Redis到底要几台服务器才够用,怎么优化才能发挥最大性能呢?

关于Redis到底需要几台服务器才能满足需求,以及如何优化才能发挥其最大性能,这是一个非常实际的问题,答案并不是一个固定的数字,而是完全取决于你的具体业务场景、数据量、读写压力以及对数据可靠性的要求,我们可以从几个不同的应用规模来探讨这个问题,并给出相应的优化思路。
对于小型应用或个人学习项目,一台Redis服务器通常就足够了,这种情况下,数据量可能不大,比如只是用来做简单的缓存,存储一些用户会话(Session),或者作为消息队列处理一些简单的后台任务,来源自Redis官方文档和许多开发者的实践经验都指出,单机Redis在配置得当的情况下,性能已经非常强劲,可以轻松应对每秒数万甚至十万次的请求,优化的重点应该放在合理设置内存上限和淘汰策略上,如果你的内存是8GB,可以设置Redis最大使用6GB,并选择allkeys-lru这样的淘汰策略,当内存不足时自动淘汰最近最少使用的数据,防止内存爆满导致服务崩溃,确保不要运行任何耗时的命令,比如在生产环境使用KEYS *,这可能会导致服务短暂卡顿。
对于中型或大型应用,面临高并发读写或海量数据存储时,单台服务器就会遇到瓶颈,瓶颈主要来自两个方面:一是单台机器的内存容量有限,无法存放所有数据;二是单台机器的处理能力(CPU、网络带宽)有上限,无法承受超高的并发请求,这时,就必须采用多台服务器组成的集群方案,Redis本身提供了成熟的集群方案,也就是Redis Cluster,来源自Redis作者的观点以及大规模互联网公司的实践,Redis Cluster通过将数据分片(Sharding)分布到多个节点上,实现了数据的水平扩展,你可以用三台主服务器(Master)和三台从服务器(Slave)组成一个集群,将数据分成16384个槽位(slot)分配到三台主节点上,这样,存储容量和读写性能理论上就变成了三倍,当需要更大容量或更高性能时,只需要向集群中添加新的节点即可,在这种架构下,优化的关键在于合理规划分片策略和保证集群的高可用性,要避免某个分片的数据过热(即某个节点承受了绝大部分请求),每个主节点都配备从节点,当主节点宕机时,从节点能够自动升级为主节点,保证服务不中断。
对于读写比例严重失衡的场景,比如读请求远远多于写请求,另一种多服务器架构——主从复制(Replication)就非常有用,来源自常见的架构设计模式,你可以部署一主多从的结构,所有写操作只发生在主服务器上,然后主服务器将数据变更异步地同步给多个从服务器,所有的读操作则可以分散到各个从服务器上去执行,这样做的好处是极大地提升了系统的读吞吐量,减轻了主服务器的压力,此时的优化点在于监控主从复制的延迟,因为异步复制的关系,从服务器上的数据可能会比主服务器稍有延迟,对于一致性要求不高的场景可以接受,但要求强一致性的读操作还是需要去主服务器上执行。
除了架构层面的扩展,单台Redis服务器的性能优化也至关重要,无论你用的是单机还是集群,以下几点是通用的优化建议,来源自Redis性能调优的最佳实践:
- 尽可能使用物理机而非虚拟机:虚拟化层会带来一定的性能损耗,尤其是在网络I/O和内存访问上,物理机能提供更稳定、更极致的性能。
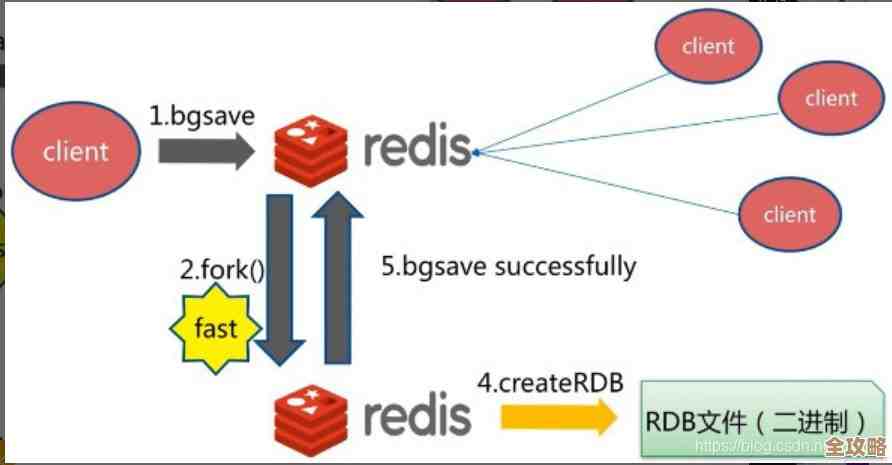
- 把数据持久化策略配置好:Redis主要有两种持久化方式:RDB快照和AOF日志,RDB是定时生成数据快照,恢复速度快,但可能会丢失几分钟的数据,AOF记录每一次写操作,数据安全性高,但文件会更大,恢复更慢,通常建议是同时开启RDB和AOF,用RDB做冷备,用AOF保证数据安全,可以调整AOF的刷盘策略为
everysec,在性能和数据安全间取得平衡。 - 使用连接池:避免频繁地创建和关闭Redis连接,使用连接池来复用连接,可以显著减少网络开销和提高响应速度。
- 使用Pipeline管道技术:当需要执行多个命令时,使用Pipeline将它们打包一次性发送给Redis,可以极大地减少网络往返时间(RTT),提升批量操作的效率。
- 避免使用大Key和热Key:单个Value过大的Key(比如一个包含百万元素的集合)在传输、持久化时都会很慢,容易引发问题,同样,某个Key被超高并发访问(热Key)可能会打爆单个服务器或分片,解决方法是将大Key拆解,对于热Key可以考虑在业务层做本地缓存或者拆分成多个Key。
Redis要几台服务器,需要从你的业务需求出发来判断,从单机起步,随着业务增长,逐步演进到主从复制或集群模式,而优化则是一个贯穿始终的过程,需要结合架构设计和细致的参数调优,才能让Redis发挥出最大的性能潜力。

本文由寇乐童于2026-01-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/83274.html