479,这串字符被连字符分成了五段,总共是128位(由32个十六进制字符表示),你别被它的样子唬住,它的核心思想就两个字:唯一。
现在我们来重点说说,为什么它在数据库领域这么重要和常用,这主要得归功于它的几个关键特性,这些特性解决了传统主键的一些大麻烦。
第一个大好处,也是最重要的:分布式生成,全局唯一。
在以前,我们给数据库记录设置主键,最常用的方法是让数据库自己管理一个自增的数字,比如ID字段,第一条记录是1,下一条自动就是2,以此类推,这个方法在单一数据库里很好用,但一旦业务变复杂,问题就来了。
想象一下,你的公司做大了,一个数据库服务器扛不住这么大的访问量了,怎么办?很常见的做法是搞“分库分表”,或者用多个数据库实例同时工作(也就是分布式系统),这时候,如果还用自增ID,就乱套了,数据库A刚生成了一个ID 100,数据库B不知道,它也生成了一个ID 100,当把这两个数据库的数据合并到一起时,就会出现两条ID完全一样的记录,这就产生了严重的冲突,系统就崩溃了。
而UUID完美地解决了这个问题,因为UUID的生成不依赖中央数据库服务器,世界上任何一台独立的计算机,都可以在自己本地,不需要和任何其他机器商量,就生成一个几乎可以保证全球唯一的ID,这样,数据库A生成的UUID和数据库B生成的UUID,哪怕是在同一毫秒生成的,也几乎不可能是相同的,这就使得在分布式环境下,安全地创建数据变得异常简单和可靠,极大地提高了系统的扩展性和 robustness(鲁棒性,或者说健壮性)。

第二个大好处:可以在客户端生成,提高效率。
这个好处是上一个好处的延伸,在Web开发或者移动应用开发中,经常有这种场景:用户在手机上填写一个表单,点击“提交”之前,应用可能就需要先创建一个本地对象,如果使用自增ID,这个ID必须等到数据真正被发送到服务器、插入数据库之后,才能由数据库返回给客户端。
但用UUID呢?应用可以在用户刚打开表单的时候,就在手机本地生成一个UUID,并立刻赋予这个新对象,之后,无论是本地暂存,还是最终提交到服务器,这个ID从一开始就确定了,这样做有几个优势:
- 减少网络往返:不需要等待服务器返回ID,操作更流畅。
- 简化事务:如果创建一条记录需要同时创建多条与之关联的记录(比如订单和订单明细),在客户端预先知道所有记录的ID,会让关联操作变得非常简单。
- 离线工作:即使设备暂时没有网络,也能正常创建数据并赋予ID,等有网了再同步到服务器,不会出现ID冲突。
第三个好处:安全性考虑。
虽然这不是主要目的,但UUID有时能提供一层轻微的安全屏障,如果你的数据库表使用自增整数作为主键,比如用户ID,那么坏人很容易就能猜到:ID 1001存在,那1002、1003肯定也存在,他就可以简单地通过递增数字来尝试访问(或攻击)其他用户的资料,这叫做“顺序枚举攻击”。

而UUID是随机的、没有规律的,坏人无法从一个已知的UUID推测出下一个或上一个UUID是什么,这使得通过直接猜测ID来非法访问数据的难度大大增加,这不能替代真正的权限验证,但算是一个有益的副作用。
UUID也不是完美的,它也有明显的缺点。
最常被吐槽的就是占用空间大,一个UUID是128位,也就是16个字节,而一个普通的自增整数(BIGINT)是8个字节,UUID是它的两倍大,当数据量达到亿级甚至更高时,这额外的存储开销是不能忽视的。
性能问题,因为UUID是随机生成的,它不像自增ID那样是连续的,当UUID作为数据库索引(特别是主键索引,通常是聚簇索引)时,新插入的随机UUID可能会被安插在索引树的中间某个位置,导致需要频繁地进行页分裂和重新排序,这会降低插入性能,并可能导致索引碎片化,相比之下,自增ID总是追加在索引的末尾,操作非常高效,数据库专家们也想了办法来缓解,比如有些数据库支持“时序UUID”,或者通过调整索引策略来优化。
数据库里的UUID就是一个为了在分布式世界里确保“唯一性”而生的超级身份证,它的核心价值在于“去中心化生成”和“全局唯一”,这让它成为了构建可扩展的、分布式的现代应用程序的基石技术之一,虽然它在存储空间和插入性能上有些代价,但在很多需要灵活、安全、独立生成标识符的场景下,它的优势是无可替代的,这就是为什么它如此重要和常用的根本原因。
本文由召安青于2026-01-21发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/84104.html